文章目录
- 7.7 重定位
- 7.7.1 重定位表目
- 7.7.2 重定位符号引用
- 重定位PC相关的引用
- 重定位绝对引用
- 7.8 可执行目标文件
- 7.9 加载可执行目标文件
7.7 重定位
一旦链接器完成了符号解析这一步,它就把代码中的每个符号引用和确定的一个符号定义(也就是,它的一个输入目标模块中的一个符号表表目)联系起来。在此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位步骤了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。
重定位由两步组成:
- 重定位节和符号定义。这一步中,链接器将所有相同类型的节合并为同一类型的新的聚合节。 例如,来自输入模块的
.data节被全部合并成一个节,这个节成为输出的可执行目标哦文件的.data节。然后,链接器将运行时存储器地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输出模块定义的每个符号。当这一步完成时,程序中的每个指令和全局变量都有唯一的运行时存储器地址了。 - 重定位节中的符号引用。这一步中,链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址。 为了执行这一步,链接器依赖于称为重定位表目(relocation entry)的可重定位目标模块中的数据结构。
7.7.1 重定位表目
当汇编器生成一个目标模块时,它并不知道数据和代码最终将存放在存储器中的什么位置。它也不知道这个模块引用的外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置未知的目标引用,它就会生成一个重定位表目(relocation entry),告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。代码的重定位表目放在 .relo.text 中。已初始化数据的重定位表目放在 .relo.data 中。
下图展示了 ELF 重定位表目的格式。每个表目表示一个必须重定位的引用。

offset是需要被修改的引用的节偏移。symbol标识被修改引用应该指向的符号。type告知链接器如何修改新的引用。
ELF 定义了 11 种不同的重定位类型,有些相当隐秘。我们只关心其中两种最基本的重定位类型:
R_386_PC32:重定位一个使用 32 位 PC 相关的地址引用。一个 PC 相关的地址就是距程序计数器(PC)的当前运行时值的偏移量。当CPU 执行使用 PC 相关寻址的指令时,它就将在指令中编码的 32 位值加上 PC 的当前运行时值,得到有效地址(如call指令的目标),PC 值通常是存储器中下一条指令的地址。R_386_32:重定位一个使用 32 位绝对地址的引用。通过绝对寻址,CPU 直接使用在指令中编码的 32 位值作为有效地址,不需要进一步修改。
7.7.2 重定位符号引用
链接器的重定位算法的伪代码:
foreach section s {
foreach relocation entry r {
refptr = s + r.offset; /*ptr to reference to be relocated*/
/*relocate a PC-relative reference*/
if (r.type == R_386_PC32) {
refaddr = ADDR(s) + r.offset; /* ref's run-time address */
*refptr = (unsigned)(ADDR(r.symbol) + *refptr - refaddr);
}
/* relocate an absolute reference */
if (r.type == R_386_32)
*refptr = (unsigned)(ADDR(r.symbol) + *refptr);
}
}
- 第 1 行和第 2 行在每个节
s以及与每个节关联的重定位表目r上迭代执行。为了使描述具体化,假设每个节s是一个字节数组,每个重定位表目r是一个类型为Elf32_Rel的结构,如图7.8 中的定义。另外,还假设当算法运行时,链接器已经为每个节和符号都选择了来运行时地址(分别用ADDR(s)和ADDR(r.symbol)表示)。 - 第 3 行计算的是需要重定位的 4 字节引用的数组
s中的地址。如果这个引用使用的是 PC 相关寻址,那么它就用第 5 ~ 9 行来重定位。如果该引用使用的是绝对寻址,它就通过第 11 ~13行来重定位。
重定位PC相关的引用
回想 第7章链接:编译器驱动程序 中的示例:

main.o 的 .text 节中的 main 程序调用 swap 程序,该程序是在 swap.o 中定义的。
下面是 call 指令的反汇编列表,由 GNU OBJDUMP 工具生成:

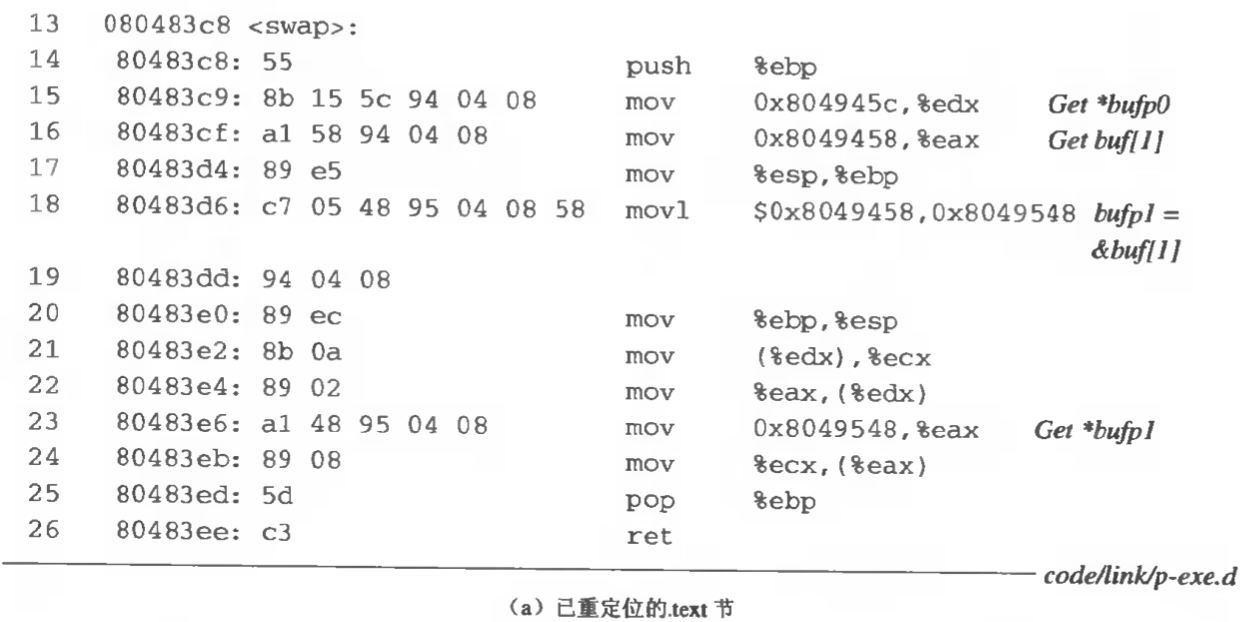
从该列表中可以看到 call 指令开始于节偏移 0x6 处,由 1 个字节的操作码 0xe8 和随后的 32 位引用 0xfffffffc(十进制-4) 组成,它是以小端法字节顺序存储的。
还看到下一行显示的是这个引用的重定位表目(重定位表目和指令实际上是存放在目标文件的不同节中的。OBJDUMP 工具为了方便把它们显示在一起。)重定位表目 r 由 3 个域组成:
r.offset = 0x7
r.symbol = swap
r.type = R_386_PC32
这些域告诉链接器修改开始于偏移量 0x7 处的 32 位 PC 相关引用,使得在运行时它指向 swap 程序。现在,假设链接器已经判定:
ADDR(s) = ADDR(.text) = 0x80483b4
和
ADDR(r.symbol) = ADDR(swap) = 0x80483c8
使用上面的算法那,链接器首先计算出引用的运行时地址(第7行):
refaddr = ADDR(s) + r.offset
= 0x80483b4 + 0x7
= 0x80483bb
然后,它将引用从当前值(-4)修改为 0x9,使得它在运行时指向 swap 程序(第8行):
*refptr = (unsigned)(ADDR(r.symbol) + *refptr - refaddr)
= (unsigned)(0x80483c8) + (-4) - 0x80483bb)
= (unsigned)(0x9)
在得到的可执行目标文件中,call 指令有如下的重定位形式:
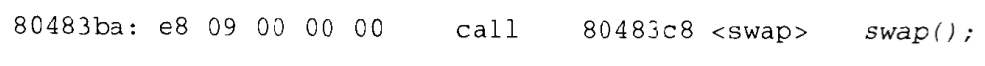
在运行时,call 指令将存放在地址 0x80483ba 处。当 CPU 执行 call 指令时,PC的值为 0x80483bf,即紧随在 call 指令之后的指令的地址。为了执行这条指令,CPU执行以下的步骤:
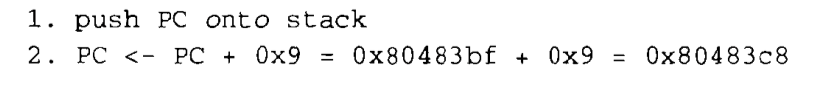
因此,要执行的下一条指令就是 swap 程序的第一条指令,这就是我们想要的!
可能你想知道为什么汇编器会生成 call 指令中的引用的初始值为 -4。汇编器用这个值作为偏移量,是因为 PC 总是指向当前指令的下一条指令。在有不同指令大小和编码方式的不同的机器上,该机器的汇编器会使用不同的偏移量。这是一个很有用的技巧,它允许链接器透明地重定位引用,很幸运地不用知道某一台机器的指令编码。
重定位绝对引用
回想 第7章链接:编译器驱动程序 中的示例程序,swap.o 模块将全局指针 bufp0 初始化为指向全局数组 buf 的第一个元素的地址:
int *bufp0 = &buf[0];
因为 bufp0 是一个已初始化的数据目标,那么它将被存放在可重定位模块 swap.o 的 .data 节中。因为它被初始化为一个全局数组的地址,所以它需要被重定位。
下面是 swap.o 中 .data 节的反汇编列表:

.data 节包含一个 32 位引用,bufp0 指针,它的值为 0x0。
重定位表目告诉链接器这是一个 32 位绝对引用,开始于偏移 9 处,必须重定位使得它指向符号 buf。
现在,假设链接器已经判定:
ADDR(r.symbol) = ADDR(buf) = 0x8049454
链接器使用上面的算法的第 13 行修改了引用:
*refptr = (unsigned)(ADDR(r.symbol) + *refptr)
= (unsigned)(0x8049454 + 0)
= (unsigned)(0x8049454)
在得到的可执行目标文件中,引用有下面的重定位形式:

总而言之,链接器在运行时确定,变量 bufp0 将放置在存储器地址 0x804945c 处,并且被初始化为 0x8049454,这个值就是 buf 数组的运行时地址。
swap.o 模块中的 .text 节包含 5 个绝对引用,都以相似的方式进行重定位。下图展示了最终的可执行目标文件中被重定位的 .text 和 .data 节。



7.8 可执行目标文件
我们已经看到链接器是如何将多个目标模块合并成一个可执行目标文件的。
C 程序一开始是一组 ASCII 文本文件,已经被转化为一个二进制文件,且这个二进制文件包含加载程序到存储器并运行它所需的所有信息。
下图概括了一个典型的 ELF 可执行文件中的各类信息:
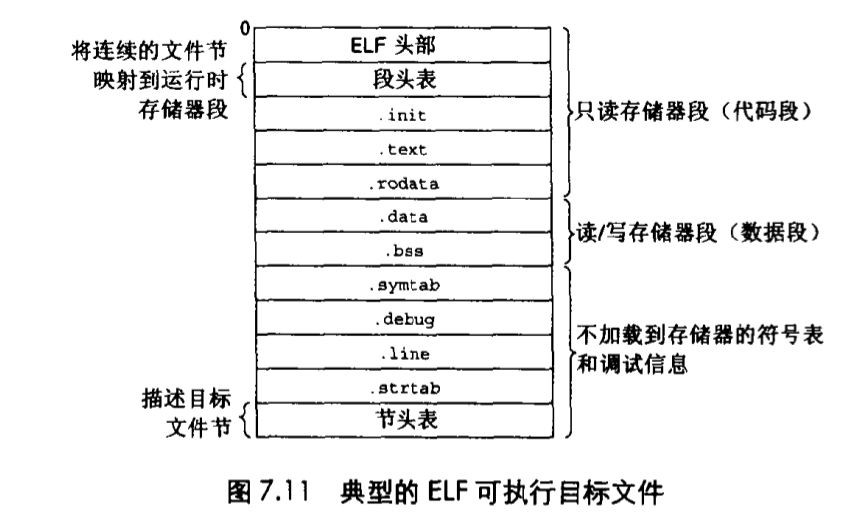
可执行目标文件的格式类似于可重定位目标文件的格式。ELF 头部描述文件的总体格式。它包括程序的入口点(entry point),也就是当程序运行时要执行的第一条指令的地址。.text、.rodata 和 .data 节和可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时存储器地址以外。init 节定义了一个小涵书,叫做 _init,程序的初始化代码会调用它。因为可执行文件是完全链接的(已被重定位了),所以它不再需要 .relo 节。
ELF 可执行文件被设计为很容易加载到存储器,连续的可执行文件的组块(chunks)被映射到连续的存储器段。段头表(segment header table)描述了这种映射关系。下图展示了示例可执行文件 p 的段头表,是由 OBJDUMP 显示的。

