这里用到的代码是:
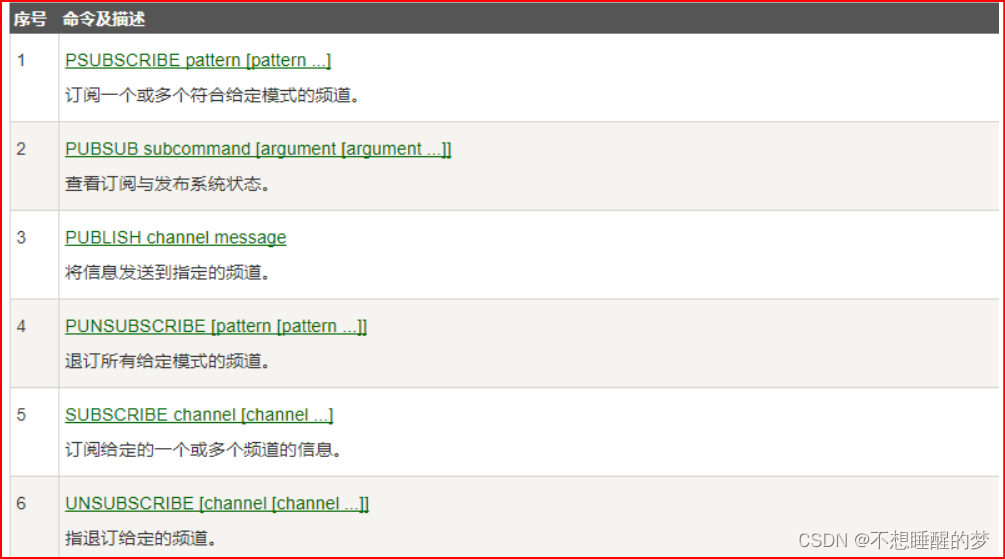
DeepLabV3源码讲解(Pytorch)_哔哩哔哩_bilibili
背景说明:自己做了一个数据集,已经训练完毕,一共7类零食,加背景算8类。
前面的代码省略了
model.eval() # 进入验证模式
with torch.no_grad():
# init model
img_height, img_width = img.shape[-2:]
print("img_height, img_width :", img_height, img_width)
init_img = torch.zeros((1, 3, img_height, img_width), device=device)
model(init_img)
t_start = time_synchronized()
output = model(img.to(device))
t_end = time_synchronized()
print("inference time: {}".format(t_end - t_start))
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
mask = Image.fromarray(prediction)
mask.putpalette(pallette)
mask.save("test_result.png")
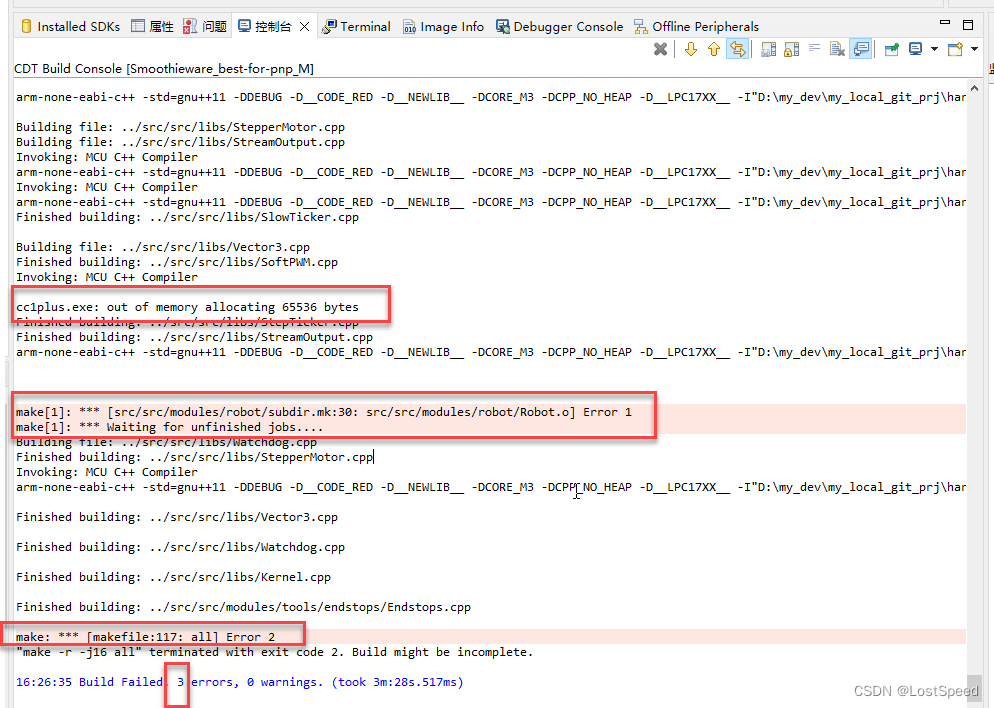
###############################################################################
#下面的代码是好奇心的产物
print("output['out'].type",type(output['out']))
print("output['out'].shape :", output['out'].shape) # 原始数据:torch.Size([1, 21, 520, 831]),自己数据集:output['out'].shape : torch.Size([1, 8, 1531, 520])
outt = output['out'].argmax(1) #argmax(1)得到的是索引
'''
print("output['out'].argmax(1).shape :",outt.shape) #output['out'].argmax(1).shape : torch.Size([1, 1467, 520])
outt = outt.cpu().numpy() # outt = outt.numpy() #TypeError: can't convert cuda:0 device type tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
#
这里是predict的代码,也就是预测部份。 输入图片是1467*520的 这里我想知道deeplab是怎么判断其类别的。(尽量不从网络结构和算法理论层次讨论,仅在代码层面) 从注释看到: output['out'].shape :([1, 8, 1467, 520]) 我们看到输入是1467*520,现在输出也是 1* 8 *(1467*520) 可以理解成1次判断, 有8张图片,每张图片是1467*520的 选择 argmax(1) 也就是 在8 这个维度的中括号去掉,然后比较元素 这里仅仅举个例子 (1467行*520列) [1,2,3,...] , [0,4,0,...] ,... (1467*520) [5,2,3,...] , [-1,4,8,...] ,... (1467*520) [1,2,3,...] , [-1,4,0,...] ,... (1467*520) [1,7,3,...] , [6,4,0,...] ,... (1467*520) [0,4,9,...] , [-1,6,9,...] ,... (1467*520) [1,2,3,...] , [-1,4,0,...] ,... (1467*520) [9,2,1,...] , [6,4,1,...] ,... (1467*520) [1,8,3,...] , [8,4,0,...] ,... 比较之后的结果是:[6,7,4,...],[3,4,4,...],... 单看第一列(1,5,1,1,0,1,9,1)中最大的数是9,在8维中的第6维(0-7) 也就是8个类别的序号,代表的是每个像素点最可能是哪个类别。
关于最后的预测结果,也可以输出出来看一下 (0是背景)

输出的代码如下:
prediction = output['out'].argmax(1).squeeze(0)
prediction = prediction.to("cpu").numpy().astype(np.uint8)
f = open("./result/pre.txt", "a+")
bb = prediction
for j in range(800):
for k in range(100,400):
bbb = str( round(bb[j][k],1) )
f.write(bbb +' ')
f.write("\n")
f.close()
mask = Image.fromarray(prediction)
mask.putpalette(pallette)因为txt一行输出的数字有限,所以我每行输出的是 第100个像素到第400个像素
有1467行,只输出前800行像素的类别
在txt中缩小看,中间空白是瓶子盖
下面是瓶身,颜色浅一点的是可乐的类别序号:1
颜色深一点的是背景序号:0