前言
之前写过一篇博文【目标检测】YOLOv5:标签中文显示/自定义颜色,主要从显示端解决目标中文显示的问题。
本文着重从模型角度,从模型端解决目标中文显示问题。
模型信息解析
正常情况下,可以直接加载模型打印信息,不过打印出的模型信息并不完成。
import torch
if __name__ == '__main__':
model = torch.load('weights/best.pt')
print(model)
此时可以通过断点调试的方法查看模型信息。

正常print出来也是这些内容,不过model、opt、git三个字典信息显示不全。
在模型信息中,除了包括了模型的结构参数外,还包括了模型的其它信息,类别信息名称为model/names

检测结果中文显示
因此,如果需要在模型端修改类别为中文信息,只需修改model/names里面的内容
例如,我这里将small-vehicle标签改为中文标签汽车,再保存成一个新的模型。
import torch
if __name__ == '__main__':
model = torch.load('weights/best.pt')
# print(model)
model['model'].names[1] = '汽车'
torch.save(model, "weights/new.pt")
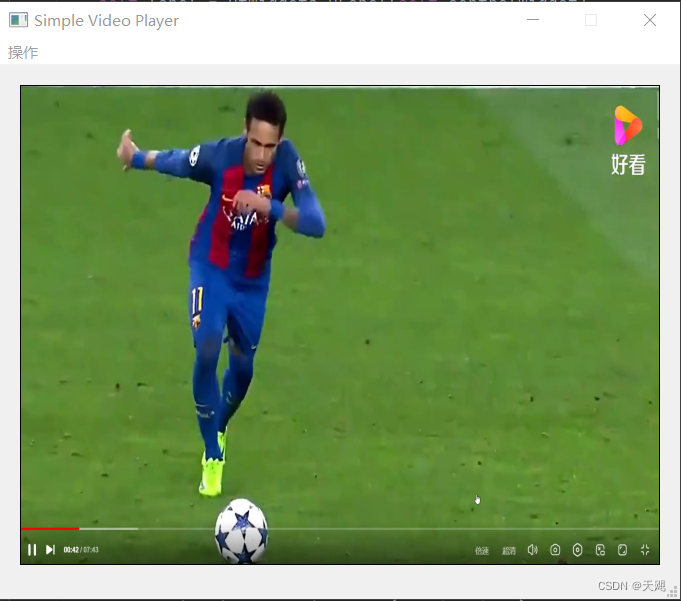
加载新的模型进行检测,可以看到中文标签被完美显示出来:

模型体积压缩
有了上面的经验不难发现,由于考虑到模型需要用于加载训练,因此携带了git、opt等信息,而对于纯推理任务而言,这些信息并不起作用,属于冗余信息。
因此,可以进一步对模型的冗余信息进行剔除,以减少模型的体积,以便在轻量化的设备中部署。
这里以剔除git、opt为例:
if __name__ == '__main__':
model = torch.load('weights/best.pt')
model['git'] = None
model['opt'] = None
torch.save(model, "weights/new.pt")

可以看到,模型在剔除之后,体积变小,且不影响检测任务的运行。