视频教程传送门:
Canal极简入门:一小时让你快速上手Canal数据同步神技~_哔哩哔哩_bilibiliCanal极简入门:一小时让你快速上手Canal数据同步神技~共计13条视频,包括:01.课前导学与前置知识点、02.Canal组件了解、03.MySQL主从复制原理等,UP主更多精彩视频,请关注UP账号。 https://www.bilibili.com/video/BV1Uc411P7XN/?spm_id_from=333.337.search-card.all.click
https://www.bilibili.com/video/BV1Uc411P7XN/?spm_id_from=333.337.search-card.all.click
一、前置知识点
1.1 Canal读音

流行的读法:Canal
1.2 前置知识点
-
MySQL 基本操作
-
Java 基础
-
SpringBoot
二、Canal介绍
2.1 历史背景
早期阿里巴巴在杭州和美国部署机房,存在跨机房同步的业务需求,最初的实现是基于业务触发的方式 ,不是是很方便, 2010 年,逐步使用数据库日志解析方式取代,这由此衍生出了大量的数据库增量订阅和消费操作。在这种背景下Canal就出来了。
2014年左右,天猫双十一首次引入,用于解决大型促销活动MySQL 数据库的高并发读写问题。后来,在阿里内部得到了广泛应用和推广,并于2017年正式开源。
Github:https://github.com/alibaba/canal
2.2 定义
Canal 组件是一个基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费,支持将增量数据投递到下游消费者(如 Kafka、RocketMQ 等)或者存储(如 Elasticsearch、HBase 等)的组件。
大白话: Canal 感知到MySQL数据变动,然后解析变动数据,将变动数据发送到MQ或者同步到其他数据库,等待进一步业务逻辑处理。
三、Canal的工作原理
3.1 MySQL主从复制原理

-
MySQL master 将数据变更写入二进制日志binary log,简称Binlog。
-
MySQL slave 将 master 的 binary log 拷贝到它的中继日志(relay log)
-
MySQL slave 重放 relay log 操作,将变更数据同步到最新。
3.2 MySQL Binlog日志
3.2.1 介绍
MySQL 的Binlog可以说 MySQL 最重要的日志,它记录了所有的 DDL 和 DML语句,以事件形式记录。
MySQL默认情况下是不开启Binlog,因为记录Binlog日志需要消耗时间,官方给出的数据是有1%的性能损耗。
具体开不开启,开发中需要根据实际情况做取舍。
一般来说,在下面两场景下会开启Binlog日志:
-
MySQL 主从集群部署时,需要将在 Master 端开启 Binlog,方便将数据同步到Slaves中。
-
数据恢复了,通过使用 MySQL Binlog 工具来使恢复数据。
3.2.1 Binlog的分类
MySQL Binlog 的格式有三种,分别是 STATEMENT,MIXED,ROW。在配置文件中可以选择配
置 binlog_format= statement|mixed|row。
| 分类 | 介绍 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | 语句级别,记录每一次执行写操作的语句,相对于ROW模式节省了空间,但是可能产生数据不一致如update tt set create_date=now(),由于执行时间不同产生饿得数据就不同 | 节省空间 | 可能造成数据不一致 |
