- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,阿里云专家博主
- 📕系列专栏:Java设计模式、Spring源码系列、Netty源码系列、Kafka源码系列、JUC源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀

文章目录
- 一、引言
- 二、使用
- 三、源码
- 1、初始化
- 2、存储操作
- 2.1 计算索引下标
- 2.2 初始化数组
- 2.3 将数据插入到数组
- 2.4 扩容(后面聊)
- 2.5 将数据插入到链表
- 2.6 将数据插入到红黑树
- 2.7 链表转红黑树
- 四、流程图
- 1、初始化阶段
- 2、存储阶段
- 五、总结
一、引言
ConcurrentHashMap技术在互联网技术使用如此广泛,几乎所有的后端技术面试官都要在ConcurrentHashMap技术的使用和原理方面对小伙伴们进行 360° 的刁难。
作为一个在互联网公司面一次拿一次 Offer 的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(请允许我使用一下夸张的修辞手法)。
于是在一个寂寞难耐的夜晚,暖男我痛定思痛,决定开始写 《吊打面试官》 系列,希望能帮助各位读者以后面试势如破竹,对面试官进行 360° 的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂 Offer!
虽然现在是互联网寒冬,但乾坤未定,你我皆是黑马
二、使用
我们经常在线程安全的场景下使用 ConcurrentHashMap,基本使用如下:
public class ConcurrentHashMapTest {
public static void main(String[] args) {
ConcurrentHashMap<String, String> map = new ConcurrentHashMap<>();
map.put("test1", "1");
map.put("test2", "2");
map.put("test3", "3");
map.remove("test1");
System.out.println(map.get("test1"));
System.out.println(map.get("test2"));
}
}
使用的话,我相信大部分的读者应该都会的,这里小黄也不多介绍了,我们直接进入正题
三、源码
1、初始化
还是我们的老样子,从初始化开始聊源码
