微服务
1、zookeeper
1.1Zookeeper的功能
1.1.1命名服务
命名服务是分布式系统最基本的公共服务之一。在分布式系统中,被命名的实体通常可以是集群中的机器、提供的服务地址或远程对象等一一这些我们都可以通称他们为名字(Name),通过命名服务,客户端应用能够根据指定名字来获取资源的实体、服务地址和提供者的信息等。
1.1.2.Zookeeper数据模型
- 构成zookeeper集群的主机,称之为主机节点
- 指内存中的zookeeper数据模型中的数据单元,用来存储各种数据内容,称之为数据节点。
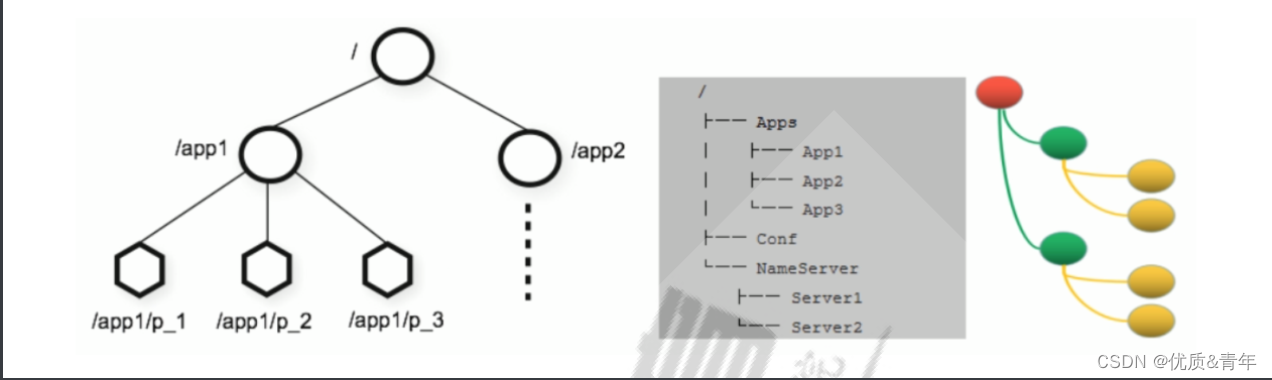
Zookeeper内部维护了一个层次关系(树状结构)的数据模型,它的表现形式类似于Linux的文件系统,甚至操
作的种类都一致。
Zookeeper数据模型中有自己的根目录(/),根目录下有多个子目录,每个子目录后面有若干个文件,由斜杠
(/)进行分割的路径,就是一个ZNode,每个 ZNode上都会保存自己的数据内容和一系列属性信息.
1.1.3状态同步
每个节点除了存储数据内容和node节点状态信息除外,还存储了已经注册的APP的状态信息,当有些节点或APP不可用就将当前状态同步给其他服务
1.1.4配置中心
现在我们大多数应用都是采用的是分布式开发的应用,搭建到不同的服务器上,我们的配置文件,同一
个应用程序的配置文件一样,还有就是多个程序存在相同的配置,当我们配置文件中有个配置属性需要
改变,我们需要改变每个程序的配置属性,这样会很麻烦的去修改配置,那么可用使用ZooKeeper 来实
现配置中心, ZooKeeper 采用的是推拉相结合的方式:客户端向服务端注册自己需要关注的节点,一旦
该节点的数据发生变更,那么服务端就会向相应的客户端发送Watcher事件通知,客户端接收到这个消
息通知后,需要主动到服务端获取最新的数据。
1.1.5集群管理
Zookeeper两大特性:
- 客户端如果对zookeeper的数据节点注册监听,那么该数据节点的内容或者是其子节点列表发生变更时,Zookeeper服务器就会向已注册订阅的客户端发送变更通知。
- 对在Zookeeper上创建的临时节点,一旦客户端与服务器之间的会话失效,那么该节点也就会被自动清楚。
Watch(事件监听器)是Zookeeper中的一个很重要的特性。Zookeeper允许用户在指定的节点上注册一些Watcher,并且在一些特定事件触发的时候,Zookeeper服务端会将事件通知到感兴趣的客户端上去,该机制是Zookeeper实现分布式协调服务的重要特性。
1.2Zookeeper的服务流程
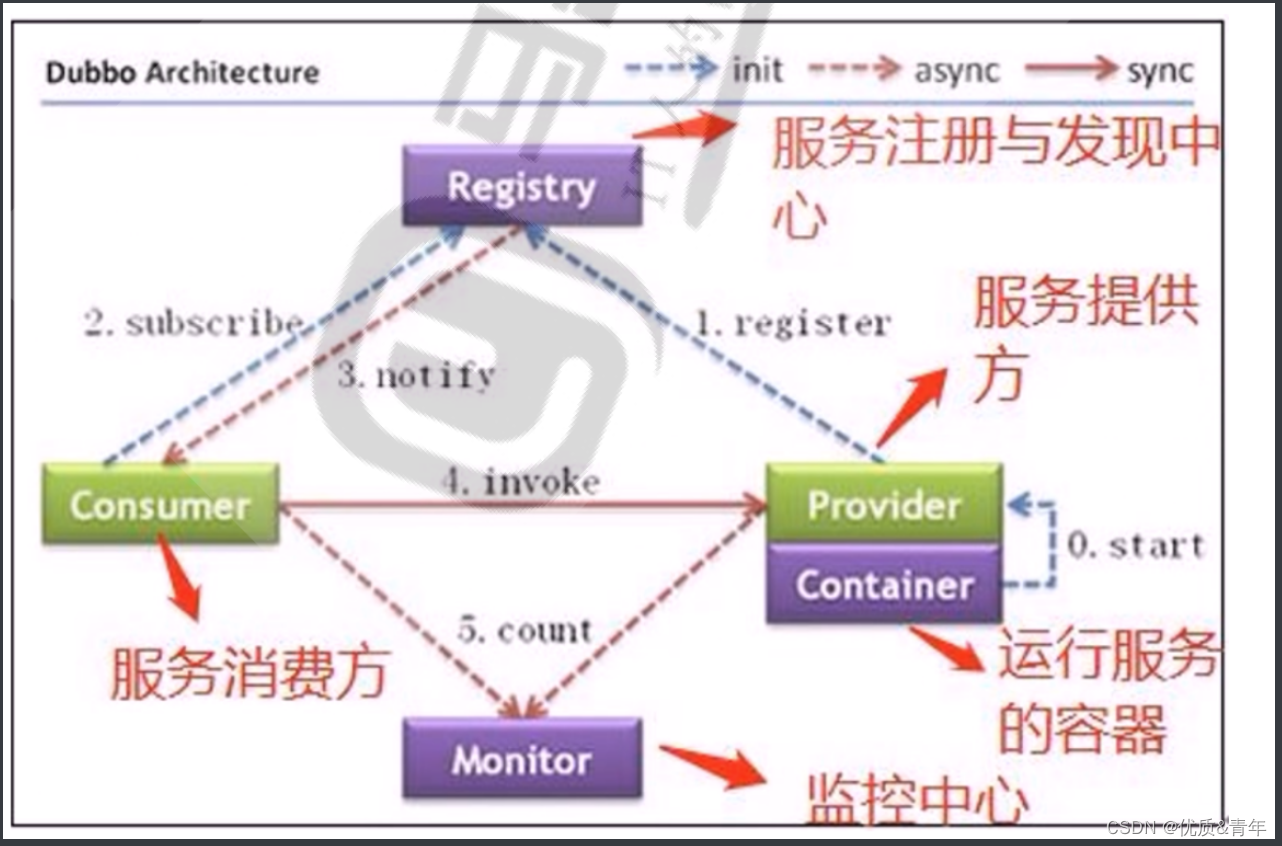
- 生产者启动并注册至Zookeeper
- 消费者启动并订阅频道
- zookeeper通知消费者事件
- 消费者调用生产者
- 监控中心负责统计和监控服务的状态
1.3部署zookeeper集群
1.3.1 集群的介绍
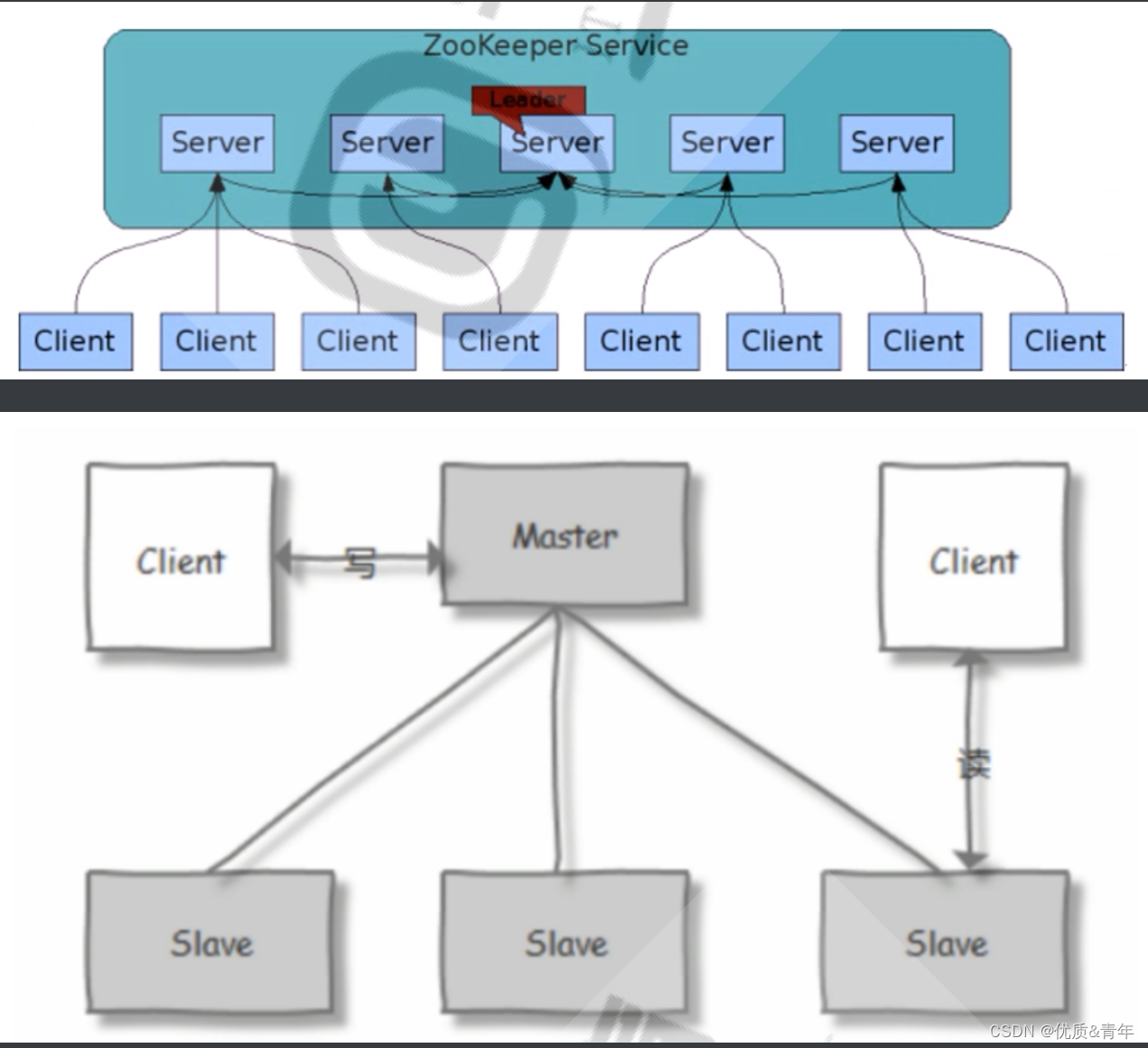
zookeeper集群基于Master/Slave的模型,处于主要地位(处理写操作)的主机称为Master节点,处于次要
地位(处理读操作)的主机称为 slave节点,生产中读取的方式一般是以异步复制方式来实现的。
对于n台server,每个server都知道彼此的存在。只要有>n/2台server节点可用,整个zookeeper系统保
持可用。
因此zookeeper集群通常由奇数台Server节点组成
当进行写操作时,由leader完成,并且同步到其它follower节点,当在保证写操作在所有节点的总数过半后,
才会认为写操作成功
1.3.2 集群角色
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ys9k86YH-1684221517590)(C:\Users\wengsq\AppData\Roaming\Typora\typora-user-images\1684203676157.png)]
- leader:负责处理写入请求的,事务请求的唯一调度和处理者,负责进行投票发起和决议,更新系统状态
- follower:接受客户端请求并向客户端返回结果,在leader过程中参与投票
- Observe:转交客户端写请求给leader节点,和同步leader状态和follower唯一区别就是不参与Leader投票也不参与写操作的策略
- learner:和Leader进行同步状态的节点统称为learner,包括:Follower和Observer
- 客户端:请求发起方
选举Leader的依据:
- ZXID(zookeeper transaction id):每个改变 Zookeeper状态的操作都会形成一个对应的zxid。
ZXID最大的节点优先选为Leader - myid:服务器的唯一标识(SID),通过配置 myid 文件指定,集群中唯一,当ZXID一样时,myid大的节
点优先选为Leader
1.3.3zookeeper的端口
2181:对cline端提供服务
3888:选举leader使用
2888:集群内机器通讯使用(Leader监听此端口)
1.3.4配置文件
tickTime=2000 #服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
initLimit=10 #集群中leader 服务器与follower服务器初始连接心跳次数,即多少个 2000 毫秒
syncLimit=5 #leader 与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果该
follower在设置的时间内(5*2000)不能与 leader 进行通信,那么此 follower将被视为不可用。
dataDir=/usr/local/zookeeper/data #自定义的zookeeper保存数据的目录
clientPort=2181 #客户端连接 Zookeeper 服务器的端口,Zookeeper会监听这个端口,接受客户端的
访问请求
maxClientCnxns=128 #单个客户端IP 可以和zookeeper保持的连接数
autopurge.snapRetainCount=3 #3.4.0中的新增功能:启用后,ZooKeeper 自动清除功能,会将只保
留此最新3个快照和相应的事务日志,并分别保留在dataDir 和dataLogDir中,删除其余部分,默认值为3,
最小值为3
autopurge.purgeInterval=24 #3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参
数指定了清理频率,单位是小时,需要配置一个1或更大的整数,默认是 0,表示不开启自动清理功能
2.4.2.4 在各个节点生成ID文件
注意: 各个myid文件的内容要和zoo.cfg文件相匹配
2.4.2.5 各服务器启动 zookeeper
2.4.5.6 查看集群状态
#格式: server.服务器唯一编号=服务器IP:Leader和Follower的数据同步端口(只有leader才会打
开):Leader和Follower选举端口(L和F都有)
server.1=10.0.0.101:2888:3888
server.2=10.0.0.102:2888:3888
server.3=10.0.0.103:2888:3888
#如果添加节点,只需要在所有节点上添加新节点的上面形式的配置行,在新节点创建myid文件,并重启所有节
点服务即可
1.3.5集群安装脚本
#!/bin/bash
ZK_VERSION=3.7.1
ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/apache-zookeeper-${ZK_VERSION}-bin.tar.gz"
NODE1=172.17.8.101
NODE2=172.17.8.102
NODE3=172.17.8.103
. /etc/os-release
HOST=`hostname -I|awk '{print $1}'`
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
zk_myid () {
read -p "请输入node编号(默认为 1): " MYID
if [ -z "$MYID" ] ;then
MYID=1
elif [[ ! "$MYID" =~ ^[0-9]+$ ]];then
color "请输入正确的node编号!" 1
exit
else
true
fi
}
install_jdk() {
if [ $ID = 'centos' -o $ID = 'rocky' ];then
yum -y install java-1.8.0-openjdk-devel || { color "安装JDK失败!" 1; exit 1; }
else
apt update
apt install openjdk-8-jdk -y || { color "安装JDK失败!" 1; exit 1; }
fi
java -version
}
install_zookeeper() {
wget -P /usr/local/src/ $ZK_URL || { color "下载失败!" 1 ;exit ; }
tar xf /usr/local/src/${ZK_URL##*/} -C /usr/local
ln -s /usr/local/apache-zookeeper-*-bin/ /usr/local/zookeeper
echo 'PATH=/usr/local/zookeeper/bin:$PATH' > /etc/profile.d/zookeeper.sh
. /etc/profile.d/zookeeper.sh
mkdir -p /usr/local/zookeeper/data
echo $MYID > /usr/local/zookeeper/data/myid
cat > /usr/local/zookeeper/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/local/zookeeper/data
clientPort=2181
maxClientCnxns=128
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
server.1=${NODE1}:2888:3888
server.2=${NODE2}:2888:3888
server.3=${NODE3}:2888:3888
EOF
cat > /lib/systemd/system/zookeeper.service <<EOF
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=forking
#Environment=/usr/local/zookeeper
ExecStart=/usr/local/zookeeper/bin/zkServer.sh start
ExecStop=/usr/local/zookeeper/bin/zkServer.sh stop
ExecReload=/usr/local/zookeeper/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now zookeeper.service
systemctl is-active zookeeper.service
if [ $? -eq 0 ] ;then
color "zookeeper 安装成功!" 0
else
color "zookeeper 安装失败!" 1
exit 1
fi
}
read -p "请输入node编号(默认为 1): " MYID
if [ -z "$MYID" ] ;then
MYID=1
elif [[ ! "$MYID" =~ ^[0-9]+$ ]];then
color "请输入正确的node编号!" 1
exit
else
true
fi
install_jdk
install_zookeeper
2、kafka
2.1消息队列
概念:消息队列(MQ)是构建分布式互联网应用的基础设施,通过MQ实现松耦合架构设计可以提高系统可用性以及可扩展性,适用于现代应用的最佳设计方案。MQ是一种异步服务间的通信方式,适用于无服务器和微服务架构。消息在被处理和删除之前一直存储在队列上。每一条消息仅可被一位用户处理一次。消息队列可被用于分离重量级处理、缓冲或批处理工作以及缓解高峰期工作负载。
2.2常用消息队列的对比
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DgFBhxP7-1684221517591)(C:\Users\wengsq\AppData\Roaming\Typora\typora-user-images\1684205686716.png)]
2.2.1kafka的特点和优势
特点:
- 分布式:多机实现,不允许单机
- 分区:一个消息可以拆分出多个,分别储存在多个位置
- 多副本:防止信息丢失,可以多个备份
- 多订阅者:可以有很多应用连接kafka
优势:
- Kafka 通过 O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以 TB 级别以上的消息存
储也能够保持长时间的稳定性能。 - 高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。支持通过Kafka 服务器分
区消息。 - 分布式: Kafka 基于分布式集群实现高可用的容错机制,可以实现自动的故障转移
- 顺序保证:在大多数使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并
且能保证数据会按照特定的顺序来处理。 Kafka保证一个Partiton内的消息的有序性(分区间数据
是无序的,如果对数据的顺序有要求,应将在创建主题时将分区数partitions设置为1) - 支持 Hadoop 并行数据加载
- 通常用于大数据场合,传递单条消息比较大,而Rabbitmq 消息主要是传输业务的指令数据,单条数据
较小
2.2.3kafka的角色
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8ylitSIH-1684221517591)(C:\Users\wengsq\AppData\Roaming\Typora\typora-user-images\1684205996522.png)]
Producer:Producer即生产者,消息的产生者,是消息的入口。负责发布消息到Kafka broker。
Consumer:消费者,用于消费消息,即处理消息
Consumer group: 每个consumer 属于一个特定的consumer group(可为每个consumer 指定 group
name,若不指定 group name 则属于默认的group)
Broker:Broker是kafka实例,每个服务器上可以有一个或多个kafka的实例,假设每个broker对应一
台服务器。每个kafka集群内的broker都有一个不重复的编号,如: broker-0、broker-1等
Topic :消息的主题,可以理解为消息的分类,相当于Redis的Key和ES中的索引,kafka的数据就保存
在topic。在每个broker上都可以创建多个topic。物理上不同 topic 的消息分开存储在不同的文件夹,逻
辑上一个 topic的消息虽然保存于一个或多个broker 上, 但用户只需指定消息的topic即可生产或消费数
据而不必关心数据存于何处,topic 在逻辑上对record(记录、日志)进行分组保存,消费者需要订阅相应
的topic 才能消费topic中的消息。

2.2.3分区的优势
- 实现存储空间的横向扩容,即将多个kafka服务器的空间结合利用
- 提升性能,多服务器多写
- 实现高可用,分区Leader分布在不同的kafka服务器,假设分区因子为 3, 分区 0 的leader为服务
器A,则服务器 B 和服务器 C 为 A 的follower,而分区 1 的leader为服务器B,则服务器 A 和C 为
服务器B 的follower,而分区 2 的leader 为C,则服务器A 和 B 为C 的follower。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hvbC6dQj-1684221517591)(C:\Users\wengsq\AppData\Roaming\Typora\typora-user-images\1684206279363.png)]
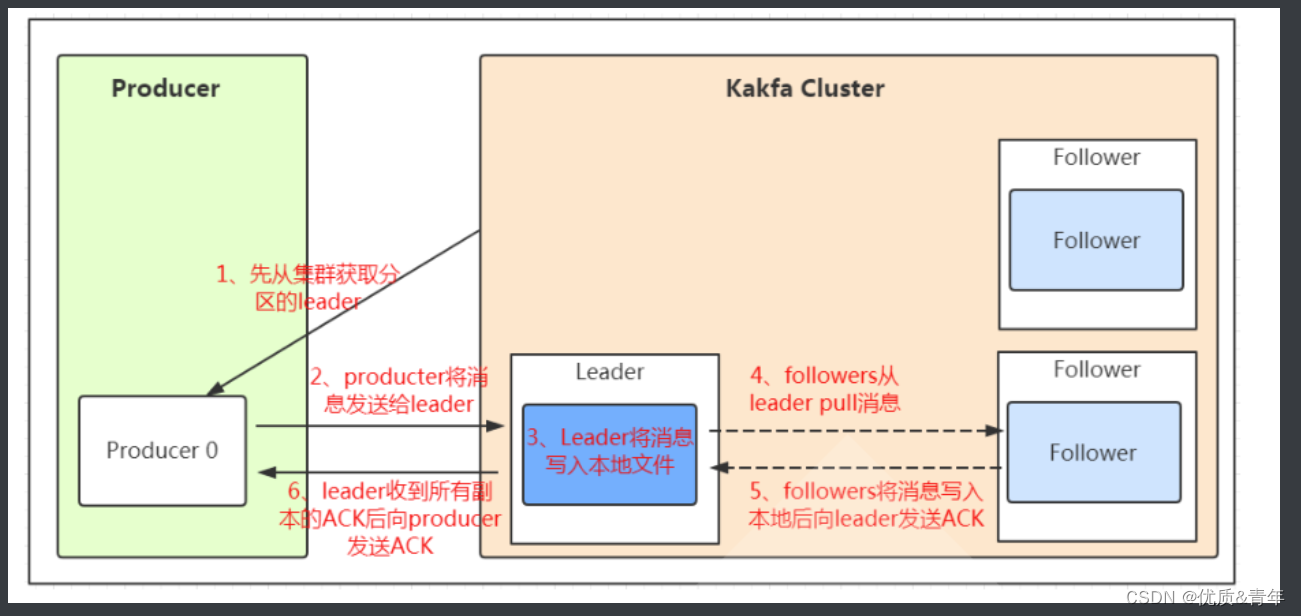
2.3kafka写入消息的流程
2.3.1kafka的配置文件
#配置文件 ./conf/server.properties内容说明
############################# Server Basics###############################
# broker的id,值为整数,且必须唯一,在一个集群中不能重复
broker.id=1
############################# Socket ServerSettings ######################
# kafka监听端口,默认9092
listeners=PLAINTEXT://10.0.0.101:9092
# 处理网络请求的线程数量,默认为3个
num.network.threads=3
# 执行磁盘IO操作的线程数量,默认为8个
num.io.threads=8
# socket服务发送数据的缓冲区大小,默认100KB
socket.send.buffer.bytes=102400
# socket服务接受数据的缓冲区大小,默认100KB
socket.receive.buffer.bytes=102400
# socket服务所能接受的一个请求的最大大小,默认为100M
socket.request.max.bytes=104857600
############################# Log Basics###################################
# kafka存储消息数据的目录
log.dirs=../data
# 每个topic默认的partition
num.partitions=1
# 设置副本数量为3,当Leader的Replication故障,会进行故障自动转移。
default.replication.factor=3
# 在启动时恢复数据和关闭时刷新数据时每个数据目录的线程数量
num.recovery.threads.per.data.dir=1
############################# Log FlushPolicy #############################
# 消息刷新到磁盘中的消息条数阈值
log.flush.interval.messages=10000
# 消息刷新到磁盘中的最大时间间隔,1s
log.flush.interval.ms=1000
############################# Log RetentionPolicy #########################
# 日志保留小时数,超时会自动删除,默认为7天
log.retention.hours=168
# 日志保留大小,超出大小会自动删除,默认为1G
#log.retention.bytes=1073741824
范例:
# 日志分片策略,单个日志文件的大小最大为1G,超出后则创建一个新的日志文件
log.segment.bytes=1073741824
# 每隔多长时间检测数据是否达到删除条件,300s
log.retention.check.interval.ms=300000
############################# Zookeeper ####################################
# Zookeeper连接信息,如果是zookeeper集群,则以逗号隔开
zookeeper.connect=10.0.0.101:2181,10.0.0.102:2181,10.0.0.103:2181
# 连接zookeeper的超时时间,6s
zookeeper.connection.timeout.ms=6000
2.3.2kafka的安装
kafka 基于scala语言实现,所以使用kafka需要指定scala的相应的版本.kafka 为多个版本的Scala构建。这
仅在使用 Scala 时才重要,并且希望为使用的相同 Scala 版本构建一个版本。否则,任何版本都可以
#!/bin/bash
KAFKA_VERSION=3.2.3
SCALA_VERSION=2.12
KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/${KAFKA_VERSION}/kafka_${SCALA_VERSION}-${KAFKA_VERSION}.tgz"
#KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.8.1/kafka_2.13-2.8.1.tgz"
#KAFKA_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz"
ZK_VERSOIN=3.6.3
ZK_URL="https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/stable/apache-zookeeper-${ZK_VERSOIN}-bin.tar.gz"
ZK_INSTALL_DIR=/usr/local/zookeeper
KAFKA_INSTALL_DIR=/usr/local/kafka
NODE1=172.17.8.101
NODE2=NODE1=172.17.8.102
NODE3=NODE1=172.17.8.103
HOST=`hostname -I|awk '{print $1}'`
. /etc/os-release
color () {
RES_COL=60
MOVE_TO_COL="echo -en \\033[${RES_COL}G"
SETCOLOR_SUCCESS="echo -en \\033[1;32m"
