mysql入门
- 数据库相关概念介绍
- 什么是数据库
- sql语句简介
- sql语句分类:
- ddl语句:
- ddl:数据库 库的创建查找:
- ddl:数据库查询
- 数据库创建
- ddl:数据库删除
- ddl:数据库 表 的操作
- ddl表操作:查询
- ddl 表操作——创建
- mysql数据类型
- ddl表——修改
- dml语句
- dml介绍:
- insert 给表中添加数据
- updata 修改数据
- delete 删除数据
- dql语句:
- dql介绍
- 查询关键字:
- 基本查询分类:
- 设置别名
- 去除重复记录
- dql之条件查询
- dql之聚合函数
- 聚合函数练习
- 分组查询(group by)
- where和having的区别
- 分组查询举例:
- 排序查询:(order by)
- 排序查询练习
- dcl语句:
- dcl管理用户:
- 1.查询用户
- 2.创建用户
- 修改用户密码
- 删除用户
- dcl语句——权限控制
- 1.查询权限
- 2.授予权限
- 3.撤销权限

📌————本章重点————📌 🔗了解数据库的概念; 🔗掌握得到了,dml,读起来,dcl语句的基本使用; 🔗掌握具体实现细节; 🔗了解具体应用场景; ✨————————————✨
数据库相关概念介绍
什么是数据库
数据库是数据存放的仓库,用来存储要管理的事务。现在数据库也被认为是数据管理的新方法和技术,他能更方便组织数据,更新数据。
关系型数据库(robms)
建立在关系模型基础上,有一个或者多张二维表(也叫关系)连接组成,每个表格中有多个行(也称为记录)多个列(也称为字段),每个字段定义了数据库中的一种属性,基于表进行数据的存储的数据库称为关系型数据库。客户端通过数据库管理系统(dbms)来管理数据库,一个管理系统可以创建多个数据库,每一个数据库可以管理多张表。DBA是数据库管理员。
sql语句简介
sql(结构化查询) 是一种用于关系型数据库的标准化语言,用于执行各种数据库操作,例如查询、插入、更新和删除数据等,sql的通用语法,默认以分号结尾,可以多行书写 可以使用空格或缩进增加语句的可读性。 sql不区分大小写,但是关键字推荐使用大写。mysql中的注释:sql中可以使用单行注释——注释内容或者#注释内容。多行内容使用/注释内容/
sql语句分类:
ddl:数据库的 定义语言:数据库的定义,表的定义,字段的定义
dml:数据库操作语言:对于数据库表中数据的增加与删除
dql:数据可查询语言:用来查询数据库中表的记录
dcl:数据控制语言:用来创建数据库用户,控制数据库访问权限
ddl语句:
ddl:数据库 库的创建查找:
ddl:数据库查询
1.查询所有数据库
show databases;

2.查询当前数据库
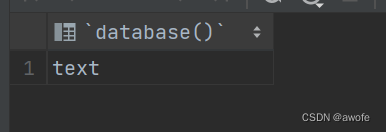
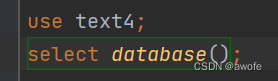
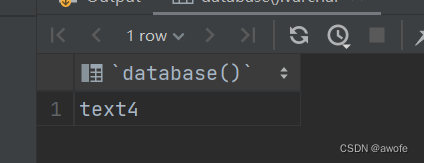
查看当前操作的数据库是哪一个,同时,我们可以使用use 关键字选择我们要使用的数据库。
select database();
数据库创建
create database(if not exists)<如果不存在则创建>数据库名(default chaeset 字符集(utf8))(collate(排序规则));
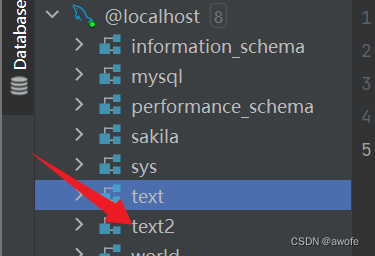
1.create database text2;
2.
如果数据库已经存在还创建相同的数据库,则会报错,这时候我们加上if not exists则会避免报错
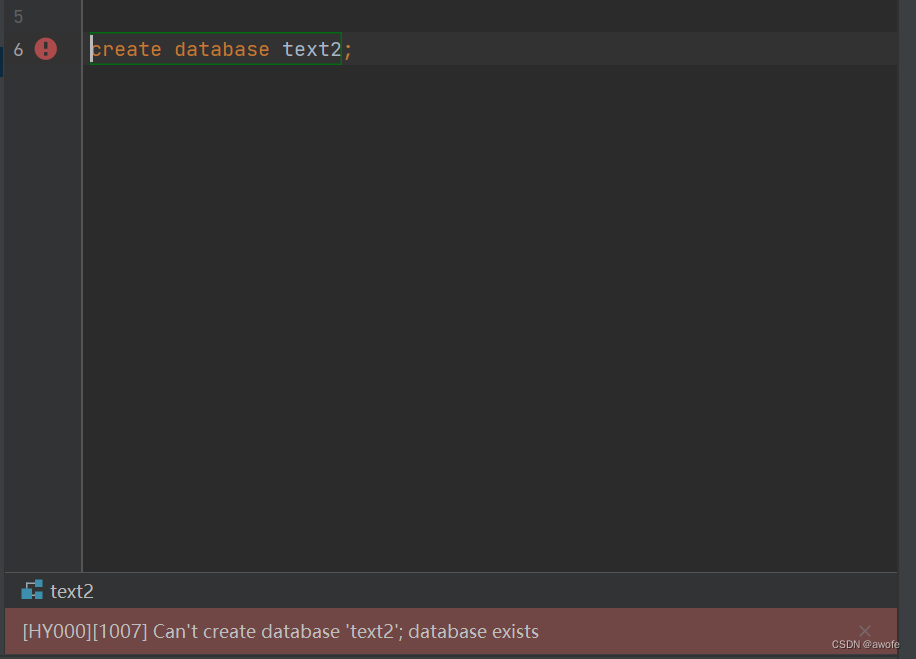
此时我们可以加上if not exists 保证创建的这个数据库之前没有创建过。
create database if not exists text2;
ddl:数据库删除
drop database(if exists 如果存在则删除,不存在则不操作)数据库名;
drop database text2;
数据库的使用
use 数据库名;
ddl:数据库 表 的操作
ddl表操作:查询
1.查询当前数据库中的所有表,前提要进入这个数据库
show tables;
2.查询表结构
desc 表名;