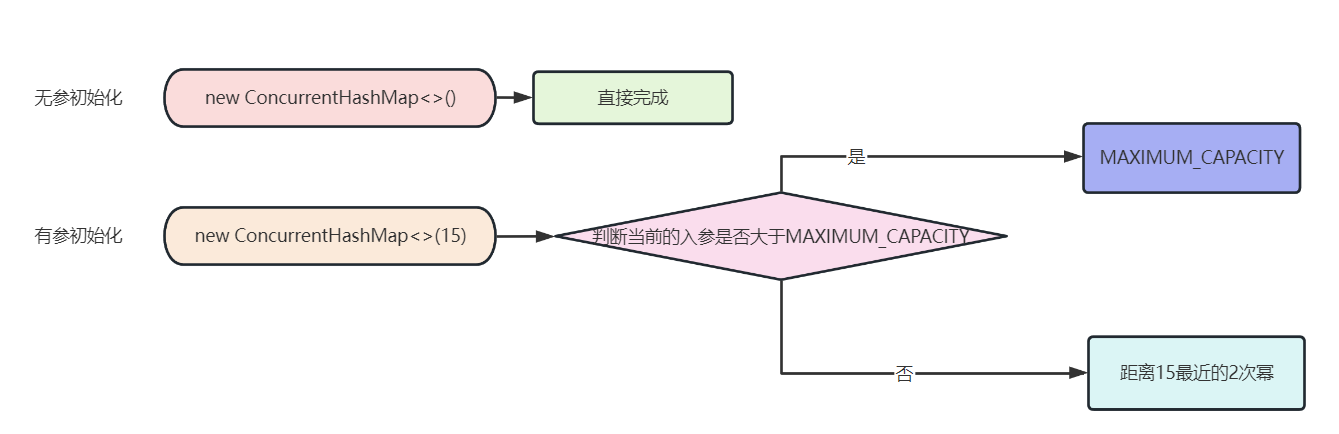
如果我们初始化时不携带入参的话,初始化方法如下:可以看到,基本没有什么东西
public ConcurrentHashMap() {}
如果你携带了入参的话,初始化方法如下:
public ConcurrentHashMap(int initialCapacity) {
// 假如哥们传进来入参小于0
if (initialCapacity < 0)
// 直接抛出异常,说明哥们在搞笑
throw new IllegalArgumentException();
// 用传进来的数值与 MAXIMUM_CAPACITY >>> 1 进行对比
// 若大于则使用MAXIMUM_CAPACITY
// 小于则使用距离initialCapacity最近的2次幂
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
// 根据传进的C的数值,找到其距离最近的2次幂
private static final int tableSizeFor(int c) {
int n = c - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
2、存储操作
public V put(K key, V value) {
// 在调用put方法时,会调用putVal,第三个参数默认传递为false
// 在调用putIfAbsent时,会调用putVal方法,第三个参数传递的为true
// 如果传递为false,代表key一致时,直接覆盖数据
// 如果传递为true,代表key一致时,什么都不做,key不存在,正常添加(Redis,setnx)
return putVal(key, value, false);
}
2.1 计算索引下标
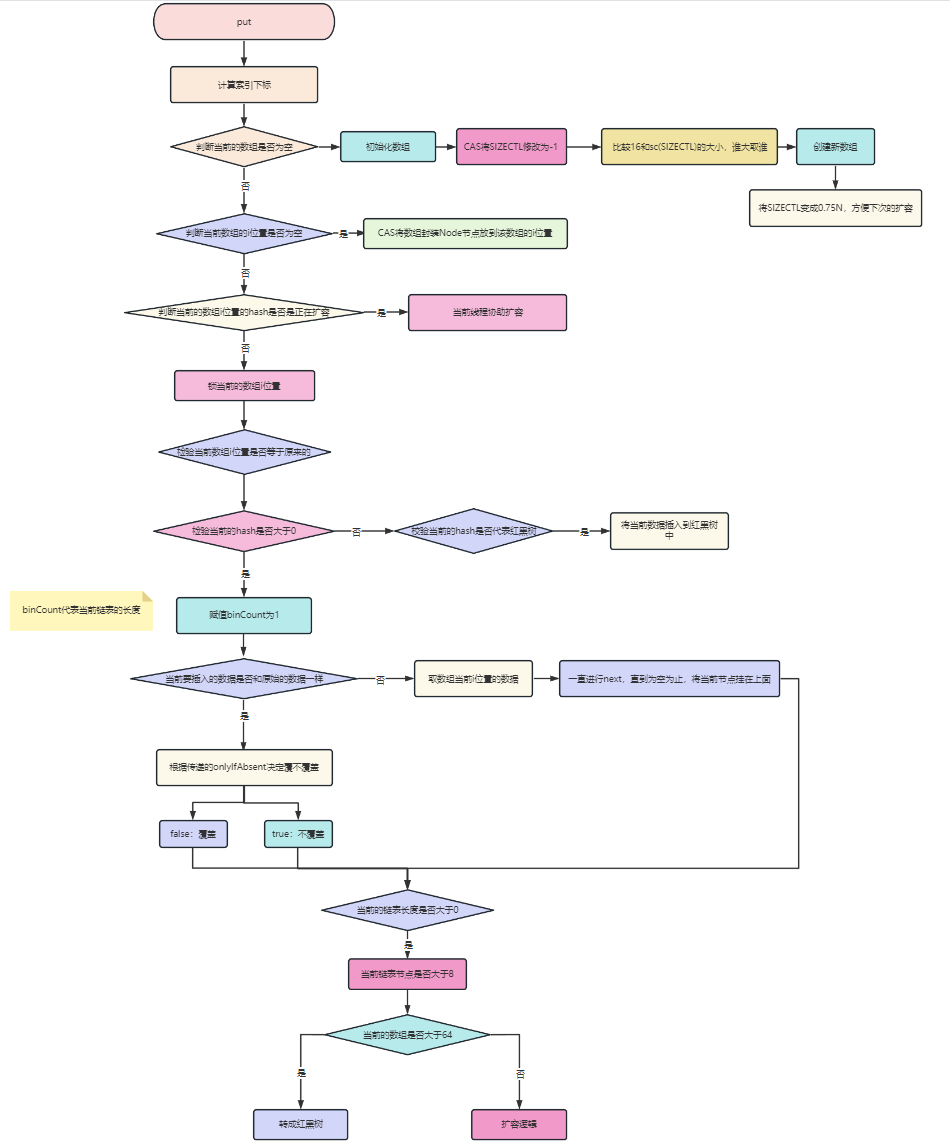
final V putVal(K key, V value, boolean onlyIfAbsent) {
// 如果当前的key或者value是空的话,直接抛出异常
if (key == null || value == null){
throw new NullPointerException();
}
// 获取其下标
int hash = spread(key.hashCode());
int binCount = 0;
}
// 作用:用高16位与低16位进行^运算,让高位的数值可以进行计算
// 为什么原来的高位没有办法计算呢?
// 我们后面的 (n - 1) & hash 的数据,&数据如下:
// 00000000 00000000 00000000 01010101
// 0000000 00000000 00000000 00011111
// 我们这里看到,如果高16位不与低16位^运算的话,那么基本我们的高位永远也参加不了计算
// 为什么需要&HASH_BITS:
// 保证最终的结果大于0,因为如果结果小于0的话,代表不同的意义:
// static final int MOVED = -1; // 代表当前hash位置的数据正在扩容!
// static final int TREEBIN = -2; // 代表当前hash位置下挂载的是一个红黑树
// static final int RESERVED = -3; // 预留当前索引位置……
static final int spread(int h) {
return (h ^ (h >>> 16)) & HASH_BITS;
}
2.2 初始化数组
// tab指向table,标准的Doug Lea写法
for (Node<K,V>[] tab = table;;) {
Node<K,V> f;
int n, i, fh;
// 如果当前的数组为空或者他的数组长度为0
// 则进行初始化
if (tab == null || (n = tab.length) == 0){
tab = initTable();
}
}
// sizeCtl:是数组在初始化和扩容操作时的一个控制变量
// -1:代表当前数组正在初始化
// 小于-1:低16位代表当前数组正在扩容的线程个数(如果1个线程扩容,值为-2,如果2个线程扩容,值为-3)
// 0:代表数组还没初始化
// 大于0:代表当前数组的扩容阈值,或者是当前数组的初始化大小
private final Node<K,V>[] initTable() {
// 经典引用
Node<K,V>[] tab;
int sc;
// 当前的初始化没有完成时,会一直进行该while循环
while ((tab = table) == null || tab.length == 0) {
// 如果小于0,代表当前数组正在扩容或者初始化
// 当前线程等待一下
if ((sc = sizeCtl) < 0)
Thread.yield();
// 尝试将SIZECTL从SC更改为-1
// CAS修改,线程安全,保证只有一个线程执行数组初始化
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
// 更改成功,再次判断一下(参考DCL)
// 防止下面sizeCtl = sc刚赋值完,正好有线程走到这一步,不做限制的话就会重新初始化了
if ((tab = table) == null || tab.length == 0) {
// 判断当前的sc是否大于0(sc=SIZECTL)
// 大于0:n = sc
// 小于等于0:n = DEFAULT_CAPACITY
// 一般我们只要不传入入参,这里基本走DEFAULT_CAPACITY的扩容
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
// 扩容即可
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
// table、tab赋值
table = tab = nt;
// 这里有点意思
// 将sc赋值成(n - 1/4n) = 0.75N
// 这里0.75是不是很熟悉,负载因子
sc = n - (n >>> 2);
}
} finally {
// 将上面的扩容阈值赋予sizeCtl
sizeCtl = sc;
}
// 结束循环
break;
}
}
return tab;
}
2.3 将数据插入到数组
// 如果当前数组该下标没有数据,直接插入即可
if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// CAS将当前的hash、key、value组装成一个Node,插入当前数组i位置
// 插入成功结束即可
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))){
break;
}
}
// 基于我们上面说的(n - 1) & hash算出下标
// 返回当前数组下该下标的数据
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) {
return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE);
}
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) {
return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v);
}
static class Node<K,V> implements Map.Entry<K,V> {
// 当前的hash值
final int hash;
// key
final K key;
// value
volatile V val;
// 下一个节点(用来连链表的)
volatile Node<K,V> next;
}
2.4 扩容(后面聊)
- 这部分后面聊
// 判断当前位置数据是否正在扩容……
if ((fh = f.hash) == MOVED)
// 如果在扩容,则当前线程帮助其扩容
tab = helpTransfer(tab, f);
2.5 将数据插入到链表
else {
V oldVal = null;
// 锁当前的数组下标i的数组块
synchronized (f) {
// 看一下当前数组的i位置是不是等于f
// 相当于再次校验一次(DCL)
if (tabAt(tab, i) == f) {
// static final int MOVED = -1; // 代表当前hash位置的数据正在扩容!