SETCOLOR_FAILURE="echo -en \\033[1;31m"
SETCOLOR_WARNING="echo -en \\033[1;33m"
SETCOLOR_NORMAL="echo -en \E[0m"
echo -n "$1" && $MOVE_TO_COL
echo -n "["
if [ $2 = "success" -o $2 = "0" ] ;then
${SETCOLOR_SUCCESS}
echo -n $" OK "
elif [ $2 = "failure" -o $2 = "1" ] ;then
${SETCOLOR_FAILURE}
echo -n $"FAILED"
else
${SETCOLOR_WARNING}
echo -n $"WARNING"
fi
${SETCOLOR_NORMAL}
echo -n "]"
echo
}
install_jdk() {
if [ $ID = 'centos' -o $ID = 'rocky' ];then
yum -y install java-1.8.0-openjdk-devel || { color "安装JDK失败!" 1; exit 1; }
else
apt update
apt install openjdk-8-jdk -y || { color "安装JDK失败!" 1; exit 1; }
fi
java -version
}
zk_myid () {
read -p "请输入node编号(默认为 1): " MYID
if [ -z "$MYID" ] ;then
MYID=1
elif [[ ! "$MYID" =~ ^[0-9]+$ ]];then
color "请输入正确的node编号!" 1
exit
else
true
fi
}
install_zookeeper() {
wget -P /usr/local/src/ $ZK_URL || { color "下载失败!" 1 ;exit ; }
tar xf /usr/local/src/${ZK_URL##*/} -C `dirname ${ZK_INSTALL_DIR}`
ln -s /usr/local/apache-zookeeper-*-bin/ ${ZK_INSTALL_DIR}
echo 'PATH=${ZK_INSTALL_DIR}/bin:$PATH' > /etc/profile.d/zookeeper.sh
. /etc/profile.d/zookeeper.sh
mkdir -p ${ZK_INSTALL_DIR}/data
echo $MYID > ${ZK_INSTALL_DIR}/data/myid
cat > ${ZK_INSTALL_DIR}/conf/zoo.cfg <<EOF
tickTime=2000
initLimit=10
syncLimit=5
dataDir=${ZK_INSTALL_DIR}/data
clientPort=2181
maxClientCnxns=128
autopurge.snapRetainCount=3
autopurge.purgeInterval=24
server.1=${NODE1}:2888:3888
server.2=${NODE2}:2888:3888
server.3=${NODE3}:2888:3888
EOF
cat > /lib/systemd/system/zookeeper.service <<EOF
[Unit]
Description=zookeeper.service
After=network.target
[Service]
Type=forking
#Environment=${ZK_INSTALL_DIR}
ExecStart=${ZK_INSTALL_DIR}/bin/zkServer.sh start
ExecStop=${ZK_INSTALL_DIR}/bin/zkServer.sh stop
ExecReload=${ZK_INSTALL_DIR}/bin/zkServer.sh restart
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now zookeeper.service
systemctl is-active zookeeper.service
if [ $? -eq 0 ] ;then
color "zookeeper 安装成功!" 0
else
color "zookeeper 安装失败!" 1
exit 1
fi
}
install_kafka(){
wget -P /usr/local/src $KAFKA_URL || { color "下载失败!" 1 ;exit ; }
tar xf /usr/local/src/${KAFKA_URL##*/} -C /usr/local/
ln -s ${KAFKA_INSTALL_DIR}_*/ ${KAFKA_INSTALL_DIR}
echo PATH=${KAFKA_INSTALL_DIR}/bin:'$PATH' > /etc/profile.d/kafka.sh
. /etc/profile.d/kafka.sh
cat > ${KAFKA_INSTALL_DIR}/config/server.properties <<EOF
broker.id=$MYID
listeners=PLAINTEXT://${HOST}:9092
log.dirs=${KAFKA_INSTALL_DIR}/data
num.partitions=1
log.retention.hours=168
zookeeper.connect=${NODE1}:2181,${NODE2}:2181,${NODE3}:2181
zookeeper.connection.timeout.ms=6000
EOF
mkdir ${KAFKA_INSTALL_DIR}/data
cat > /lib/systemd/system/kafka.service <<EOF
[Unit]
Description=Apache kafka
After=network.target
[Service]
Type=simple
#Environment=JAVA_HOME=/data/server/java
#PIDFile=${KAFKA_INSTALL_DIR}/kafka.pid
ExecStart=${KAFKA_INSTALL_DIR}/bin/kafka-server-start.sh ${KAFKA_INSTALL_DIR}/config/server.properties
ExecStop=/bin/kill -TERM \${MAINPID}
Restart=always
RestartSec=20
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now kafka.service
#kafka-server-start.sh -daemon ${KAFKA_INSTALL_DIR}/config/server.properties
systemctl is-active kafka.service
if [ $? -eq 0 ] ;then
color "kafka 安装成功!" 0
else
color "kafka 安装失败!" 1
exit 1
fi
}
zk_myid
install_jdk
install_zookeeper
install_kafka
kafka、Zookeeper、Dubbo知道怎么搭建就可以就可以了,集群脚本一跑,去刷个三分钟抖音回来就好了