3.查询指定表的建表语句
show create table 表名
ddl 表操作——创建
creat table 表名 ()创建表
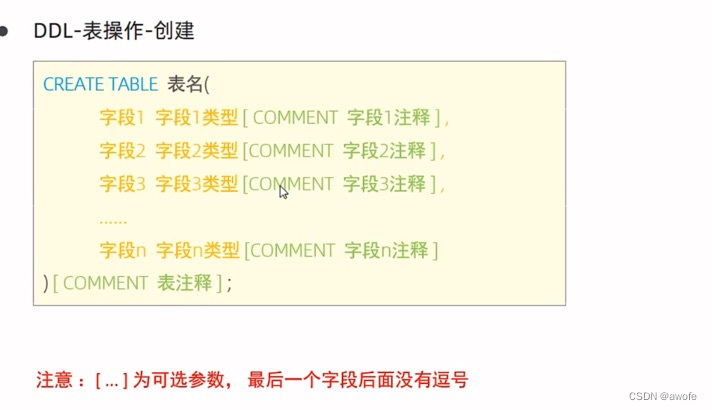
Varchar 字符串类型 varchar(长度)
练习:将下边这个表在text数据库中创建出来:

create table user(
id int comment '编号',
name varchar(50) comment '姓名',
age int comment '年龄',
gender varchar(1) comment '性别'
)comment '用户表';
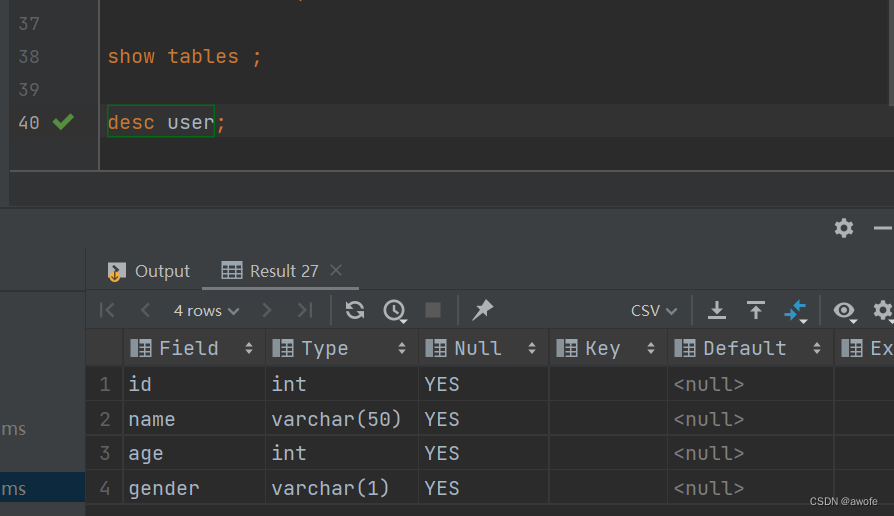
desc 表名 查看表结构
show create table 表名 查看创建表语句
mysql数据类型
 age tinyint unsigned
age tinyint unsigned
score double(4,1) 四代表整体长度 一代表小数长度
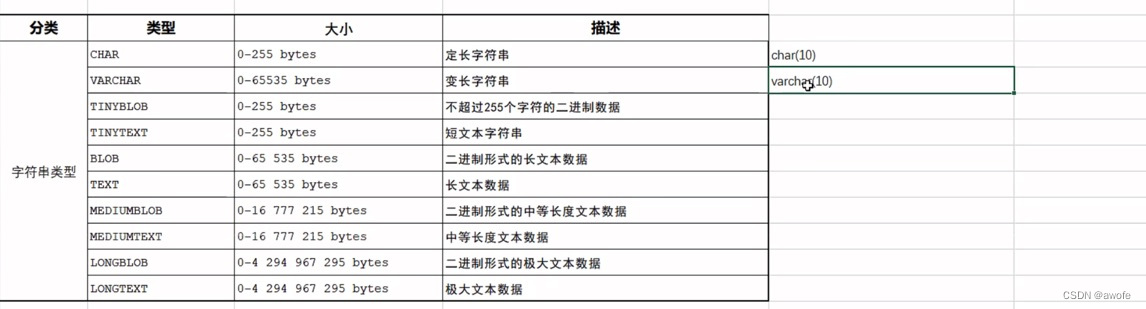
varchar会根据你存储字符串的长度进行变化,varchar的性能会比char的性能低,因为他会计算长度,所以在知道长度后建议使用char类型
这里我们举个例子:
创建一个用户名,长度不超过50位
用户名 username varchar(50) 性别 gender char(1)这里varchar的性能会比char的性能低,因为varchar需要计算你输入的长度。
日期类型:

