前言:
在我们进行js逆向的时候. 总会遇见一些我们人类无法直接能理解的东西出现. 此时你看到的大多数是被加密过的密文.今天在这里教大家各种加密的逻辑。
Python助学大礼包点击跳转获取
目录
- 一、一切从MD5开始
- 二、URLEncode和Base64
- 三、对称加密
- 四、非对称加密
一、一切从MD5开始
MD5是一个非常常见的摘要(hash)算法… 其特点就是小巧. 速度快. 极难被破解(王小云女士). 所以, md5依然是国内非常多的互联网公司选择的密码摘要算法.
-
这玩意不可逆. 所以. 摘要算法就不是一个加密逻辑.
-
相同的内容计算出来的摘要应该是一样的
-
不同的内容(哪怕是一丢丢丢丢丢不一样) 计算出来的结果差别非常大
在数学上. 摘要其实计算逻辑就是hash.
hash(数据) => 数字
1. 密码
2. 一致性检测
md5的python实现:
from hashlib import md5
obj = md5()
obj.update("alex".encode("utf-8"))
# obj.update("wusir".encode('utf-8')) # 可以添加多个被加密的内容
bs = obj.hexdigest()
print(bs)
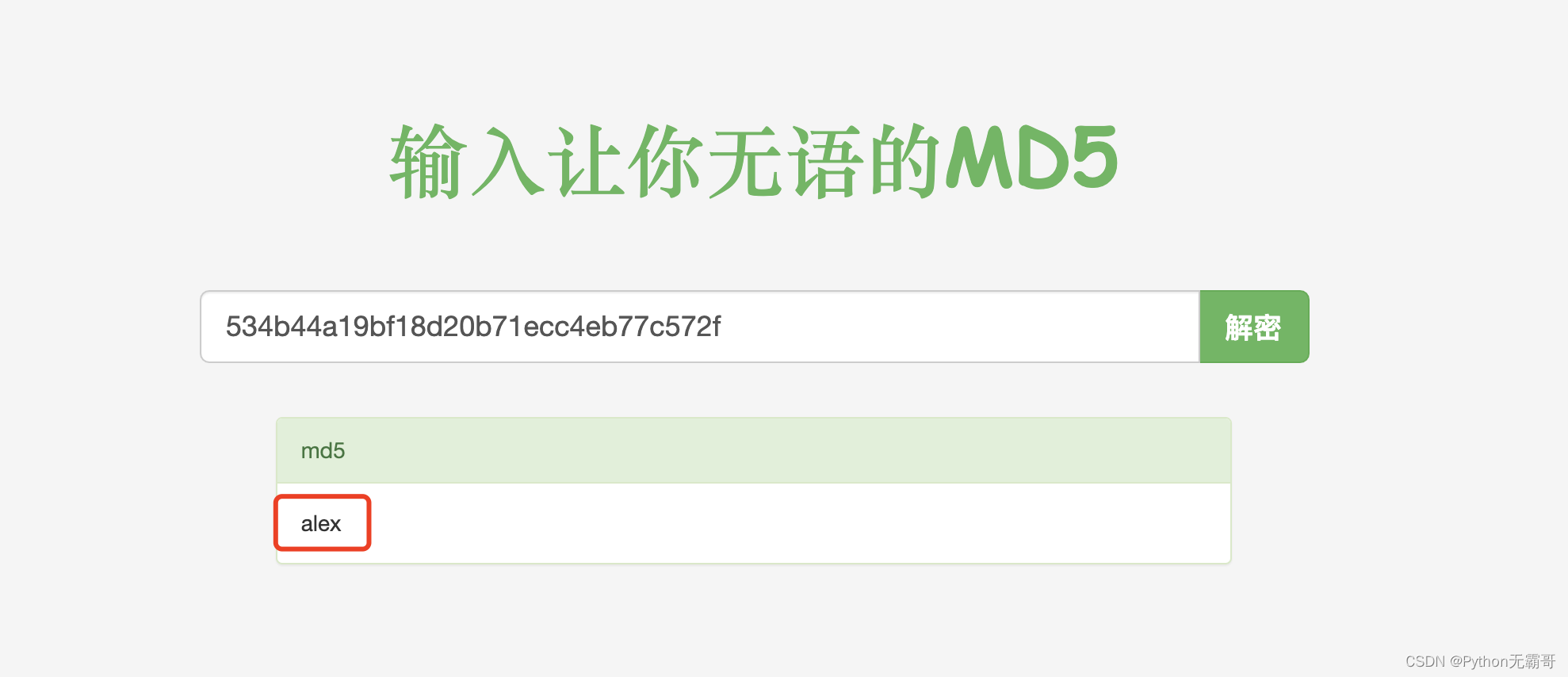
我们把密文丢到网页里. 发现有些网站可以直接解密. 但其实不然. 这里并不是直接解密MD5. 而是"撞库".