| ROW | 行级,记录每次操作后每行记录的变化。假如一个update的sql执行结果是1万行statement只存一条,如果是row的话会把这个1万行的结果存这。 | 持数据的绝对一致性。因为不管sql是什么,引用了什么函数,他只记录执行后的效果 | 占用较大空间 |
| MIXED | 是对statement的升级,如当函数中包含 UUID() 时,包含 AUTO_INCREMENT 字段的表被更新时,执行 INSERT DELAYED 语句时,用 UDF 时,会按照 ROW的方式进行处理 | 节省空间,同时兼顾了一定的一致性 | 还有些极个别情况依旧会造成不一致,另外statement和mixed对于需要对binlog的监控的情况都不方便 |
综合上面对比,Canal 想做监控分析,选择 row 格式比较合适。
3.3 Canal 工作原理
-
Canal 将自己伪装为 MySQL slave(从库) ,向 MySQL master (主库)发送dump 协议
-
MySQL master(主库) 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
-
Canal 接收并解析 Binlog 日志,得到变更的数据,执行后续逻辑

四、Canal运用场景
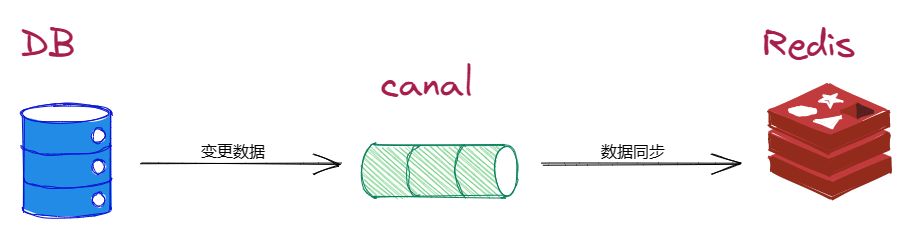
4.1 数据同步
Canal 可以帮助用户进行多种数据同步操作,如实时同步 MySQL 数据到 Elasticsearch、Redis 等数据存储介质中。
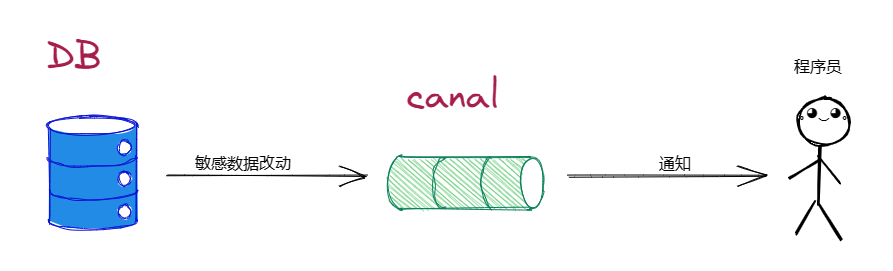
4.2 数据库实时监控
Canal 可以实时监控 MySQL 的更新操作,对于敏感数据的修改可以及时通知相关人员。
4.3 数据分析和挖掘
Canal 可以将 MySQL 增量数据投递到 Kafka 等消息队列中,为数据分析和挖掘提供数据来源。
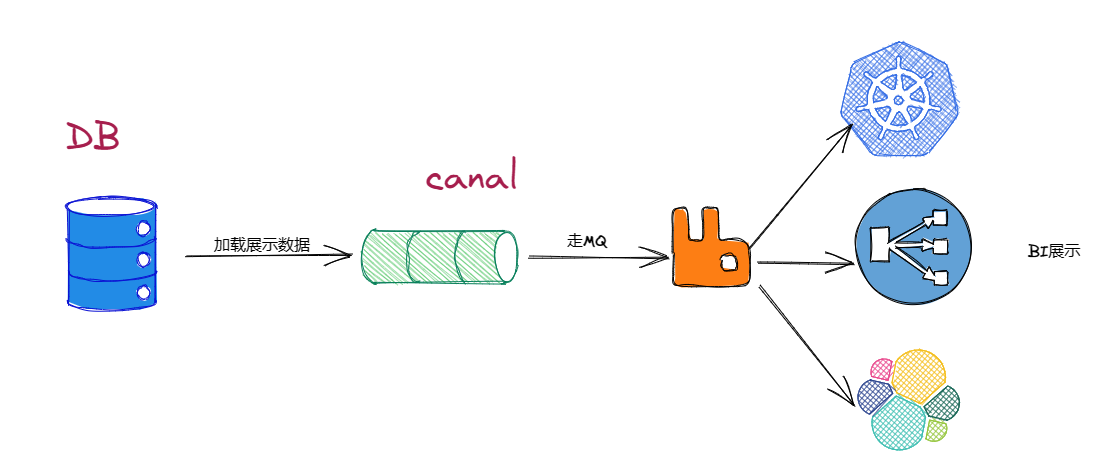
4.4 数据库备份
Canal 可以将 MySQL 主库上的数据增量日志复制到备库上,实现数据库备份。

4.5 数据集成
Canal 可以将多个 MySQL 数据库中的数据进行集成,为数据处理提供更加高效可靠的解决方案。

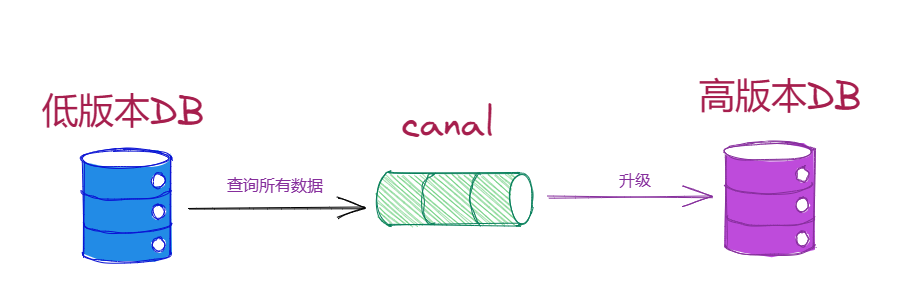
4.6 数据库迁移
Canal 可以协助完成 MySQL 数据库的版本升级及数据迁移任务。
五、MySQL准备
5.1 创建数据库
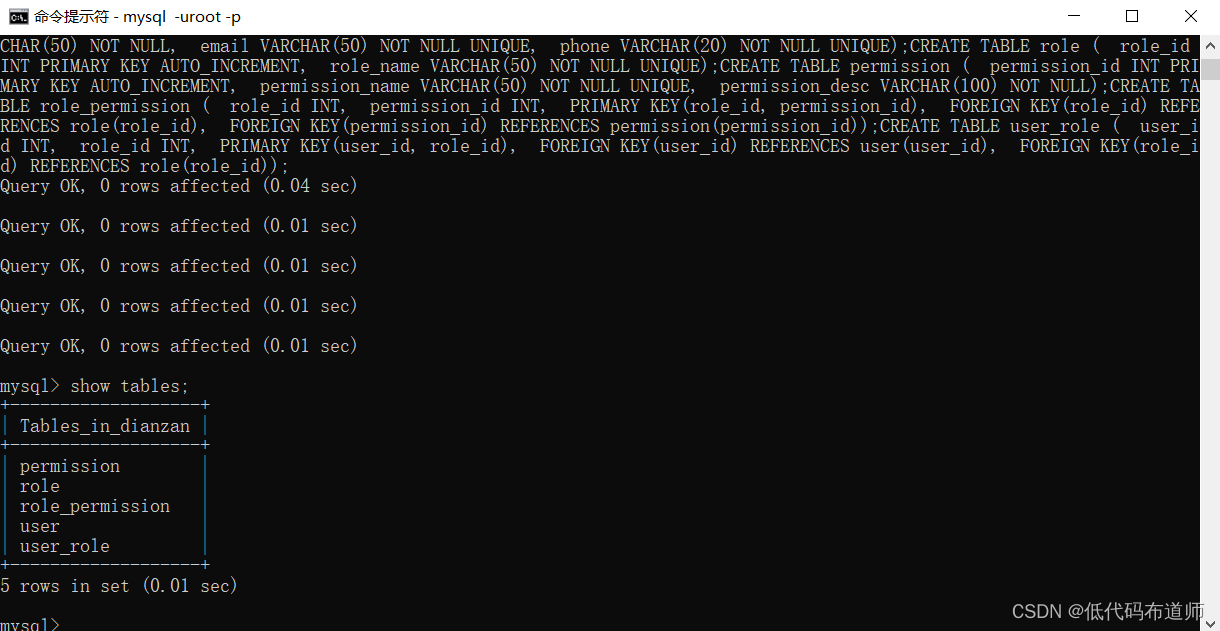
新建库:canal-demo

5.2 创建表
用户表
CREATE TABLE `user` (
`id` bigint NOT NULL AUTO_INCREMENT,
`name` varchar(255) DEFAULT NULL,
`age` int DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;5.3 修改配置文件开启Binlog支持
修改mysql的配置文件, 一名名字为: my.ini
server-id=1
log-bin=C:/ProgramData/MySQL/MySQL Server 8.0/binlogs/mysql-bin.log
binlog_format=row
binlog-do-db=canal-demoserver-id:mysql 实例id,集群时用于区分实例
lob-bin:binlog日志文件名称
binlog_format:binlog日志数据保存格式
