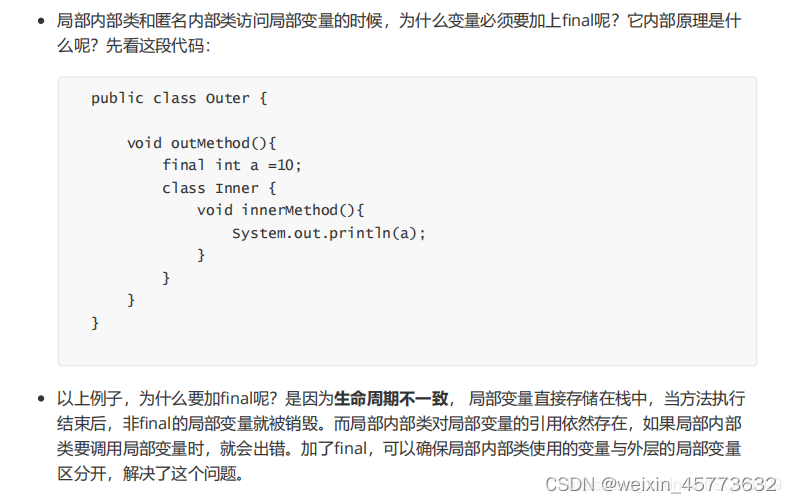
1. 项目背景
2009年的《当地法案84号》,或纽约市基准法案,要求对能源和用水量进行年度基准测试和披露信息。被覆盖的财产包括单个建筑物的税收地块,其总建筑面积大于50,000平方英尺(平方英尺),以及具有超过100,000平方英尺总建筑面积的多个建筑物的税收地块。从2018年开始,《纽约市基准法案》还将包括总面积大于25,000平方英尺的财产。
能源管理局的ENERGY STAR Portfolio Manager工具计算指标,建筑业主进行自我报告。数据的公开可用性使得建筑的绩效能够进行本地和全国比较,激励最精确的能源使用基准测试,并为能源管理决策提供信息。
2. 数据清洗与格式转换
这里的数据 NYC_Property_Energy.csv可私信给作者获取。
import warnings
# warning.filterwarnings('ignore')
import pandas as pd
import numpy as np
pd.set_option('display.max_columns', 60)
pd.options.mode.chained_assignment = None
# No warnings about setting value on copy of slice
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.size'] = 24
from IPython.core.pylabtools import figsize
import seaborn as sns
sns.set(font_scale = 2)
data = pd.read_csv('./data/NYC_Property_Energy.csv')
data.head()
代码解释:
import pandas as pd和import numpy as np导入 Pandas 和 NumPy 库。pd.set_option('display.max_columns', 60)设置 Pandas 显示的最大列数为 60。pd.options.mode.chained_assignment = None禁止对 Pandas 切片进行警告提示。import matplotlib.pyplot as plt导入 Matplotlib 库用于绘图。%matplotlib inline魔法命令将 Matplotlib 图表嵌入到 Jupyter Notebook 中。plt.rcParams['font.size'] = 24设置 Matplotlib 字体大小为 24。from IPython.core.pylabtools import figsize导入figsize函数,该函数可以在 Jupyter Notebook 中设置图表大小。import seaborn as sns导入 Seaborn 库用于绘图。sns.set(font_scale = 2)设置 Seaborn 图表字体比例为 2。
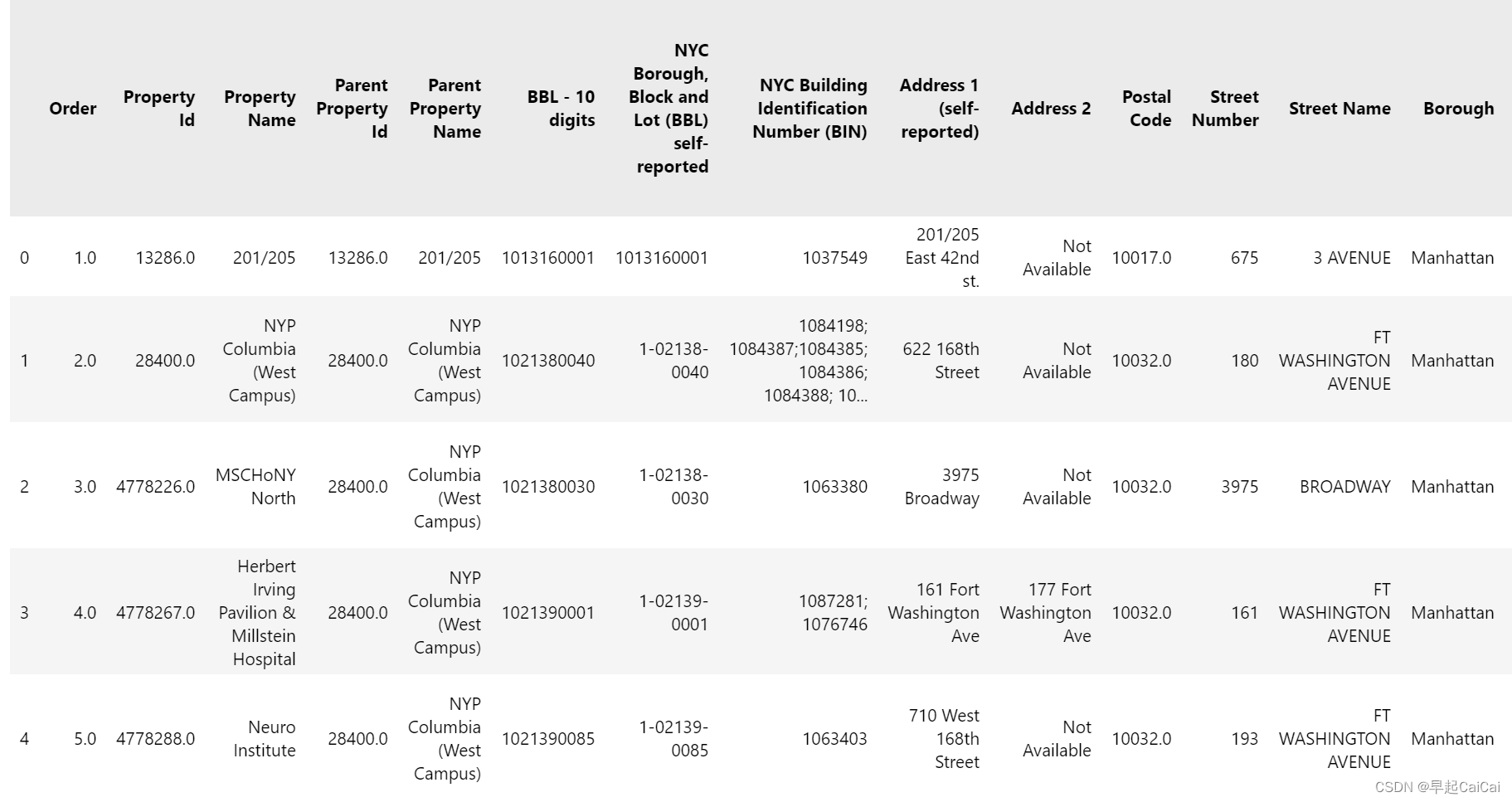
2.1 数据类型与缺失值
data.info()

data.info()是pandas库中的一个函数,用于查看DataFrame的信息,包括列名、非空值数量、每列数据类型等。具体信息如下:
RangeIndex: 表示数据集中行数范围,包括行数开始和结束值;Data columns (total x columns): 表示数据集中总共有多少列;Column Name: 列名;Non-Null Count: 非空值的数量;Dtype: 每列的数据类型,如int64、float64、object等。
将Not Available转换为np.nan,再将部分数值型数据转换成float
data = data.replace({'Not Available': np.nan})
for col in list(data.columns):
if ('ft²' in col or 'kBtu' in col or 'Metric Tons CO2e' in col or 'kWh' in
col or 'therms' in col or 'gal' in col or 'Score' in col):
data[col] = data[col].astype(float)
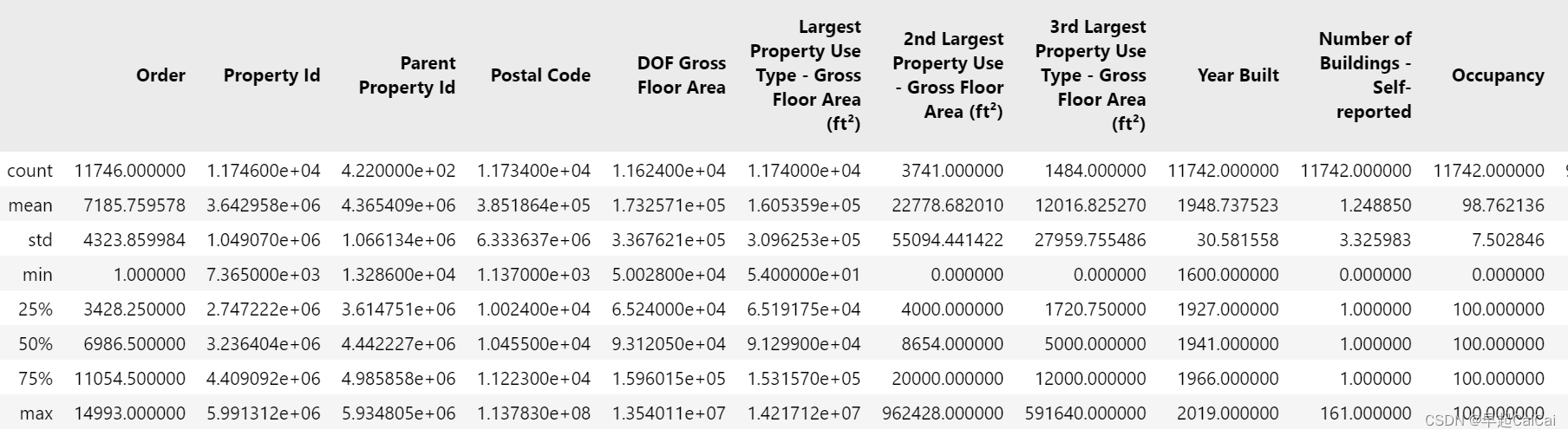
data.describe()
这段代码的作用是对数据进行清洗和转换数据类型,以便后续的分析和建模。
首先,将所有Not Available的值替换为缺失值(np.nan),这是为了确保数据的完整性和准确性。
然后,使用一个for循环遍历数据集中的每一列,如果这一列的名称包含特定的字符串(如“ft²”、“kBtu”、“Metric Tons CO2e”、“kWh”、“therms”、“gal”和“Score”等),则将该列的数据类型转换为浮点数,这是为了将这些列转换为数值类型,以便后续的数值计算。
最后,使用.describe()函数统计数据集中每一列的基本统计信息,如均值、标准差、最小值、最大值等,以便对数据进行初步的探索和了解。
2.2 缺失值处理
import missingno as msno
msno.matrix(data, figsize = (16, 5))
这段代码使用了 missingno 库来绘制缺失值的矩阵图。该图以矩阵的形式展示了数据集中每个变量的缺失值情况,如果某个变量在某一行中有缺失值,那么这个变量所在的格子会被标记为白色。

计算缺失值的比例:
def missing_values_table(df):
mis_val = df.isnull().sum() # 总缺失值
mis_val_percent = 100 * df.isnull().sum() / len(df) # 缺失值比例
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1) # 缺失值制成表格
mis_val_table_ren_columns = mis_val_table.rename(columns={0:'Missing Values', 1:'% of Total Values'})
mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:,1] != 0].sort_values('% of Total Values', ascending=False).round(1)
# 缺失值比例列由大到小排序
print('Your selected dataframe has {} columns.\nThere are {} columns that have missing values.'.format(df.shape[1], mis_val_table_ren_columns.shape[0]))