就是它网站里存储了大量的MD5的值. 就像这样:
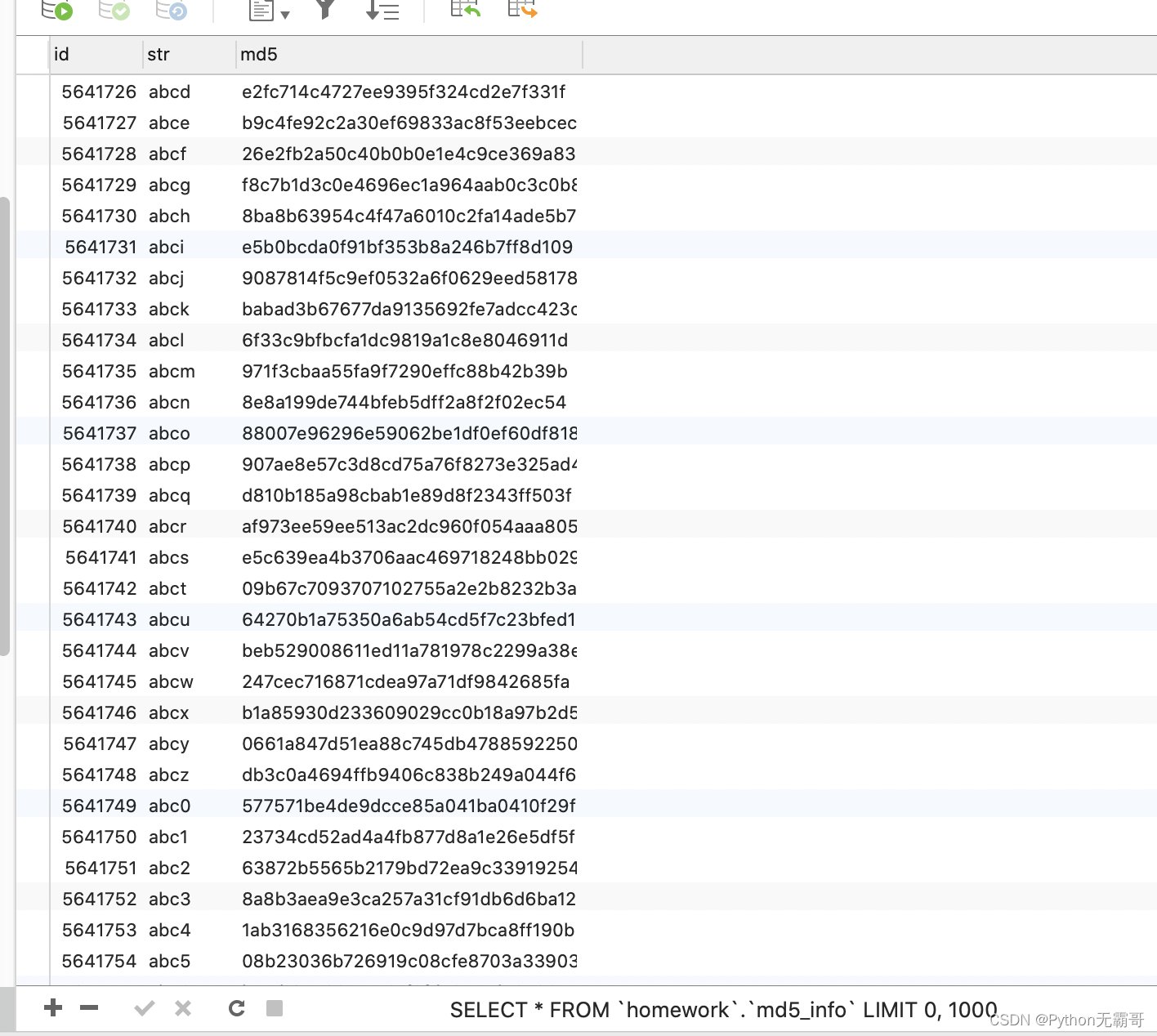
而需要进行查询的时候. 只需要一条select语句就可以查询到了. 这就是传说中的撞库.
如何避免撞库: md5在进行计算的时候可以加盐. 加盐之后. 就很难撞库了.
from hashlib import md5
salt = "我是盐.把我加进去就没人能破解了"
obj = md5(salt.encode("utf-8")) # 加盐
obj.update("alex".encode("utf-8"))
bs = obj.hexdigest()
print(bs)
扩展; sha256
from hashlib import sha1, sha256, sha512
obj = sha512()
obj.update("123456".encode())
mi = obj.hexdigest()
print(mi)
# 7c4a8d09ca3762af61e59520943dc26494f8941b
# https://1024tools.com/hash
# md5 -> 32位 123456 -> e10adc
# sha1 -> 40位 123456 -> 7c
# sha256 -> 64位
# sha512 -> 128位
print(mi.__len__())
不论是sha1, sha256, md5都属于摘要算法. 都是在计算hash值. 只是散列的程度不同而已. 这种算法有一个特性. 他们是散列. 不是加密. 而且, 由于hash算法是不可逆的, 所以不存在解密的逻辑.
# python的标准库hashlib支持各种hash计算
from hashlib import md5
# # 使用方式是固定的
# # 创建一个md5对象
# obj = md5()
# # 把你要计算的东西传递给obj,
# # 需要注意的是, 要计算的内容必须是字节
# obj.update("樵夫".encode("utf-8"))
#
# # 提取md5值
# md5_val = obj.hexdigest()
# print(md5_val)
# a6168d40a27a4eb79039b8350de449e1
# md5的坑
# 1.md5计算的时候. 请注意. obj是一次性的...
# 多次使用, 会产生叠加的效果. 尽量避免...
# 再算一次
# # https://1024tools.com/hash
# obj = md5()
# # 3b286131504399567b29179e7edda37a
# obj.update("樵夫".encode("utf-8"))
# print(obj.hexdigest())
# # 2.md5是不可逆的. 如何解决撞库, 加盐...
# obj = md5(b'abc')
# # obj.update("123456".encode())
# # # obj.update("456789".encode())
# obj.update("3312".encode())
#
# md5_val = obj.hexdigest()
# print(md5_val)
# 加盐到底是个什么逻辑....
# 加了盐, lkjfdsjakl, 明文, 123456
# a007609c07631b0eed91c6495b995a32
# lkjfdsjakl123456
# a007609c07631b0eed91c6495b995a32
# 加盐就是在源字节前面增加一些新的东西.
# obj = md5()
# obj.update(b"abc"+"123456".encode() + b'def')
#
# md5_val = obj.hexdigest()
# print(md5_val)
# 如何看出来js里面用的是md5.
# 在js中运行的过程中, 不经意间,看到了md5字样的东西. -> md5方向去靠拢.
# 并且看到了. 长度是32位的, 16进制的数字的字符串. -> 也可以向md5方向靠拢
# 如何确定100%是md5(标准的)
# 计算123456 => e10adc开头. 大概率就是标准的md5
# 在console里. 计算一下js中的函数, 传递123456 如果计算的结果是e10adc 就可以确定是标准的md5了
# 案例:有道词典
# https://fanyi.youdao.com/index.html#/
'Object(n["a"])(Object(n["a"])({}, e), O(t))'
'n["a"](n["a"](e), O(t))'
"{i: 'god', from: 'auto', to: '', domain: '0', dictResult: true, …}, {sign: 'b93b6c592d96ab4274ce0a51bc747e48', client: 'fanyideskweb', product: 'webfanyi', appVersion: '1.0.0', vendor: 'web', …}"
# t是固定的. 'fsdsogkndfokasodnaso'
# O(t): {sign: '78e61f03b4765afcceb122337662996f', client: 'fanyideskweb', product: 'webfanyi', appVersion: '1.0.0', vendor: 'web', …}
# O有重大作案嫌疑..
# a.d(url, n.a(e, O(t)))
# Object(n["a"])(Object(n["a"])({}, e), O(t))
# 上述代码逻辑, 能记住就记住. 这是特征. 大概率在做合并.
# 90%的概率在合并对象.
# 是否真的是合并. 可以去控制台验证你的猜想.
import time
import requests
t = 'fsdsogkndfokasodnaso'
u = "webfanyi"
# 时间戳
e = str(int(time.time() * 1000))
d = "fanyideskweb"
s = f'client={d}&mysticTime={e}&product={u}&key={t}'
obj = md5()
obj.update(s.encode())
sign = obj.hexdigest()
data = {
"i": "god",
"from": "auto",
"to": "",
"dictResult": "true",
"keyid": "webfanyi",
"sign": sign,
"client": "fanyideskweb",
"product": "webfanyi",
"appVersion": "1.0.0",
"vendor": "web",
"pointParam": "client,mysticTime,product",
"mysticTime": e,
"keyfrom": "fanyi.web",
}
url = "https://dict.youdao.com/webtranslate"
header = {
"Referer": "https://fanyi.youdao.com/",
"Cookie": "OUTFOX_SEARCH_USER_ID=-922898077@10.110.96.160; _ga=GA1.2.50793062.1656497331; OUTFOX_SEARCH_USER_ID_NCOO=1490949463.084894; search-popup-show=11-8",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
}
resp = requests.post(url, data=data, headers=header)
print(resp.text)
# 检测代码是否ok的结果(仅限于该案例)
# 如果正确, 返回的是一个被加密的字符串.
# 如果不正确, 返回的是{"code":1,"msg":"request error"}
二、URLEncode和Base64
在我们访问一个url的时候总能看到这样的一种url
-
python 在这里插入代码片
https://www.sogou.com/web?query=%E5%90%83%E9%A5%AD%E7%9D%A1%E8%A7%89%E6%89%93%E8%B1%86%E8%B1%86&_asf=www.sogou.com&_ast=&w=01019900&p=40040100&ie=utf8&from=index-nologin&s_from=index&sut=3119&sst0=1630994614300&lkt=0%2C0%2C0&sugsuv=1606978591882752&sugtime=1630994614300
此时会发现, 在浏览器上明明是能看到中文的. 但是一旦复制出来. 或者在抓包工具里看到的. 都是这种%. 那么这个%是什么鬼? 也是加密么?
非也, 其实我们在访问一个url的时候. 浏览器会自动的进行urlencode操作. 会对我们请求的url进行编码. 这种编码规则被称为百分号编码. 是专门为url(统一资源定位符)准备的一套编码规则.
一个url的完整组成:
scheme://host:port/dir/file?p1=v1&p2=v2#anchor
http ://www.baidu.com/tieba/index.html?name=alex&age=18
参数: key=value
服务器可以通过key拿value
此时. 如果参数中出现一些特殊符号. 比如’=’ 我想给服务器传递a=b=c这样的参数. 必然会让整个URL产生歧义.
所以, 把url中的参数部分转化成字节. 每字节的再转化成2个16进制的数字. 前面补%.
看着很复杂. 在python里. 直接一步到位
# 一个完整的url是什么样子的
# URL: 统一资源定位符 -> 访问互联网上的某个资源的(电影)
# http://www.baidu.com/
# https://www.baidu.com/
# 协议://域名:端口/虚拟路径/虚拟路径/资源?参数名=参数值&参数名=参数值#锚点
# 域名 -> ip地址
# 端口 -> 应用程序
# 使用http协议. 给百度的服务器上的某个应用程序发送消息.
# 在我们眼里. 服务器 -> 运行在某一台机器上的应用程序.
# 假设需求是访问'樵夫'机器上的`一部电影`
# `协议://域名:端口` 已经可以访问到樵夫的程序了.
# 樵夫的机器上可能会有好多部电影.
# `协议://域名:端口/日韩/2003/天龙八部.html?username=peiqi&password=123456#第五章`
# 如果传递的参数是: 用户名是: `p&1=1`
# `协议://域名:端口/日韩/2003/天龙八部.html?username=p1=1&password=123456#第五章`
# 在url中. 有些符号是不能做为参数.
# 浏览器就发明了一个东西. 叫urlencode. 处理的是url的参数.
# 浏览器会自动的把参数中的内容. 进行urlencode计算.
# 计算的结果. 会把特殊符号(中文)进行转义. 转义成%两位的十六进制数字 (%XX)表示一个字节
# `协议://域名:端口/日韩/2003/天龙八部.html?username=p%4D1%F3&password=123456#第五章`
# 中文 -> 字节(gbk, utf-8) 2-3个字节
# %4D1%F3 => 转化成正常的字符串, 是几个字符?
# python如何进行urlencode
from urllib.parse import quote, unquote, quote_plus, unquote_plus, urlencode
# params = {
# "username": "樵夫"
# }
# # # 只能处理字典. 用不到..
# # ret = urlencode(params)
# # print(ret)
#
# # 上面这个urlencode咱用不到. 因为在requests模块里面. 帮你完成了urlencode
# # requests.get(url, params=params)
# 我们聊它的原因是: 在某些场景下. 需要对cookie的内容进行urlencode.
# 我们一般情况下是: 用正常的cookie进行访问. 也是不需要的. 但是, 有的时候. cookie的某个值是一个b64
# 在传递的时候. 需要对b64字符串进行urlencode操作.才能使用.
# 看不出来...
# 注意, 你计算好的cookie的值.
# 能用就正常用. 用不了的时候. 可以把urlencode作为备选方案.
# # # %E6%A8%B5%E5%A4%AB
# # print(quote("樵夫"))
#
# s = "%E6%A8%B5%E5%A4%AB"
# print(unquote(s)) # 樵夫
# print(quote("a /b/c=", safe="")) # 传递safe="" 可以保持和浏览器一致
# print(quote_plus("a /b/c="))
解码
s = "http://www.baidu.com/s?wd=%E5%A4%A7%E7%8E%8B"
print(unquote(s)) # http://www.baidu.com/s?wd=大王
base64 其实很容易理解. 通常被加密后的内容是字节. 而我们的密文是用来传输的(不传输谁加密啊). 但是, 在http协议里想要传输字节是很麻烦的一个事儿. 相对应的. 如果传递的是字符串就好控制的多. 此时base64就应运而生了. 26个大写字母+26个小写字母+10个数字+2个特殊符号(+和/)组成了一组类似64进制的计算逻辑. 这就是base64了.
# base64:字节转化成字符串的编码规则
# 规则是: 把字节处理成二进制, 进行六个01组合成一个新的字节. 把新的字节处理成十进制.
# 然后去数组中进行映射
# s = b"abc" # =》
# # 011000010110 001001100011
# # 正常字节
# # 01100001 01100010 01100011
# # b64转换
# # 011000 010110 001001 100011
# # 24 22 9 35
# arr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# print(len(arr))
# print(arr[24] + arr[22] + arr[9] + arr[35])
# # YWJj
import base64
bs = "我要吃饭".encode("utf-8")
# 把字节转化成b64
print(base64.b64encode(bs).decode())
# 把b64字符串转化成字节
s = "5oiR6KaB5ZCD6aWt"
print(base64.b64decode(s).decode("utf-8"))
注意, b64处理后的字符串长度. 一定是4的倍数. 如果在网页上看到有些密文的b64长度不是4的倍数. 会报错
例如,
import base64
s = "ztKwrsTj0b0"
bb = base64.b64decode(s)
print(bb)
此时运行出现以下问题
Traceback (most recent call last):
File "D:/PycharmProjects/rrrr.py", line 33, in <module>
bb = base64.b64decode(s)
File "D:\Python38\lib\base64.py", line 87, in b64decode
return binascii.a2b_base64(s)
binascii.Error: Incorrect padding
解决思路. base64长度要求. 字符串长度必须是4的倍数. 填充一下即可
import base64
s = "ztKwrsTj0b0"
s += ("=" * (4 - len(s) % 4))
print("填充后", s)
bb = base64.b64decode(s).decode("gbk")
print(bb)
这里注意
由于标准的Base64编码后可能出现字符+和/,但是这两个字符在URL中就不能当做参数传递,所以就出现了Base64URL,下面是它们的区别:
- Base64编码后出现的+和/在Base64URL会分别替换为-和_
- Base64编码中末尾出现的=符号用于补位,这个字符和queryString中的key=value键值对会发生冲突,所以在Base64URL中=符号会被省略,去掉=后怎么解码呢?因为Base64是把3个字节变为4个字节,所以,Base64编码的长度永远是4的倍数,因此,需要加上=把Base64字符串的长度变为4的倍数,就可以正常解码了。
我们的应对方案:
在处理base64的时候.如果遇到了没有+和/的情况. 可以采用下面的方案来替换掉+和/
b64 = base64.b64decode(mi, b"-_")
# 计算机的底层是 二进制.
# s = "樵夫喜欢唱歌" # 转化成二进制 -> 十进制(十六进制) 数字
# 加密的算法: 数学公式 -> 计算出来的东西一定是乱序的.乱七八糟的样子
# s = 325416545475645676848978464894 => 二进制 => 分组(8bit为一组)byte
# 00001010 10101000 0101011 1111011 0001100 1101100
# 一堆字节. 这堆字节就是计算之后的结果.
# bs = b'\x1a\x03\xa5\xe6\x33' # 转化成字符串. 是很蛋疼的. 没办法转. 乱的
# 网站在进行数据加密的时候.
# 加密完之后的数据需要网络传输....http协议发送字节是很蛋疼的玩意..
# 聪明的程序员发明了base64 可以以最小的代价把字节转化成字符串.
# 转化成字符串之后. 再进行http传输就会方便很多.
# base64:字节转化成字符串的编码规则
# 规则是: 把字节处理成二进制, 进行六个01组合成一个新的字节. 把新的字节处理成十进制.
# 然后去数组中进行映射
# s = b"abc" # =》
# # 011000010110 001001100011
# # 正常字节
# # 01100001 01100010 01100011
# # b64转换
# # 011000 010110 001001 100011
# # 24 22 9 35
# arr = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# print(len(arr))
# # YWJj
# print(arr[24] + arr[22] + arr[9] + arr[35])
# base64的算法就是上面的逻辑
# 作用: 不论多么复杂(混乱)的字节, 都可以转化成`base64的字符串`, 方便数据传输和传递
# 标准库
import base64
# # python完成base64的计算
# b = b"abc"
# # 把字节处理成base64, 再处理成字符串
# r = base64.b64encode(b).decode()
# print(r)
# YWJj
#
# s = "YWJj"
# # 把base64的字符串处理成字节
# bs = base64.b64decode(s)
# print(bs)
"""
字节 => base64.b64encode().decode() => 字符串
字符串 => base64.b64decode() => 字节
"""
# # 特殊情况
# # base64的组成: A-Z a-z 0-9 + / =
# bs = b"\x01\x02\x44\x33\x12110"
# r = base64.b64encode(bs).decode()
# print(r)
# s = 'Z21kD9ZK1ke6ugku2ccWu-MeDWh3z252xRTQv-wZ6jddVo3tJLe7gIXz4PyxGl73nSfLAADyElSjjvrYdCvEP4pfohVVEX1DxoI0yhm36ytQNvu-WLU94qULZQ72aml6gP7DV2OhPDxjE_tACTadwYErIaL4Lvp9yIEN41RmjHKwTXMOBryJIi44zbiIym7iXK1VQoXVl3JTZf-L5yAWo3NPd5ZggpUC3w2KlKT1UOceQab_yqmnIfi1k39rBvuFPmEZOm_wOBX47Pj_tTU0SE_MDSU0mUHEuCtiCsKRngRPsB8j5f7qcV5_tXYnIBt2HffX61Kzq5Myb2QvZzOKtUiJfsPGqxldOQAleM7h2Co8knKyEGq4Z9Tq3hy2KhZiJejbYrZRq7AnasVcQ9N84bRdKbJUNPFmU9pG64N2mBdWKjqyCELQCRZnC0WrHO-um8BSRqoY_uSAbJiHeCypwYGWZm76sRP7EPZtEsrPbiZbMzHYgUJyHtQvJ71krXnh0pzvP3Pub50GJIcwVxNMq1u_VNAKlbhTiFV7bp9KIQ5wudB99OLtXgXdm9XmdGqIAQ60QR0g6WItU5p-FBrqZbiXqBtYq3irV6tljO_JHlsFv1V6pmHS1ZGH2U8U9ndr3bIfeFVZcCE8-rGbTG8O8REczovUUbg1gJj5S72RI-xeShMEnKLJriihW3UtYHjom7chXlGRK5E3kLvT2BuICFLjfKcoNv_NbMJDCr1Qu3VWpMmAd8VdijRK_rmHEPgq3rF158D6DYoHTmc0LENfcfyVgVsSDfyhekeueFnz0UyRdOujXs0XrCDIhui658FZUq-KTv3nRvWOzE3oMQAStqotDA5qp7BA3OYkXiO5zYpDYgR7lSiAPuOnyN3d0ZRJorrEQ-dWJWgkdhbVEdp_fGke7vUAC99Lo90vG1uvN60='
# s1 = s.replace("-", "+").replace("_", "/") # 我们的办法
# bs1 = base64.b64decode(s1)
# bs2 = base64.b64decode(s, b'-_') # 官方的办法来解决
# print(bs1 == bs2)
# # 你写的所有东西. 在计算机底层都是字节. 都可以转化成数字
# s = "樵夫".encode("utf-8")
# print(s)
# # b'\xe6\xa8\xb5\xe5\xa4\xab'
# # 字节还可以被转化成16进制的字符串
# # 每一个字节. 单独处理成一个两位的十六进制的数字
# ss = 'e6a8b5e5a4ab'
# e6a8b5e5a4ab
import binascii
# # 把字节转化成十六进制的数字
# # b: 字节
# # 2: to
# # a: ascii
# # hex十六进制
# r = binascii.b2a_hex(s).decode()
# print(r)
# 把十六进制的数字转化成字节
# s = "e6a8b5e5a4ab"
# bs = binascii.a2b_hex(s)
# print(bs.decode("utf-8"))
# 从m3u8中看到的IV的值: 0x00000000000000000000000000000000
# 这个iv在正常计算的时候是16位的字节.
# 你需要把数字转化成字节
s = '00000000000000000000000000000000'
bs = binascii.a2b_hex(s)
print(bs) # b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
print(len(bs)) # 16
# b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00'
# b'0000000000000000' # 表示空字符
# 0 对应 0x30
print(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00' == b'0000000000000000') # False
三、对称加密
所谓对称加密就是加密和解密用的是同一个秘钥. 就好比. 我要给你邮寄一个箱子. 上面怼上锁. 提前我把钥匙给了你一把, 我一把. 那么我在邮寄之前就可以把箱子锁上. 然后快递到你那里. 你用相同的钥匙就可以打开这个箱子.
条件: 加密和解密用的是同一个秘钥. 那么两边就必须同时拥有钥匙才可以.
常见的对称加密: AES, DES, 3DES. 我们这里讨论AES和DES.
# AES加密
from Crypto.Cipher import AES
"""
长度
16: *AES-128*
24: *AES-192*
32: *AES-256*
MODE 加密模式.
常见的ECB, CBC
以下内容来自互联网~~
ECB:是一种基础的加密方式,密文被分割成分组长度相等的块(不足补齐),然后单独一个个加密,一个个输出组成密文。
CBC:是一种循环模式,前一个分组的密文和当前分组的明文异或或操作后再加密,这样做的目的是增强破解难度。
CFB/OFB:实际上是一种反馈模式,目的也是增强破解的难度。
FCB和CBC的加密结果是不一样的,两者的模式不同,而且CBC会在第一个密码块运算时加入一个初始化向量。
"""
aes = AES.new(b"alexissbalexissb", mode=AES.MODE_CBC, IV=b"0102030405060708")
data = "我吃饭了"
data_bs = data.encode("utf-8")
# 需要加密的数据必须是16的倍数
# 填充规则: 缺少数据量的个数 * chr(缺少数据量个数)
pad_len = 16 - len(data_bs) % 16
data_bs += (pad_len * chr(pad_len)).encode("utf-8")
bs = aes.encrypt(data_bs)
print(bs)
from Crypto.Cipher import AES
aes = AES.new(b"alexissbalexissb", mode=AES.MODE_CBC, IV=b"0102030405060708")
# 密文
bs = b'\xf6z\x0f;G\xdcB,\xccl\xf9\x17qS\x93\x0e'
result = aes.decrypt(bs) # 解密
print(result.decode("utf-8"))
# 安装的是pycrypto或者pycryptodome
# 使用的是Crypto
from Crypto.Cipher import AES
from Crypto.Util.Padding import pad, unpad
import base64
import binascii
ming = "我叫樵夫, 我很大.."
#
# # 1. 创建加密器
# # key, 秘钥, 长度必须是16(最常用), 24, 32位的字节.
# # mode, 加密模式,
# # ECB, 可以没有iv
# # CBC, 需要iv 的
# # iv, 必须在CBC模式下, 长度是16位字节
#
aes = AES.new(key=b'aaaaaaaaaaajjjjj', mode=AES.MODE_CBC, iv=b'uuuuuuuuuuuuuuuu')
#
# # 加密
# # 加密之前,需要对数据进行填充. 不填充会报错
data = pad(ming.encode("utf-8"), 16)
result = aes.encrypt(data)
print(result) # b"\x9fv\xcf\x8f\x8d\xb2i\xff\x03\xaf\x96E\xbd\x13|\x12\xbd\xa5\x8a\x95\x1bi\x9e\x88\xc8:'0\x07u4J"
# # 下面这个处理方案是错误的. 因为加密之后的内容是杂乱无章的字节. 是乱序的. 是无法识别的
# # print(result.decode("utf-8")) # ok 777 不ok 999
# # print(result)
#
#
# # 加密之后的内容想要传输....需要base64, hex
# # b64encode() 把字节进行b64的编码
print(base64.b64encode(result).decode())
#
print(result.hex())
print(binascii.b2a_hex(result).decode())
#
# # base64: n3bPj42yaf8Dr5ZFvRN8Er2lipUbaZ6IyDonMAd1NEo=
# # hex: 9f76cf8f8db269ff03af9645bd137c12bda58a951b699e88c83a27300775344a
# 解密的过程
s = 'n3bPj42yaf8Dr5ZFvRN8Er2lipUbaZ6IyDonMAd1NEo='
# 1.创建解密器.
aes = AES.new(key=b'aaaaaaaaaaajjjjj', mode=AES.MODE_CBC, iv=b'uuuuuuuuuuuuuuuu')
# 2. 把密文处理成字节(看好, 是b64还是hex)
data = base64.b64decode(s)
# 3. 解密
r = aes.decrypt(data)
# 4. 去掉填充
r = unpad(r, 16)
# 5. 还原成字符串.
print(r.decode("utf-8"))
# DES加密解密
from Crypto.Cipher import DES
# key: 8个字节
des = DES.new(b"alexissb", mode=DES.MODE_CBC, IV=b"01020304")
data = "我要吃饭".encode("utf-8")
# # 需要加密的数据必须是16的倍数
# # 填充规则: 缺少数据量的个数 * chr(缺少数据量个数)
pad_len = 8 - len(data) % 8
data += (pad_len * chr(pad_len)).encode("utf-8")
bs = des.encrypt(data)
print(bs)
# 解密
des = DES.new(key=b'alexissb', mode=DES.MODE_CBC, IV=b"01020304")
data = b'6HX\xfa\xb2R\xa8\r\xa3\xed\xbd\x00\xdb}\xb0\xb9'
result = des.decrypt(data)
print(result.decode("utf-8"))
from Crypto.Cipher import DES, AES, DES3
from Crypto.Util.Padding import pad, unpad
import base64
#
# ming = "樵夫喜欢上天"
#
# # DES的key是8个字节
# des = DES.new(key=b'abcdefgh', mode=DES.MODE_CBC, iv=b'uuuuuuuu')
#
# r = des.encrypt(pad(ming.encode("utf-8"), 8))
# r = base64.b64encode(r)
# print(r)
mi = 'KNu/ZVt18Bsi+FTXdNLL1VOL6vPzwWGx'
des = DES.new(key=b'abcdefgh', mode=DES.MODE_CBC, iv=b'uuuuuuuu')
r = des.decrypt(base64.b64decode(mi))
r = unpad(r, 8)
print(r.decode("utf-8"))
四、非对称加密
非对称加密. 加密和解密的秘钥不是同一个秘钥. 这里需要两把钥匙. 一个公钥, 一个私钥. 公钥发送给客户端. 发送端用公钥对数据进行加密. 再发送给接收端, 接收端使用私钥来对数据解密. 由于私钥只存放在接受端这边. 所以即使数据被截获了. 也是无法进行解密的.
常见的非对称加密算法: RSA, DSA等等, 我们就介绍一个. RSA加密, 也是最常见的一种加密方案
RSA加密解密
- 1 创建公钥和私钥
import base64
from Crypto.Cipher import PKCS1_v1_5, AES, DES, DES3 # 导包
from Crypto.PublicKey import RSA # 这个RSA我们看到的样子是 帮我们生成和管理公钥和私钥的...
# # 如何生成公钥和私钥 ....
key = RSA.generate(bits=1024) # 生成私钥
# 生成的key是私钥...
with open("private.pem", mode="wb") as f:
f.write(key.exportKey()) # 导出
# 默认导出的格式是dem格式
# 用私钥可以生成公钥, public_key() 拿到公钥
with open("public.pem", mode="wb") as f:
f.write(key.public_key().exportKey())
print(key.export_key("DER")) # 二进制编码 默认PEM
bs = key.export_key("DER")
import base64
print(base64.b64encode(bs).decode()) # 二进制编码 -> base64处理 -> base64字符串
print(key.export_key("PEM").decode()
.replace("-----BEGIN RSA PRIVATE KEY-----", "")
.replace("-----END RSA PRIVATE KEY-----", "")
.replace("\r", "")
.replace("\n", "")) # 默认文本编码 -> 处理成字符串 -> 去掉头尾及换行符
- 2 加密
from Crypto.Cipher import PKCS1_v1_5 # rsa加密
from Crypto.PublicKey import RSA # 加载key的
import base64
ming = "我喜欢上天"
# 导入的key可以是pem格式的秘钥, 或者是字节形式的秘钥都可以
f = open("rsa_public_key.pem", mode="r", encoding="utf-8")
pub_key = f.read()
f.close()
# 导入key
rsakey = RSA.importKey(pub_key)
# 创建加密器
rsa = PKCS1_v1_5.new(key=rsakey)
# 加密
mi_bs = rsa.encrypt(ming.encode("utf-8"))
mi = base64.b64encode(mi_bs).decode()
print(mi)
# # rsa加密的结果可能会不一样.. 解密的过程如果没问题. 得到的结果是相同的.
# # Cwx01IndwCNkn/aupsWjgSNuGaUgGIYvvIT+cUau8JgNI4ZCQiiJi/cIJQ7tYmcf4TkCeDlgWSM1FlZrB4wPvRi3ivjEZEIa2q0vwM3zm+Hd7gEYh/uRQ9jb8j07uXsXJ5ejvM9Vgm4hSalP8GXbS6f7i9rQea3nTAw9zC70HAoTxUo17YsJRh/bhZcTD8jjflAEpkhsZwpPvQ/LbLai262/5myNaiykIf2RV+VjfxkN8WM5aDcOELA4UQE8Oi9ORh6T1aWVjWH5pLdVmhHsViRtw12tRbVWyyUmOEldggYpDRd3S+mIcRFPcIamiNW7tnkZEg8OkGWKmdVN0xZ9mQ==
# # MblRaFJFIHX0XeI+NUfLDsTmEWWy8seBM4FnPnWztZOcvt9w9OjtgolxqKJyqowczIfzqOlKK72BZWOT3ntPcQqlD6wDI1OhDz7Pp0DWq8xQA16+2Mk7dNeL/zVTt6vhqHNc9R0llQ3UxwIrSSorOzxuxh6YBQWpb+/woMYPjWKQ0MTbgYB8p9aFwNjLbMwHHSChV3yjAydnn30TlZIXC0R4LraJjxGOmz8fbciFmQRq08nv/UVPIzKn0uJzItRGNT65N8mcW3vzq2AOIznoyXWY5ClQq4zB60tgFWziMCeLOrYFmMyEzUR3tNMMJxNNQn5TkBw8jLgmnhRCQJ+gFw==
# # Qjw1koDFhQKupnvc5tRJMUoN4F0ljtR7wshXrLfdqj6yTXPlpHnGx2yATvVFkqJM9BtR+HUgoL40sza5ETMSQnxLg+RK18XZ8VMy3DPhY+u8WP6KESFbSXTNYFJph3ASFzIcdTn0+5EflQ/o+9upLSzbV/O9ceGUOpgJSwkz0b9PI/Kxsc1uvOxrDideEldf3vqH2xEPPogaZNhCtfegkaAqMBliARH5X13rWo8xNcgjTnbd6jQ2psT5M6uLghNkUeonfRSk9rb5/W3iPu8VbN1IDMAMwAP6uJrF0bA+9fuH5MbVEQXJdtgHRRyH9hJJgU/IaHtNtpiS99lMHweA7Q==
#
# # 如果用的是没有填充的算法. 那么算出来的东西就是固定的. 这种情况用python除非你去自己写算法. 否则很难完成..
# # 如果同一个明文经过反复加密. 计算的密文是一样的. 考虑用js来完成逆向工作. 不要使用python来完成.
- 3 解密
# 解密的过程
f = open("rsa_private_key.pem", mode="r", encoding="utf-8")
pri_key = f.read()
f.close()
rsakey = RSA.importKey(pri_key)
rsa = PKCS1_v1_5.new(key=rsakey)
mi = "Cwx01IndwCNkn/aupsWjgSNuGaUgGIYvvIT+cUau8JgNI4ZCQiiJi/cIJQ7tYmcf4TkCeDlgWSM1FlZrB4wPvRi3ivjEZEIa2q0vwM3zm+Hd7gEYh/uRQ9jb8j07uXsXJ5ejvM9Vgm4hSalP8GXbS6f7i9rQea3nTAw9zC70HAoTxUo17YsJRh/bhZcTD8jjflAEpkhsZwpPvQ/LbLai262/5myNaiykIf2RV+VjfxkN8WM5aDcOELA4UQE8Oi9ORh6T1aWVjWH5pLdVmhHsViRtw12tRbVWyyUmOEldggYpDRd3S+mIcRFPcIamiNW7tnkZEg8OkGWKmdVN0xZ9mQ=="
# 解密, 第一个参数是解密内容, 第二个参数是 如果计算过程中出错了. 返回什么东西
ming = rsa.decrypt(base64.b64decode(mi), None)
print(ming.decode("utf-8"))
# 总结:
# 在逆向的时候, 我们怎么办?
# 第一套逻辑
# "010001" =转换成十进制=> 65537
# setMaxDigits,
# RSAKeyPair,
# encryptedString
# 统一使用js来完成逆向.
# 另外一套rsa逻辑
# var o = new JSEncrypt;
# return o.setPublicKey("MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDA5Zq6ZdH/RMSvC8WKhp5gj6Ue4Lqjo0Q2PnyGbSkTlYku0HtVzbh3S9F9oHbxeO55E8tEEQ5wj/+52VMLavcuwkDypG66N6c1z0Fo2HgxV3e0tqt1wyNtmbwg7ruIYmFM+dErIpTiLRDvOy+0vgPcBVDfSUHwUSgUtIkyC47UNQIDAQAB"),
# o.encrypt(e)
# 固定的js的第三方库 JSEncrypt
# 由于JSEncrypt是第三方js库.不能在浏览器以外的地方使用.
# 我们用的是node环境. 无法正常使用
# 选择一个平替库node-jsencrypt
# 也可以选择用python来完成该加密.
# print(0x10001)
# 网易的加密逻辑:
"""
1.明文
2.生成一个随机值() => i
3.对明文进行AES加密 => 固定秘钥 => g => 结果: encText
4.对encText进行AES加密 => 不固定的秘钥 => i => 结果: encText => params
5.对变量i进行rsa加密. => 密文 => encSecKey
服务器:
拿到的参数有: params, encSecKey
encSecKey => rsa解密 => i
对params 进行AES解密(i) => encText
对encText 进行AES解密(g) => 明文
"""