文章目录
- PointPillarScatter模块
- 1. PointPillarScatter初始化
- 2. PointPillarScatter前向传播
OpenPCDet的整个结构图:

PointPillarScatter模块
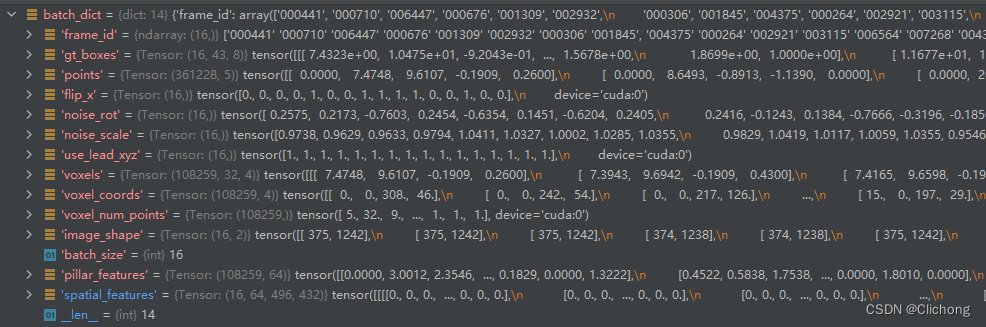
在进行了PillarVFE编码后,此时的batch_dict更新如下所示,追加了pillar_features字段,表示每个voxel的特征,随后进行Map_to_BEV模块处理。

在Map_to_BEV结构中,在对应的__init__文件下,也可以找到全部可供选择的模块,在PointPillars算法中选择使用的PointPillarScatter模块。
# 根据MODEL中的MAP_TO_BEV确定选择的模块
__all__ = {
'HeightCompression': HeightCompression,
'PointPillarScatter': PointPillarScatter,
'Conv2DCollapse': Conv2DCollapse
}
1. PointPillarScatter初始化
PointPillarScatter模块的初始化部分比较简单,只是简单的保存了相关的yaml配置,以及保存了点云场景的平面网络的grid size。由于 PointPillar将整个点云场景切分为平面网格,所以这里的z维度一定是1,也就是没有在z轴上面对网络进行切分。
self.model_cfg = model_cfg
self.num_bev_features = self.model_cfg.NUM_BEV_FEATURES
self.nx, self.ny, self.nz = grid_size # PointPillar将整个点云场景切分为平面网格,所以这里的z维度一定是1
assert self.nz == 1
2. PointPillarScatter前向传播
由batch_dict中可以发现,现在points和coords全靠每一个维度来进行点云帧场景的区分。
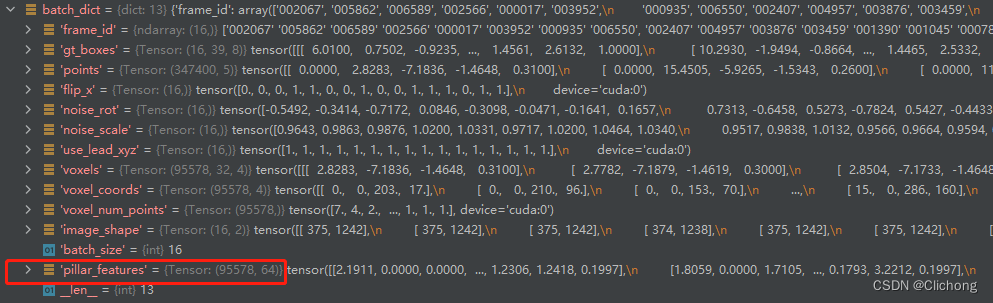
在map2bev模块中需要做的就是将提取出来的voxel特征还原到原空间中,构成一个伪图像特征。
具体的做法是,比如当前提取的voxel特征为Nx64。首选对整个伪空间构造出一个0矩阵,这里两点grid size为[1, 432, 496],所以就会构造出一个[64, 1x432x496]的空矩阵。依次更具相对应的维度获取到个点云帧场景,构造出batch掩码。根据这个掩码就可以获取某个点云帧的pillar特征以及位置coord特征。那么,由于coord存储了voxel的具体网格,可以对其构造出在一维空间中的索引,然后根据索引在空矩阵的相应对位置上填充voxel特征。再进行reshape回到原来的空间中,构造成一个伪图像的特征矩阵。
完整的操作流程如下所示:
def forward(self, batch_dict, **kwargs):
"""
Args:
pillar_features:(31530,64)
voxels:(31530,32,4) --> (x,y,z,intensity)
voxel_coords:(31530,4) --> (batch_index,z,y,x) 在dataset.collate_batch中增加了batch索引
voxel_num_points:(31530,)
Returns:
batch_spatial_features:(4, 64, 496, 432)
"""
pillar_features, coords = batch_dict['pillar_features'], batch_dict['voxel_coords'] # (102483, 64) / (102483, 4)
batch_spatial_features = []
batch_size = coords[:, 0].max().int().item() + 1 # 16
# 依次对每个点云帧场景进行处理
for batch_idx in range(batch_size):
spatial_feature = torch.zeros( # 构建[64, 1x432x496]的0矩阵
self.num_bev_features, # 64
self.nz * self.nx * self.ny, # 1x432x496
dtype=pillar_features.dtype,
device=pillar_features.device)
batch_mask = coords[:, 0] == batch_idx # 构建batch掩码
this_coords = coords[batch_mask, :] # 用来挑选出当前真个batch数据中第batch_idx的点云帧场景
# this_coords: [7857, 4] 4个维度的含义分别为:(batch_index,z,y,x) 由于pointpillars只有一层,所以计算索引的方法如下所示
indices = this_coords[:, 1] + this_coords[:, 2] * self.nx + this_coords[:, 3] # 网格的一维展开索引
indices = indices.type(torch.long)
pillars = pillar_features[batch_mask, :] # 根据mask提取pillar_features [7857, 64]
pillars = pillars.t() # 矩阵转置 [64, 7857]
spatial_feature[:, indices] = pillars # 在索引位置填充pillars
batch_spatial_features.append(spatial_feature) # 将空间特征加入list,每个元素为(64,214272)
batch_spatial_features = torch.stack(batch_spatial_features, 0) # 堆叠拼接 (16, 64, 214272)
# reshape回原空间(伪图像)--> (16, 64, 496, 432), 再保存结果
batch_spatial_features = batch_spatial_features.view(batch_size, self.num_bev_features * self.nz, self.ny, self.nx) # (16, 64, 496, 432)
batch_dict['spatial_features'] = batch_spatial_features
return batch_dict
最后构造出来的spatial_features维度是 (16, 64, 496, 432)。这里的16是batch_size,表示有16个点云帧场景信息。496x432表示伪图像的网格尺寸大小,64表示每个网格上的特征维度。在有voxel上的特征会被pillars_featuer进行填充,其他非voxel索引上的位置特征为0,所以整个特征矩阵还是比较稀疏的。
最后,经过PointPillarScatter模块处理,就可以将一维存储的voxel特征转换成维度的bev视角特征,尽管是比较稀疏的。batch_dict数据更新情况如下: