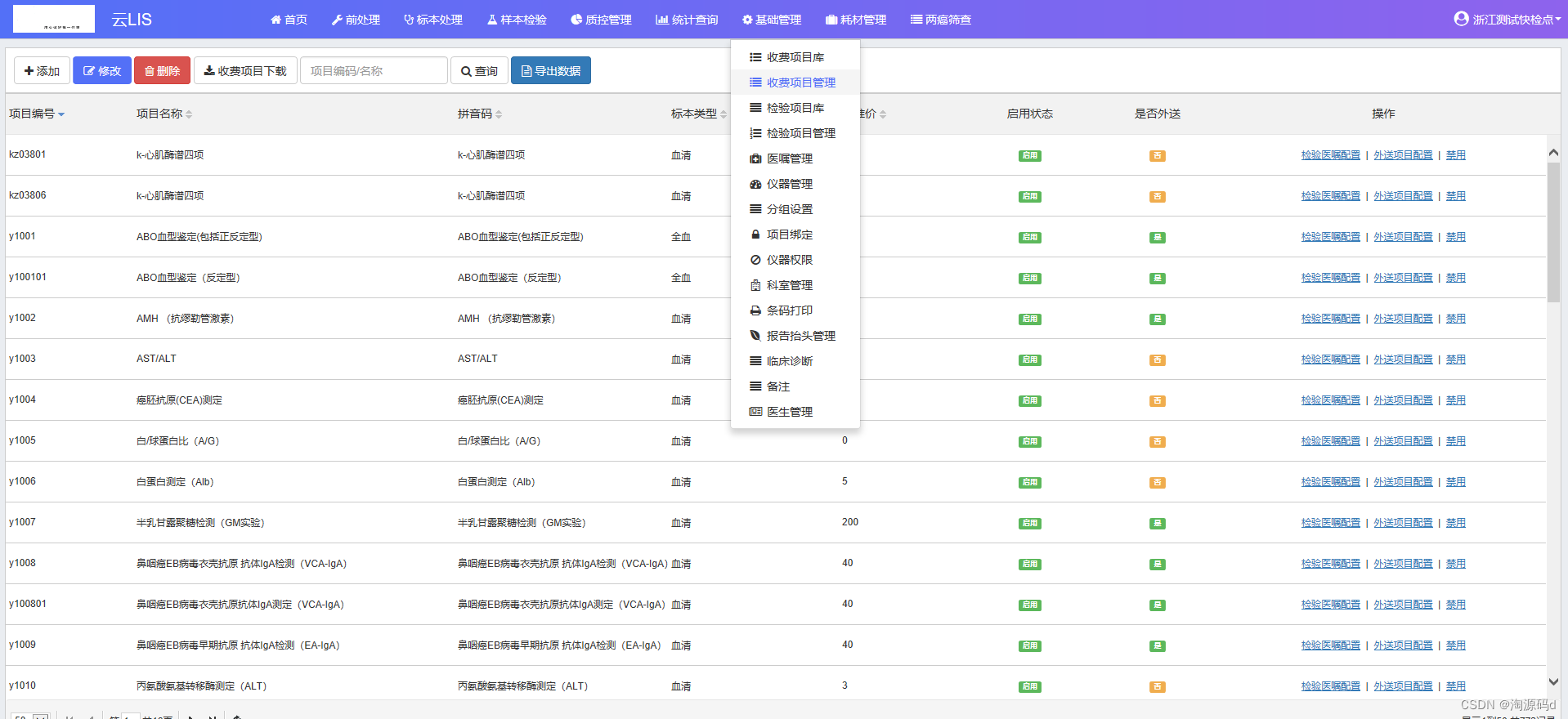
目录
1 requests.get(url) 的各种属性,也就是response的各种属性
2 下面进行测试
2.1 response.text
1.2 response.content.decode()
1.2.1 response.content.decode() 或者 response.content.decode("utf-8")
1.2.2 response.content.decode("GBK") 报错
1.2.3 关于编码知识
1.3 print(response.url)
1.4 print(response.status_code)
1.5 print(response.request.headers)
1.6 print(response.headers)
3 继续
1 requests.get(url) 的各种属性,也就是response的各种属性
- 接触的requests模块的常用功能:
- 一般把 response = requests.get(url)
requests.get(url)的各种属性
- print(response.text)
- print(response.content.decode()) # 注意这里!
- print(response.url) # 打印响应的url
- print(response.status_code) # 打印响应的状态码
- print(response.request.headers) # 打印响应对象的请求头
- print(response.headers) # 打印响应头
- print(response.request._cookies) # 打印请求携带的cookies
- print(response.cookies) # 打印响应中携带的cookies
2 下面进行测试