binlog-do-db:指定开启binlog日志数据库。
注意:一般根据情况进行指定需要同步的数据库,如果不配置则表示所有数据库均开启 Binlog。
5.4 校验Binlog生效
重启MySQL服务,查看Binlog日志
方式1:
show VARIABLES like 'log_bin'
方式2:
进入指定目录:

insert into user(name, age) values('dafei', 18);
insert into user(name, age) values('dafei', 18);
insert into user(name, age) values('dafei', 18); 
六、Canal安装与配置
6.1 下载
地址:Releases · alibaba/canal · GitHub
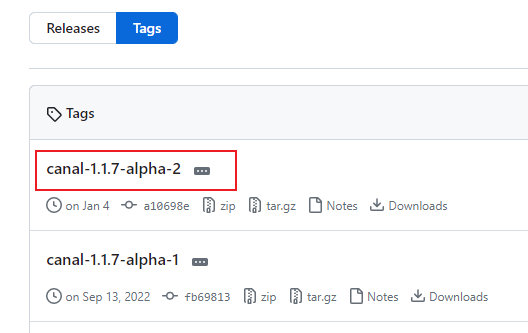
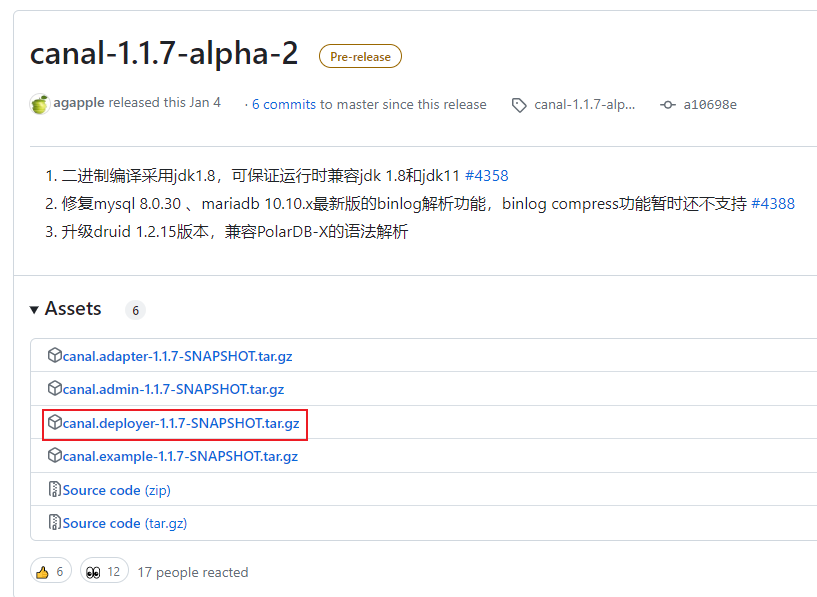
解压即可。
6.2 配置
6.2.1修改canal.properties的配置
canal.port = 11111
# tcp, kafka, rocketMQ, rabbitMQ, pulsarMQ
canal.serverMode = tcp
canal.destinations = examplecanal.port:默认端口 11111
canal.serverMode:服务模式,tcp 表示输入客户端,xxMQ输出到各类消息中间件
canal.destinations:canal能可以收集多个MySQL数据库数据,每个MySQL数据库都有独立的配置文件控制。具体配置规则: conf/目录下,使用文件夹放置,文件夹名代表一个MySQL实例。canal.destinations用于配置需要监控数据的数据库。如果是多个,使用,隔开
6.2.2 修改MySQL实例配置文件instance.properties
config/目录下
canal.instance.mysql.slaveId=20
# position info
canal.instance.master.address=127.0.0.1:3306
# username/password
canal.instance.dbUsername=root
canal.instance.dbPassword=admincanal.instance.mysql.slaveId:使用canal 从阶段id
canal.instance.master.address:数据库ip端口
canal.instance.dbUsername:连接mysql账号
canal.instance.dbPassword:连接mysql密码
6.3 启动
双击启动

七、Canal编程
7.1 Helloworld
1>创建项目:canal-hello
2>导入相关依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>3>编写测试代码
package com.langfeiyes.hello;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.protocol.CanalEntry;
import com.alibaba.otter.canal.protocol.Message;
import com.google.protobuf.ByteString;
import com.google.protobuf.InvalidProtocolBufferException;
import java.net.InetSocketAddress;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
public class CanalDemo {
public static void main(String[] args) throws InvalidProtocolBufferException {
//1.获取 canal 连接对象
CanalConnector canalConnector = CanalConnectors.newSingleConnector(new InetSocketAddress("localhost", 11111), "example", "", "");
while (true) {
//2.获取连接
canalConnector.connect();
//3.指定要监控的数据库
canalConnector.subscribe("canal-demo.*");
//4.获取 Message
Message message = canalConnector.get(100);
List<CanalEntry.Entry> entries = message.getEntries();
if (entries.size() <= 0) {
System.out.println("没有数据,休息一会");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
} else {
for (CanalEntry.Entry entry : entries) {
// 获取表名
String tableName = entry.getHeader().getTableName();
// Entry 类型
CanalEntry.EntryType entryType = entry.getEntryType();
// 判断 entryType 是否为 ROWDATA
if (CanalEntry.EntryType.ROWDATA.equals(entryType)) {
// 序列化数据
ByteString storeValue = entry.getStoreValue();
// 反序列化
CanalEntry.RowChange rowChange = CanalEntry.RowChange.parseFrom(storeValue);
// 获取事件类型
CanalEntry.EventType eventType = rowChange.getEventType();
// 获取具体的数据
List<CanalEntry.RowData> rowDatasList = rowChange.getRowDatasList();
// 遍历并打印数据
for (CanalEntry.RowData rowData : rowDatasList) {
List<CanalEntry.Column> beforeColumnsList = rowData.getBeforeColumnsList();
Map<String, Object> bMap = new HashMap<>();
for (CanalEntry.Column column : beforeColumnsList) {
bMap.put(column.getName(), column.getValue());
}
Map<String, Object> afMap = new HashMap<>();
List<CanalEntry.Column> afterColumnsList = rowData.getAfterColumnsList();
