学习记录
学习记录
一、目标
aHR0cHM6Ly9waWMubmV0Ymlhbi5jb20vDQo=
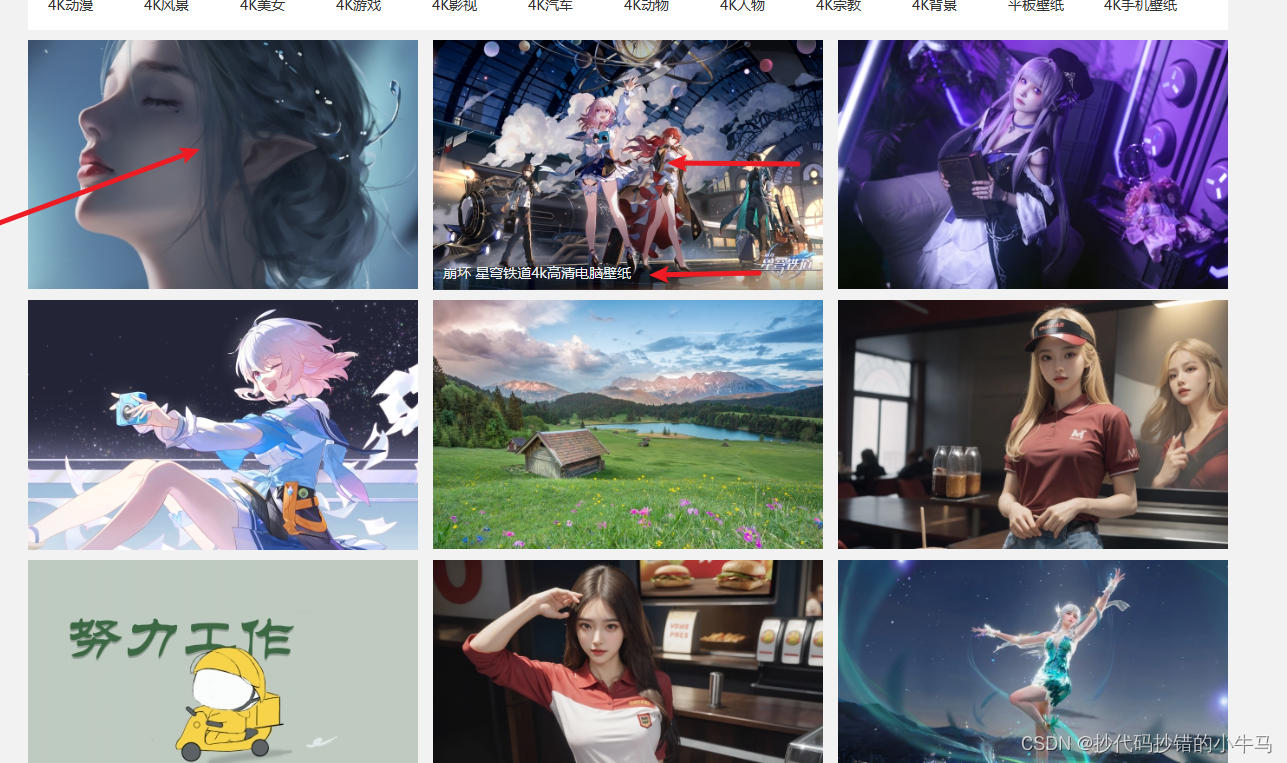
拿到每张图片的href 和 标题,跳转到详情页进行图片下载地址的提取并请求实现图片本地下载
二、代码实现
"""
CSDN: 抄代码抄错的小牛马
mailbox:yxhlhm2002@163.com
"""
import os
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
import requests
from lxml import etree
from userAgentPooL import userAgent
from ipPooL import IP
UA = userAgent.get_ua()
def get_data(url):
start = time.time()
futures = []
# 创建 20 个线程池 with as 不用手动关闭
with ThreadPoolExecutor(max_workers=20) as pool:
# with ProcessPoolExecutor(max_workers=20) as pool:
for i in url:
headers = {
'User-Agent': UA,
'Referer': 'https://www.igdcc.com/'
}
print(f'主页:{headers["User-Agent"]}')
proxies = IP.get_ip()
resp = requests.get(url=i, headers=headers, proxies=proxies)
print(resp)
resp.encoding = 'gbk'
content = resp.text
tree = etree.HTML(content)
li_list = tree.xpath('//div[@class="slist"]/ul[@class="clearfix"]/li')
for item in li_list:
headers = {
'User-Agent': UA,
'Referer': 'https://pic.netbian.com/'
}
href = 'https://pic.netbian.com/' + item.xpath('./a/@href')[0]
proxies = IP.get_ip()
img_HTML = requests.get(url=href, headers=headers, proxies=proxies)
img_HTML.encoding = 'gbk'
img_data = img_HTML.text
new_tree = etree.HTML(img_data)
src = 'https://pic.netbian.com/' + new_tree.xpath('//div[@class="photo-pic"]/a/img/@src')[0]
title = new_tree.xpath('//div[@class="view"]/div[2]/a/img/@alt')[0]
# 将耗时的任务放到线程池中来执行
f = pool.submit(download, src=src, title=title)
futures.append(f)
for f in futures:
f.result()
print('一共花费时间', time.time() - start)
def download(src, title):
img_content = requests.get(url=src).content
if not os.path.exists('./ThreadpicPool'):
os.mkdir('./ThreadpicPool')
with open('./ThreadpicPool/%s.jpg' % title, 'wb') as fp: # wb 是写入二进制的,图片是二进制。
fp.write(img_content)
print('{%s}下载成功!!!' % title)
pass
def main():
print('----------------彼岸图网壁纸采集----------------')
star_page = int(input('请输入起始页:'))
end_page = int(input('请终止起始页:'))
url = []
for page in range(star_page, end_page + 1):
if end_page == 1:
url.append('https://pic.netbian.com/index.html')
break
else:
if page == 1:
url.append('https://pic.netbian.com/index.html')
else:
url.append(f' https://pic.netbian.com/index_{page}.html')
get_data(url)
pass
if __name__ == '__main__':
main()
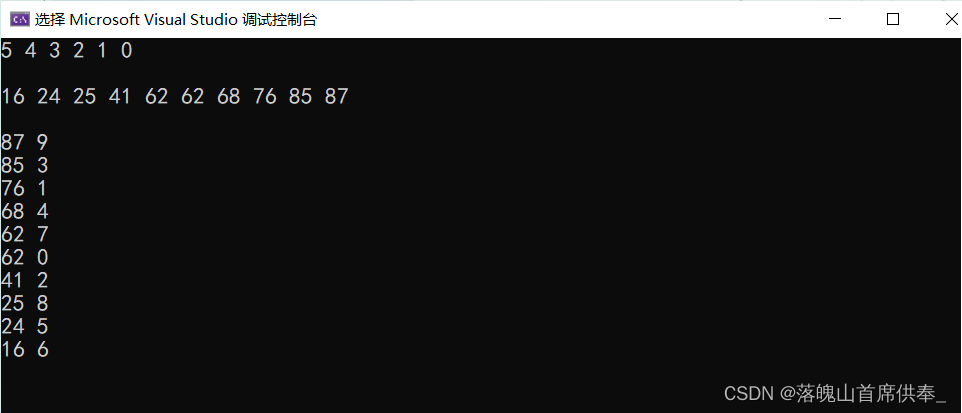
效果: