这里写自定义目录标题
- 1. 前言
- 2 为什么需要内存一致性(Memory Consistency)模型
- 3. 什么是内存一致性(Memory Consistency)模型
- 4. 各种内存一致性(Memory Consistency)模型
- 4.1 顺序一致性(SC: Sequential Consistency)模型
- 4.2 完全存储定序(TSO: Total Store Order)模型
- 4.3 部分存储定序(PSO: Part Store Order)模型
- 4.4 宽松存储(RMO: Relax Memory Order)模型
- 5. 内存屏障(memory barrier)
- 6. 参考资料
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2 为什么需要内存一致性(Memory Consistency)模型
从硬件的角度来看,最初对内存的访问过程大概是这样:
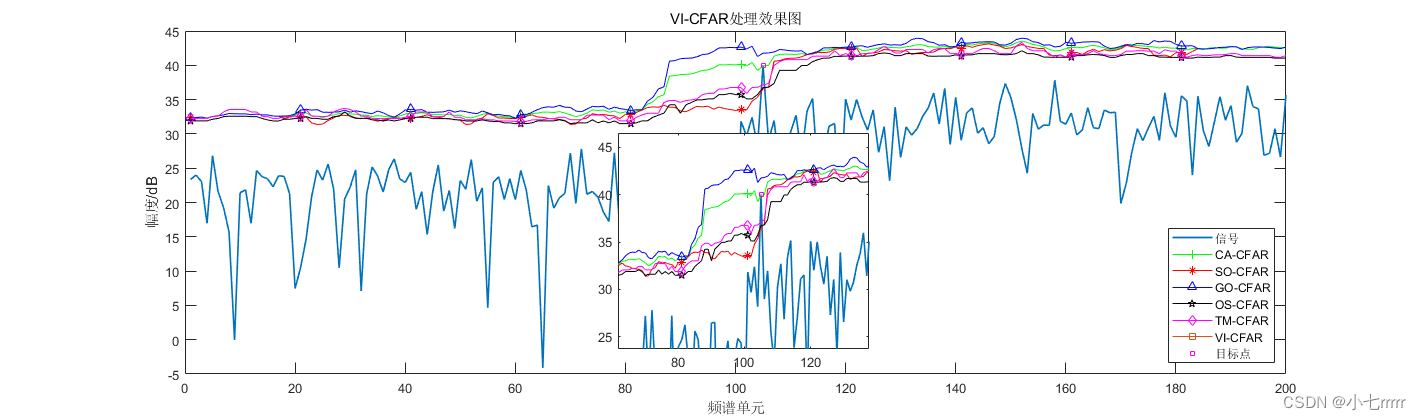
CPU <--> 内存相对于 CPU 的执行频率,直接访问内存速度较慢。于是引入存储速度比内存更快但更贵更小容量的 CPU cache ,用于缓存最近访问的内存数据,硬件拓扑结构如下图(不考虑多级 cache 情形):
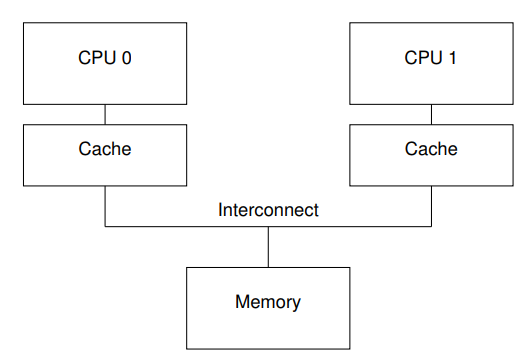
于是访问内存的过程变成了这样:
1. cahce 命中,直接从 cache 中读取
CPU <--> CPU cache
2. cahce 未命中,从内存加载到 cache ,再从 cache 读取
CPU <--> CPU cache <--> 内存有了 CPU cache,速度上得到了很大提升,但人的追求永无止境,为了更快的速度,在 CPU 和 cache 之间, 又加入了更快更贵更小容量的 store buffer 存储。此时硬件拓扑如下:
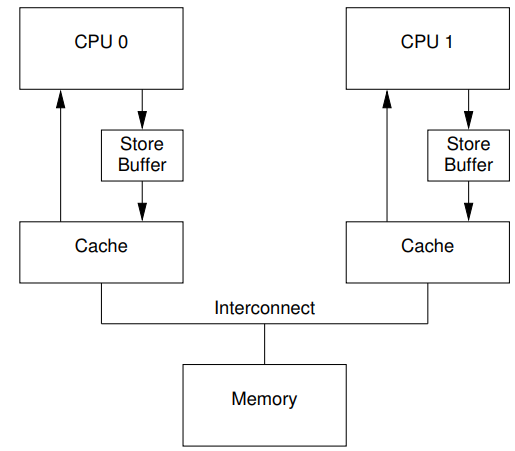
在有 store buffer 缓存的情形下,写操作数据写入到 store buffer ,在需要的时候再写入到 cache 。
说了这么多,这和引入内存一致性模型有什么关系?来看一个例子:假设有两个进程 A 和 B,它们会操作两个相关的变量 g_flag 和 g_var ,g_flag 和 g_var 的初始值均为0;同时进程A绑定到 CPU 0 上执行,进程B绑定到CPU 1上执行,进程A和B的代码分别如下:
/* 进程 A 代码,绑定到 CPU 0 执行 */
g_var = 1;
g_flag = 1;/* 进程 B 代码,绑定到 CPU 1 执行 */
while (g_flag == 0) /* 循环直到 flag != 0 */
;
temp = g_var; /* temp 的值是多少 */在编译器没有优化代码中指令的存储顺序的前提下,请问,进程 B 中变量 temp 的值是多少?答案是:可能是 0 也可能是 1 。在没有给出内存访问上下文时,没法对这个问题进行进一步的讨论。这时候,我们需要内存一致性(Memory Consistency)模型,给出内存访问读写(load/store)顺序的定义(也就是内存访问上下文),才可以再来讨论为什么是这样的答案。
3. 什么是内存一致性(Memory Consistency)模型
内存一致性(Memory Consistency)模型就是对内存读写(load/store)的以下4种顺序进行定义:
store-load
store-store
load-load
load-store以 store-load 来举例,就是说代码中有两条指令,在顺序上,第1条时写指令(store),第2条是读指令(load),内存一致性(Memory Consistency)模型,就是从硬件设计上,是否保证严格按代码中这两条指令的先后顺序进行内存访问。这是什么意思?譬如在后面提到的 TSO(Total Store Order) 模型上下文,可能的执行情况是这样:第1条写指令(store),执行在 CPU 0 上,将变量 var 数据写入到 store buffer ;第2条读指令(load),执行在 CPU 1 上,它去读取变量 var 的数据,而这时候变量 var 的最新数据在 CPU 0 的 store buffer 里面,CPU 1 是无法看到 CPU 0 的 store buffer 的,所以读取的就不是变量 var 的最新值。
4. 各种内存一致性(Memory Consistency)模型
4.1 顺序一致性(SC: Sequential Consistency)模型
所有章节 3 中提到的4种存储操作,严格按照代码顺序执行。在 顺序一致性(SC: Sequential Consistency)模型 下,我们例子中进程 B 中 temp 变量的值最后为 1 。
4.2 完全存储定序(TSO: Total Store Order)模型
章节 3 中提到的4种存储操作,允许 store-load 的写读存储操作乱序,其它操作保序。在 完全存储定序(TSO: Total Store Order)模型 下,我们例子中进程 B 中 temp 变量的值最后可能为 0 或 1 。
4.3 部分存储定序(PSO: Part Store Order)模型
章节 3 中提到的4种存储操作,允许 store-load,store-store 的存储操作乱序,其它操作保序。在 完全存储定序(TSO: Total Store Order)模型 下,我们例子中进程 B 中 temp 变量的值最后可能为 0 或 1 。
4.4 宽松存储(RMO: Relax Memory Order)模型
章节 3 中提到的4种存储操作,允许所有4种操作乱序。在 完全存储定序(TSO: Total Store Order)模型 下,我们例子中进程 B 中 temp 变量的值最后可能为 0 或 1 。
5. 内存屏障(memory barrier)
为了解决内存操作乱序引入的问题,引入了 内存屏障 (memory barrier) 来解决这些问题。如 ARM 的 DMB, DSB, ISB 指令等,更多关于 内存屏障 (memory barrier) 的细节将不在此处展开,感兴趣的读者可查找相关资料。
6. 参考资料
《perfbook.2018.12.08a.pdf》https://zhuanlan.zhihu.com/p/422848235
https://blog.csdn.net/anyegongjuezjd/article/details/125954805