文章目录
- 一、介绍
- 二、Visualizers
- 2.1 Classification Visualization
- 2.2 Clustering Visualization
- 2.3 Feature Visualization
- 2.4 Model Selection Visualization
- 2.5 Regression Visualization
- 2.6 Target Visualization
- 2.7 Text Visualization
一、介绍
首先是包的安装过程:
pip install --user yellowbrick
Yellowbrick 是一套视觉分析和诊断工具,旨在通过 scikit-learn 促进机器学习。
该库实现了一个新的核心 API 对象,Visualizer,它是一个 scikit-learn 估计器—一个从数据中学习的对象。
与转换器或模型类似,可视化工具通过创建模型选择工作流程的可视化表示来从数据中学习。
Visualizer 允许用户引导模型选择过程,围绕特征工程、算法选择和超参数调整建立直觉。
例如,它们可以帮助诊断围绕模型复杂性和偏差、异方差性、欠拟合和过度训练或类别平衡问题的常见问题。
通过将可视化工具应用于模型选择工作流程,Yellowbrick 允许您更快地引导预测模型获得更成功的结果。
完整的文档可以在 scikit-yb.org 上找到,其中包括面向新用户的快速入门指南。
二、Visualizers
可视化工具是估算器—从数据中学习的对象—其主要目标是创建可视化效果,以便深入了解模型选择过程。
在 scikit-learn 术语中,它们在可视化数据空间时类似于转换器,或者包装类似于 ModelCV(例如 RidgeCV、LassoCV)方法工作方式的模型估计器。
Yellowbrick 旨在创建一个类似于 scikit-learn 的敏感 API。 我们最受欢迎的一些可视化工具包括:
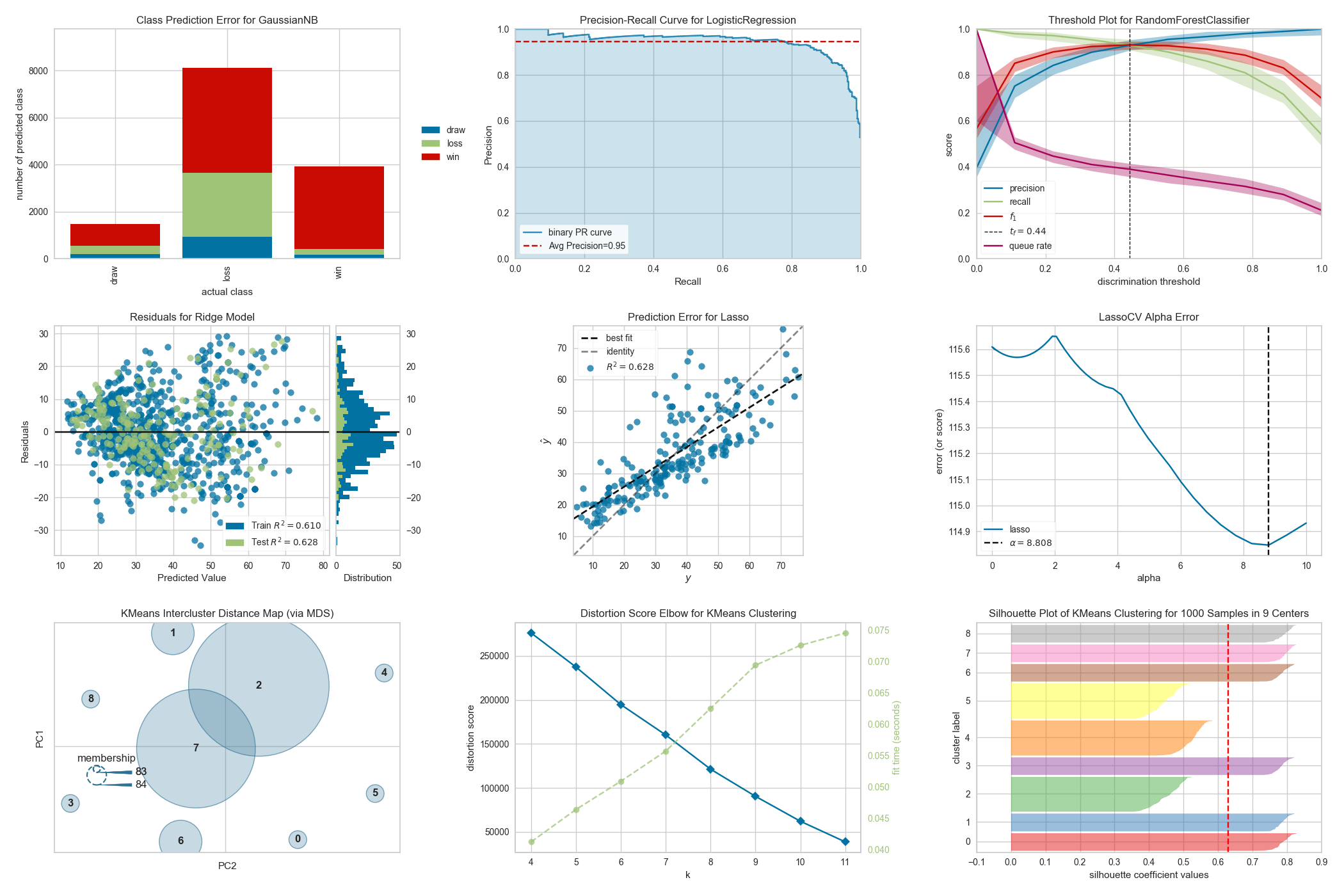
2.1 Classification Visualization
- Classification Report:一个视觉分类报告,以热图的形式显示模型的精度、召回率和 F1 每类分数;
- Confusion Matrix:多类分类中类对混淆矩阵的热图视图;
- Discrimination Threshold:精度、召回率、F1 分数和排队率相对于二元分类器的辨别阈值的可视化;
- Precision-Recall Curve:绘制不同概率阈值的精度与召回分数;
- ROC / AUC:绘制接受者操作特征 (ROC) 和曲线下面积 (AUC)。
2.2 Clustering Visualization
- Intercluster Distance Maps:可视化集群的相对距离和大小;
- KElbow Visualizer:根据指定的评分函数可视化集群,寻找曲线中的“弯头”。
- Silhouette Visualizer:通过可视化单个模型中每个簇的轮廓系数分数来选择 k。
2.3 Feature Visualization
- Manifold Visualization:具有流形学习的高维可视化;
- Parallel Coordinates: 实例的水平可视化;
- PCA Projection:基于主成分的实例投影;
- RadViz Visualizer:围绕圆形图分离实例;
- Rank Features:特征的单一或成对排序以检测关系。
2.4 Model Selection Visualization
- Cross Validation Scores:将交叉验证分数显示为条形图,平均分数绘制为水平线;
- Feature Importances:根据模型内性能对特征进行排名;
- Learning Curve:显示模型是否可以从更多数据或更少复杂性中受益;
- Recursive Feature Elimination:根据重要性找到最好的特征子集;
- Validation Curve:根据单个超参数调整模型。
2.5 Regression Visualization
- Alpha Selection:显示 alpha 的选择如何影响正则化;
- Cook’s Distance:显示实例对线性回归的影响;
- Prediction Error Plots:沿目标域查找模型故障;
- Residuals Plot:显示训练和测试数据的残差差异。
2.6 Target Visualization
- Balanced Binning Reference:生成带有垂直线的直方图,显示建议值点将 bin 数据放入均匀分布的 bin 中;
- Class Balance:通过以条形图形式显示每个类出现的频率,显示训练数据和测试数据中每个类的支持关系 类在数据集中的表示频率;
- Feature Correlation:可视化因变量和目标之间的相关性。
2.7 Text Visualization
- Dispersion Plot:可视化关键术语如何分散在整个语料库中;
- PosTag Visualizer:绘制整个标记语料库中不同词性的计数;
- Token Frequency Distribution:可视化语料库中术语的频率分布;
- t-SNE Corpus Visualization:使用随机邻居嵌入来投影文档;
- UMAP Corpus Visualization:将相似的文档更靠近地绘制在一起以发现集群。










![[OOD设计] - 电梯系统设计](https://img-blog.csdnimg.cn/696c3dab2a584c27872af573b4278a6f.png)