// static final int TREEBIN = -2; // 代表当前hash位置下挂载的是一个红黑树
// static final int RESERVED = -3; // 预留当前索引位置……
// fh = f.hash
// 判断下当前的fh是否大于0,也就是不是上面三种情况
if (fh >= 0) {
// 记录当前链表下面挂了几个
binCount = 1;
// 获取当前的数组节点,没循环一次binCount加一
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 如果当前数组下标的hash和我们入参的hash一样,代表重复数据
if (e.hash == hash &&
// 如果当前的key也等于原始的key
// 或者是根据equals判断出来的相等(因为有一些可能重写了equals方法)
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
// 将当前老的数据赋值给oldVal
oldVal = e.val;
// 这里的onlyIfAbsent我们之前也聊过
// 如果传递为false,代表key一致时,直接覆盖数据
// 如果传递为true,代表key一致时,什么都不做,key不存在,正常添加(Redis,setnx)
if (!onlyIfAbsent)
// 覆盖数据
e.val = value;
break;
}
// 这里就不是相同的数据了,需要挂链表下面了
// 先获取数组最上面的数据
Node<K,V> pred = e;
// 判断下当前的下一个数据是不是空指针
// 不是空指针的话,继续指向下一个指针
if ((e = e.next) == null) {
// 直到最后的时候,创建一个节点挂上去
pred.next = new Node<K,V>(hash, key,value, null);
break;
}
}
}
}
2.6 将数据插入到红黑树
// 如果上面不成立的话,也就是当前的数组下面是一个红黑树
// 需要将当前的数据放到红黑树里面
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
// 将当前数据放入到红黑树中
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) {
// 记录一下老数据
oldVal = p.val;
// 这里的onlyIfAbsent我们之前也聊过
// 如果传递为false,代表key一致时,直接覆盖数据
// 如果传递为true,代表key一致时,什么都不做,key不存在,正常添加(Redis,setnx)
if (!onlyIfAbsent)
// 覆盖数据
p.val = value;
}
}
2.7 链表转红黑树
// 如果当前的链表上的数据不等于0
if (binCount != 0) {
// 当前列表下的数据长度大于8
// 这里需要注意,大于8的话并不是立即转成红黑树,还需要判断当前数组的长度
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
static final int TREEIFY_THRESHOLD = 8;
static final int MIN_TREEIFY_CAPACITY = 64;
private final void treeifyBin(Node<K,V>[] tab, int index) {
Node<K,V> b; int n, sc;
// 如果当前的数组不为空
if (tab != null) {
// 如果当前的数组长度小于64,则没必要转成红黑树
// 直接扩容即可
if ((n = tab.length) < MIN_TREEIFY_CAPACITY)
tryPresize(n << 1);
// 后面的是转成红黑树的代码
// 我们下一章在分析
else if ((b = tabAt(tab, index)) != null && b.hash >= 0) {
synchronized (b) {
if (tabAt(tab, index) == b) {
TreeNode<K,V> hd = null, tl = null;
for (Node<K,V> e = b; e != null; e = e.next) {
TreeNode<K,V> p = new TreeNode<K,V>(e.hash, e.key, e.val, null, null);
if ((p.prev = tl) == null){
hd = p;
}
else{
tl.next = p;
}
tl = p;
}
setTabAt(tab, index, new TreeBin<K,V>(hd));
}
}
}
}
}
四、流程图
1、初始化阶段
2、存储阶段
五、总结
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构和中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,喜欢后端架构和中间件源码。
我们下期再见。
我从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。
往期文章推荐:
- 从源码全面解析Java 线程池的来龙去脉
- 从源码全面解析LinkedBlockingQueue的来龙去脉
- 从源码全面解析 ArrayBlockingQueue 的来龙去脉
- 从源码全面解析ReentrantLock的来龙去脉
- 阅读完synchronized和ReentrantLock的源码后,我竟发现其完全相似
- 从源码全面解析 ThreadLocal 关键字的来龙去脉
- 从源码全面解析 synchronized 关键字的来龙去脉
- 阿里面试官让我讲讲volatile,我直接从HotSpot开始讲起,一套组合拳拿下面试