for (CanalEntry.Column column : afterColumnsList) {
afMap.put(column.getName(), column.getValue());
}
System.out.println("表名:" + tableName + ",操作类型:" + eventType);
System.out.println("改前:" + bMap );
System.out.println("改后:" + afMap );
}
}
}
}
}
}
}
4>测试
对canal-demo 库中user表进行DML操作,观察打印值

Canal API 体系分析

7.2 SpringBoot集成
1>创建项目:canal-sb-demo
2>导入相关依赖
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-parent</artifactId>
<version>2.7.11</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.6-RELEASE</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.12</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.21.4</version>
</dependency>
</dependencies>3>配置文件
canal:
server: 127.0.0.1:11111 #canal 默认端口11111
destination: example
spring:
application:
name: canal-sb-demo
datasource:
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/canal-demo?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTC&useSSL=false
username: root
password: admin
4>实体对象
package com.langfeiyes.sb.domain;
public class User {
private Long id;
private String name;
private Integer age;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}5>监控处理类
package com.langfeiyes.sb.handler;
import com.langfeiyes.sb.domain.User;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;
@Component
@CanalTable(value = "user")
public class UserHandler implements EntryHandler<User> {
@Override
public void insert(User user) {
System.err.println("添加:" + user);
}
@Override
public void update(User before, User after) {
System.err.println("改前:" + before);
System.err.println("改后:" + after);
}
@Override
public void delete(User user) {