从段头表中,看到会根据可执行目标哦文件的内容初始化两个存储器段。
第 1 行和第 2 行告诉我们第一个段(代码段)对齐到一个 4KB(
2
12
2^{12}
212)的边界,有读/执行许可,开始于存储器地址 0x08048000 处,总共的存储器大小是 0x448 字节,并且被初始化为可执行目标文件的头 0x448 个字节,其中包括 ELF 头部、段头表以及 .init、.text 和 .rodata 节。
第 3 行和第 4 行告诉我们第二个段(数据段)被对齐到一个 4KB 的边界,有读/写许可,开始于存储器地址 0x08049448 处,总的存储器大小为 0x104 字节,并用从文件偏移 0x0448 处开始的 0xe8 个字节初始化,在此例中,偏移 0x448 处正是 .data 节的开始。该段中剩下的字节对应于运行时并将被初始化为零的 .bss 数据。
7.9 加载可执行目标文件
要运行可执行目标文件p,可以在 Unix shell 的命令行输入它的名字:
unix> ./p
因为 p 不是一个内置的 shell 命令,所以 shell 会认为 p 是一个可执行目标文件,通过调用某个驻留在存储器中称为加载器(loader)的操作系统代码来为我们运行它。任何 Unix 程序都可以通过调用 execve 函数来调用加载器。加载器将可执行目标文件中的代码和数据从磁盘拷贝到存储器中,然后通过跳转到程序的第 1 条指令,即入口点(entry point)来运行该程序。这个将程序拷贝到存储器并运行的过程叫做加载(loading)。
每个 Unix 程序都有一个运行时存储器映像,如下图所示:
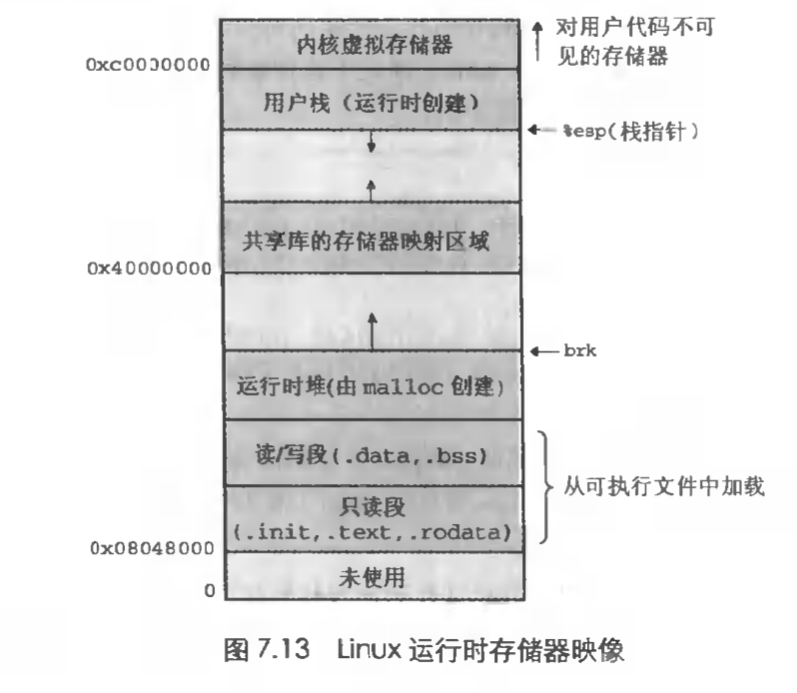
- 在 Linux 系统中,代码段总是从地址
0x08048000处开始。 - 数据段是在接下来的下一个 4KB 对齐的地址处。
- 运行时堆在接下来的读/写段之后的第一个 4KB 对齐的地址处,并通过
malloc库往上增长。 - 开始于地址
0x40000000处的段是为共享库保留的。 - 用户栈总是从地址
0xbfffffff(最大的合法用户地址)处开始的,并向下增长的(向低存储器地址方向增长)。 - 从栈的上部开始于地址
0xc0000000处的段是为操作系统驻留存储器的部分(也就是内核)的代码和数据保留的。
当加载器运行时,它创建如上图所示的存储器映像。在可执行文件中段表头的指导下,加载器将可执行文件的相关内容拷贝到代码和数据段。接下来,加载器跳转到程序的入口点,也就是符号 _start 的地址。在 _start 地址处的启动代码(startup code)是在目标文件 ctrl,o 中定义的,对所有的 C 程序都是一样的。
下图展示了启动代码中特殊的调用序列。

在从 .text 和 .init 节中调用了初始化例程后,启动代码调用 atexit 例程,这个程序附加了一系列在应用调用 exit 函数时应该调用的程序。exit 函数运行 atexit 注册的函数,然后通过调用 _exit 将控制返回给操作系统。接着,启动代码调用应用程序的 main 程序,这就开始执行我们的 C 代码了。在应用程序返回之后,启动代码调用 _exit 程序,它将控制返回给操作系统。
加载器实际上是如何工作的?
概述:
- Unix 系统中的每个程序都运行在一个进程上下文中,这个进程上下文有自己的虚拟地址空间。
- 当 shell 运行一个程序时,父 shell 进程生成一个子进程,它是父进程的一个复制品。
- 子进程通过
execve系统调用启动加载器。加载器删除子进程已有的虚拟存储器段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。通过将虚拟地址空间中的页映射到可执行文件的页大小的组块(chunks),新的代码和数据段被初始化为可执行文件的内容。- 最后,加载器跳转到
_start地址,它最终会调用应用的main函数。- 除了一些头部信息,在加载过程中没有任何从磁盘到存储器的数据拷贝。直到 CPU 引用一个被映射的虚拟页,才会进行拷贝,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到存储器。