# 打印缺失值信息
return mis_val_table_ren_columns
missing_values_table(data)
这段代码定义了一个函数 missing_values_table(df),用于检测数据框中每一列的缺失值信息并返回一个缺失值信息表格。函数接收一个数据框作为参数。
具体来说,函数首先使用 df.isnull().sum() 计算出每一列的缺失值总数,使用 100 * df.isnull().sum() / len(df) 计算出每一列缺失值所占比例。然后将这两个计算结果拼接成一个表格,用 mis_val_table_ren_columns = mis_val_table.rename(columns={0:'Missing Values', 1:'% of Total Values'}) 重新命名列名,用 mis_val_table_ren_columns = mis_val_table_ren_columns[mis_val_table_ren_columns.iloc[:,1] != 0].sort_values('% of Total Values', ascending=False).round(1) 对缺失值比例列进行排序(由大到小),并且保留小数点后一位。最后打印输出数据框的列数和含有缺失值的列数,并且返回排序后的缺失值信息表格。
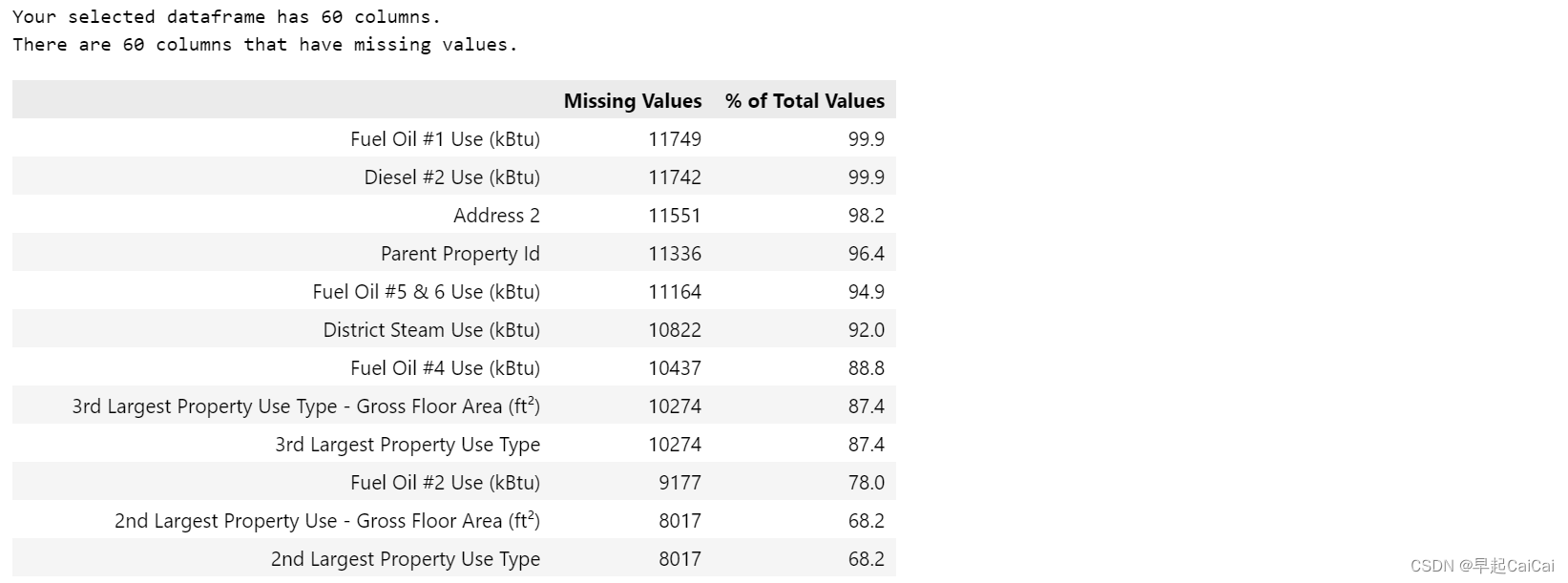
获取缺失值比例 > 50% 的列并移除
missing_df = missing_values_table(data)
missing_columns = list(missing_df[missing_df['% of Total Values'] > 50].index)
print('We will remove %d columns.' % len(missing_columns))

删除缺失值比例高于50%的列
data = data.drop(columns = list(missing_columns))
Reference
机器学习项目实战-能源利用率1-数据预处理