System.err.println("删除:" + user);
}
}
6>启动类
@SpringBootApplication
public class App {
public static void main(String[] args) {
SpringApplication.run(App.class, args);
}
}7>测试
-
先启动canal服务器
-
再启动项目
-
修改user表
-
观察结果
八、同类型技术
类型1:基于日志解析的数据同步组件
这类组件主要是通过解析数据库的Binlog(MySQL)或者Redo Log(Oracle)等日志文件,获取到数据库的增删改操作,并将这些操作记录下来。然后,这些操作记录可以被传输到另一个数据库中,以达到数据同步的目的。此类组件的代表产品包括阿里开源的Canal、腾讯云的DBSync等。
类型2:基于ETL的数据同步组件
ETL即Extract-Transform-Load,指的是从源系统抽取数据、对数据进行转换处理、最终加载到目标系统中。这类组件通常需要编写复杂的数据转换规则和数据映射关系,适用于数据结构变动频繁、数据量较大、数据来源较多的场景。代表产品包括阿里云的DataWorks、Informatica PowerCenter等。
类型3:基于CDC的数据同步组件
CDC(Change Data Capture)即变更数据捕获,它是一种数据同步技术,能够在实时或准实时地捕获数据库中的数据变更,并将其传输到另一个数据库中。CDC技术基于数据库的事务日志或重做日志实现,能够实现低延迟、高性能的数据同步。CDC组件的代表产品包括Oracle GoldenGate、IBM Infosphere Data Replication等。
类型4:基于消息队列的数据同步组件
这类组件通常将数据库中发生的变更操作抽象成一种数据结构,并通过消息队列将其发布到其他系统中进行处理,实现数据的异步传输和解耦。代表产品包括Apache Kafka、RabbitMQ等。
九、Canal常见面试题
问:Canal是什么?有哪些特性?
答:Canal是阿里巴巴开源的一款基于Netty实现的分布式、高性能、可靠的消息队列,在实时数据同步和数据分发场景下有着广泛的应用。Canal具有以下特性:支持MySQL、Oracle等数据库的日志解析和订阅;支持多种数据输出方式,如Kafka、RocketMQ、ActiveMQ等;支持支持数据过滤和格式转换;拥有低延迟和高可靠性等优秀的性能指标。
问:Canal的工作原理是什么?
答:Canal主要通过解析数据库的binlog日志来获取到数据库的增、删、改操作,然后将这些变更事件发送给下游的消费者。Canal核心组件包括Client和Server两部分,Client负责连接数据库,并启动日志解析工作,将解析出来的数据发送给Server;Server则负责接收Client发送的数据,并进行数据过滤和分发。Canal还支持多种数据输出器,如Kafka、RocketMQ、ActiveMQ等,可以将解析出来的数据发送到不同的消息队列中,以便进行进一步的处理和分析。
问:Canal的优缺点是什么?
答:Canal的优点主要包括:高性能、分布式、可靠性好、支持数据过滤和转换、跨数据库类型(如MySQL、Oracle等)等。缺点包括:使用难度较大、对数据库的日志产生一定的影响、不支持数据的回溯(即无法获取历史数据)等。
问:Canal在业务中有哪些应用场景?
答:Canal主要用于实时数据同步和数据分发场景,常见的应用场景包括:数据备份与灾备、增量数据抽取和同步、数据实时分析、在线数据迁移等。特别是在互联网大数据场景下,Canal已经成为了各种数据处理任务的重要工具之一。