#E:\work\FangCloudV2\personal_space\2学习\python3\py3_test1.txt
import requests
url='https://baidu.com'
response=requests.get(url)
#print(response.text)
print(" ")
print(response.content.decode())
print(" ")
print(response.url)
print(" ")
print(response.status_code)
print(" ")
print(response.request.headers)
print(" ")
print(response.headers)
print(" ")
print(response.request._cookies)
print(" ")
print(response.cookies)
2.1 response.text
也就是 requests.get(url).text
- response.text 是 requests模块自动根据HTTP 头部对响应的编码作出有根据的推测,推测的文本编码
- 返回的类型是,str 类型
- 下面是print(response.text) 的结果
- 请求baidu.com 可以看到返回的,有一些是乱码
- 英文是对的,乱码是中文没有解析正确导致。

1.2 response.content.decode()
- 也就是 requests.get(url).content
- response.content 返回的内容,没有指定解码类型,需要解码
- 缺省默认的是 "utf-8"
- 返回的类型是,byte
1.2.1 response.content.decode() 或者 response.content.decode("utf-8")
- print(response.content.decode()) # 注意这里!
- 要选择合适的decode()
- 比如这里选择 decode("utf-8") 或者缺省默认也是 utf-8, 汉字显示就正常了不乱码了
- 如果解码选择了 "GBK" 就报错,不同地方需要注意
#E:\work\FangCloudV2\personal_space\2学习\python3\py3_test1.txt
import requests
url='https://baidu.com'
response=requests.get(url)
#print(response.text)
print(" ")
print(response.content.decode())

1.2.2 response.content.decode("GBK") 报错
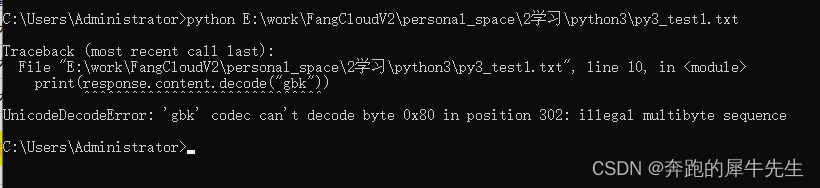
1.2.3 关于编码知识
- 如下,还没有整理完
| 编码方式: | 将计算机的二级制数据一一映射设到各种文字符号 | 编码字符集 | 二级制的不同数字---映射到某些文字符号的 对应集合/可查表/字典等 | |||
| 不同的子集 | ||||||
| ANSI编码 | 系统默认的编码方式 | 中文GBK,英文ASCII ,繁体中文big5 | ||||
| 也称MBCS | 不同操作系统下,对应不同的编码字符集 | |||||
| 一种ANSI码不能保存大于1种以上的语言文字 | ||||||
| unicode编码 | 讲世界上全部语言文字都保存在一种编码内 | Unicode字符集 | utf-8编码,有bom无BOM | utf-8 兼容 ascii | ||
| utf-16编码 | ||||||
| utf-32编码 | ||||||
| GBXXX编码 | 汉字编码 | GBXXX字符集 | GB2312-80 | 和ascii冲突 | ||
| GBK | 65536 | 2^16 | 双字节编码, (1个字节是8位2进制,2个字节是16位) 编码范围是0x8140~0xFEFE 共收录了21003个汉字,883个字符 | |||
| GB18030 | ||||||
| ascii 编码 | 美国的 | ascii 字符集 | 标准ascii 字符集 | 7位 | 2^7 | 128个字符 |
| 扩展ascii 字符集 | 8位 | 2^8 | 256个字符 | |||
| UCS-2, UCS-4 | UCS-通用字符集 | ISO | 双字节编码 | |||
| BIG5编码 | BIG5字符集 | 繁体汉字,感觉可以忘了这玩意 | ||||
| 源字符集编码 | ||||||
| 可执行字符集编码 | ||||||

1.3 response.url
- response.url

1.4 response.status_code
- 也就是 requests.get(url).status_code
- 返回的 状态码
| 200 | 成功 |
| 302 | 跳转,新的url在响应的Location头中给出 |
| 303 | 浏览器对于POST的响应进行重定向至新的url |
| 307 | 浏览器对于GET的响应重定向至新的url |
| 403 | 资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限) |
| 404 | 找不到该页面 |
| 500 | 服务器内部错误 |
| 503 | 服务器由于维护或者负载过重未能应答,在响应中可能可能会携带Retry-After响应头;有可能是因为爬虫频繁访问url,使服务器忽视爬虫的请求,最终返回503响应状态码 |
| 403 | 资源不可用;服务器理解客户的请求,但拒绝处理它(没有权限) |
插入知识:网页的基础跳出命令
- 网页上点右键,查看网页源代码---查看网页的html格式网页
- (F12也可以打开)网页上点右键,检查-----调出网页的控制台页面
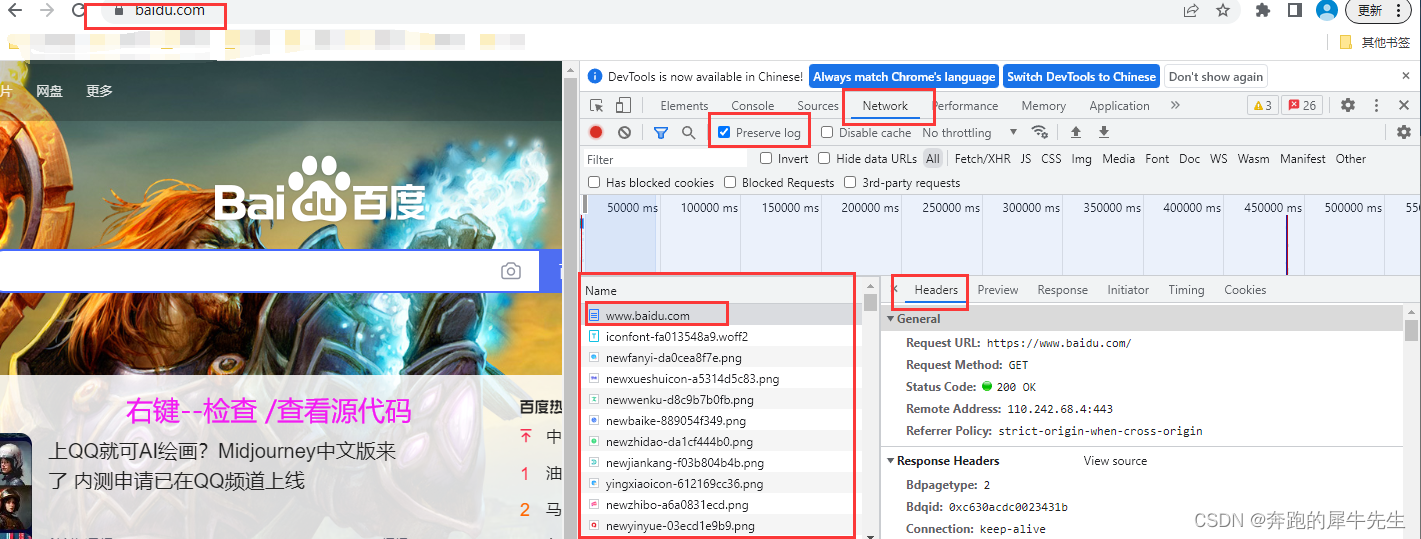
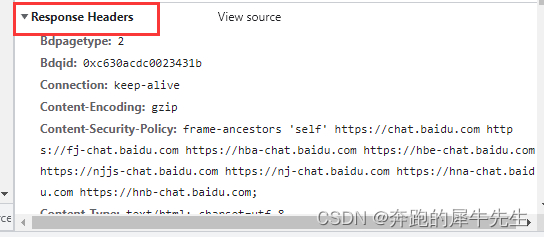
1.5 响应头response.headers
- 也就是 requests.get(url).headers
- 响应头反映的是,网站网页的信息
- 比如一些时间,内容,连接情况等
- 比较用python 爬虫连接的,requests.get(url) 的
![]()
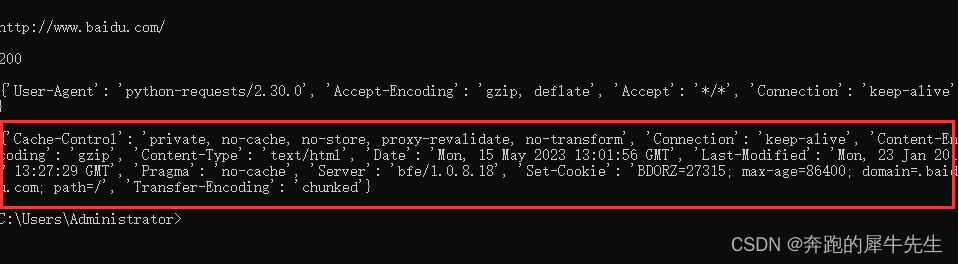
- 而用PC的网页打开的就不一样
1.6 response.request.headers
- 也就是 requests.get(url).request.headers
- 响应对象的请求头,也就是 访问网页的 客户端(有可能是pc /phone /或者python等)的情况
- 明显看出,
- 爬虫连接的,显示 User-Agent': 'python-requests/2.30.0'
- PC的浏览器上网的检查里显示的,显示
Accept: text/html,application/xhtml+xml,application/xml

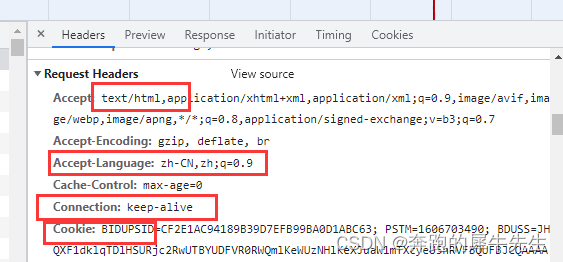

其中 request.headers里面的这个可以当作 request.headers的参数内容
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
插入知识:cookies
- 百度得:Cookie,有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息
- 网站经常利用请求头中的Cookie字段来做用户访问状态的保持
- 也就是 缓存
- 存储在客户端上,而不是网页得服务器端!
- 可能存储:用户名,密码,注册信息等内容
- 也可能只是一个唯一标识得临时ID,方便网站辨识你,方便再session内继续连接,而不用重复识别
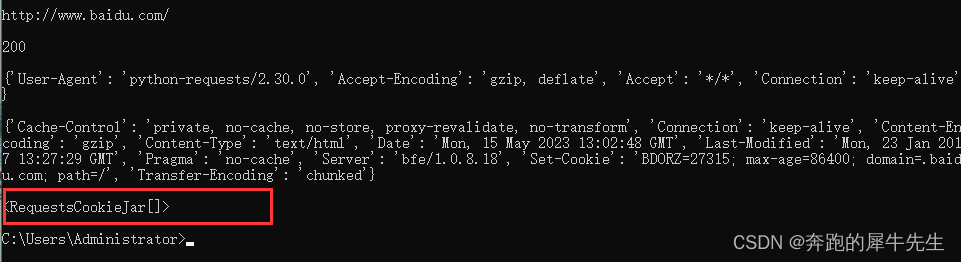
1.7 print(response.cookies)
- 也就是 requests.get(url).cookies
- 网页得cookies

1.8 print(response.request._cookies)
也就是 requests.get(url).request.cookies
客户端的cookies
3 带参数的 requests.get(url,para)
3.1 requests.get(url,headers=headers)
- 注意headers正确写法
- headers是一个字典,写法是 {"":"" , "":""} ,就是需要是 key:value 键值对
- headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"}
3.1.1常见的headers错误写法
- 常见的headers错误写法
- headers="user-agentMozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
- headers={"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"}
- headers={"user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"}
这个报错原因,是不懂 headers的写法
headers是一个字典,写法是 {"":"" , "":""}

3.2 带参数headers后的输出内容
- 其中headers是直接拷贝的 pc 网页检查里的 requests.get(url)里 request.headers里最下面的内容
- 目的是为了冒充pc客户端的浏览器,访问网页的感觉

#print(response.text)
#print(response.content.decode())
print(response.headers)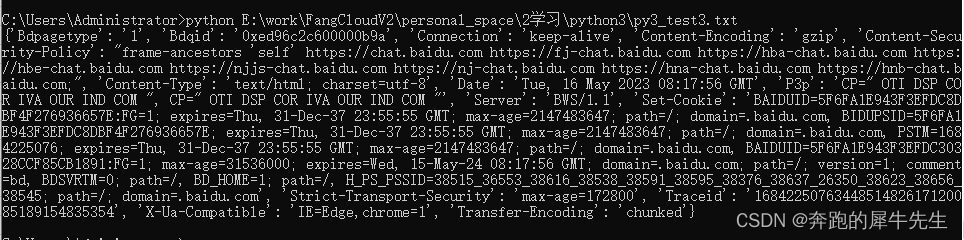
print(response.request.headers)

3.3 其他写法
- ? 查询关键字/ 后面跟的是查询字符串 / 请求参数
- 也可以用字典的写法 params=kw
写法1
url = 'https://www.baidu.com/s?wd=python'
写法2
url = 'https://www.baidu.com/s?
kw = {'wd': 'python'}
response = requests.get(url, headers=headers, params=kw)
3.3 带参数cookies 或者 headers 带包含cookies(试验不成功 )
- 带cookies有两种写法
- requests.get(url,headers=headers) #其中heads字典里包含cookies
- requests.get(url,headers=headers, cookies)
- resp = requests.get(url, headers=headers, cookies=cookies_dict)
- cookie一般是有过期时间的,一旦过期需要重新获取
- cookies = {"cookie的name":"cookie的value"}
- 将cookie字符串转换为cookies参数所需的字典:
- cookies_dict = {cookie.split('=')[0]:cookie.split('=')[-1] for cookie in cookies_str.split('; ')}
- 使用requests获取的resposne对象,具有cookies属性。该属性值是一个cookieJar类型,包含了对方服务器设置在本地的cookie。我们如何将其转换为cookies字典呢?
-
其中response.cookies返回的就是cookieJar类型的对象
- cookies_dict = requests.utils.dict_from_cookiejar(response.cookies)
cookies 试验不成功
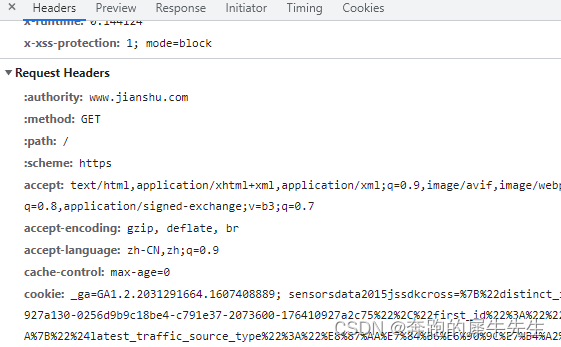
import requests
url="https://www.jianshu.com"
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36","cookies":cookie1}
response=requests.get(url,headers=headers)
print(response.text)
3.4 response = requests.get(url, timeout=3)
- timeout 设置超时时间
- timeout=3表示:发送请求后,3秒钟内返回响应,否则就抛出异常