注意:timestamp最长表达到2038年
练习:
更具需求创建表(设计合理到数据类型)

create table emp(
id int comment '员工编号',
workno varchar(10) comment '员工工号',
name varchar(10) comment '员工姓名',
gender char(1) comment '性别',
age tinyint unsigned comment '年龄',
idcard char(18) comment '身份证号',
entrydata date comment '入职时间'
)comment '员工表';

ddl表——修改
1.添加字段
alter table 表名 add 字段名 类型(长度)comment‘注释”;
alter table emp add text int comment ‘注释’;
desc emp;

2.修改字段
修改指定数据的类型
alter table 表名 modify 字段名 新数据类型(长度)
alter table emp modify text char(10);
desc emp;

修改字段名和字段类型
alter table 表名 change 旧字段名 新字段名 类型(长度)comment’注释‘;
alter table emp change text text2 varchar(10) comment '这是一个测试';
desc emp;

删除字段
alter table 表名 drop 字段名;
修改表名
alter table 表名 rename to 新表名;
ddl表操作——删除
drop table(if exists)表名;
删除指定表,并重新创建该表(创建了一个相同对结构)为啥删除,就是删除数据,重新生成的表只有表头
truncate table 表名;
dml语句
dml介绍:
是对数据库中表的数据记录进行增删改操作
insert 给表中添加数据
1.给指定字段添加数据
insert into 表名 (字段名1,字段名2…)values(值1,值2…);
insert into emp2(id, workno, name, gender, age, idcard, entrydata) values (1,'001','xiaobai','男',18,'612771200307311566','2023-4-11');
select * from emp2;

注意:value和字段名是一一对应的;
2.给全部字段添加数据
insert 表名 values (值1,值2);
3.批量添加数据
为当前表中的指定字段进行赋值:
insert into 表名 (字段名1,字段名2...)values(值1,值2...),(值1,值2....),(值1,值2....);
为当前表中的所有字段进行赋值: insert into 表名 values(值1,值2…),(值1,值2…),(值1,值2):
insert into emp2 values (1,'001','xiaobai','男',18,'612771200307311566','2023-4-13'),(2,'002','xiaowang','男',18,'612771200307311567','2023-4-15');

注意:插入数据时,指定的字段顺序需要与值的顺序是一一对应的。字符串和日期型数据应该包含在引号中。插入的数据大小,应该在字段的规定范围内。
updata 修改数据
updata 表名 set 字段名1 =值1,字段名2 = 值2,…[where 条件];注意:不加where表示修改这个字段的全部数据。
update emp2 set name = 'xiaohei' where id = 1;

delete 删除数据
delete from 表名[where条件]
注意:
delete语句条件可以有也可以没有,如果没有的话就会删除整张表的所有数据;
delete语句不能删除某一个字段的值(可以使用update置为null)
dql语句:
dql介绍
dql是数据查询语言,用来查询表中的记录
查询关键字:
select
单表查询
select 字段列表
form 表名列表
where 条件列表
group by 分组字段列表
having 分组后条件列表
order by 排序字段列表
limit 分页参数
基本查询分类:
基本查询、条件查询、聚合函数、分组查询、排序查询、分页查询
其中select *from 表名中的 * 代表的是所有的意思,意思是查询所有字段
select 字段1,字段2,字段3....from 表名
select * from 表名
设置别名
select 字段1(as 别名1),字段2(as别名2) … from 表名; 作用:使得查询结果更直观
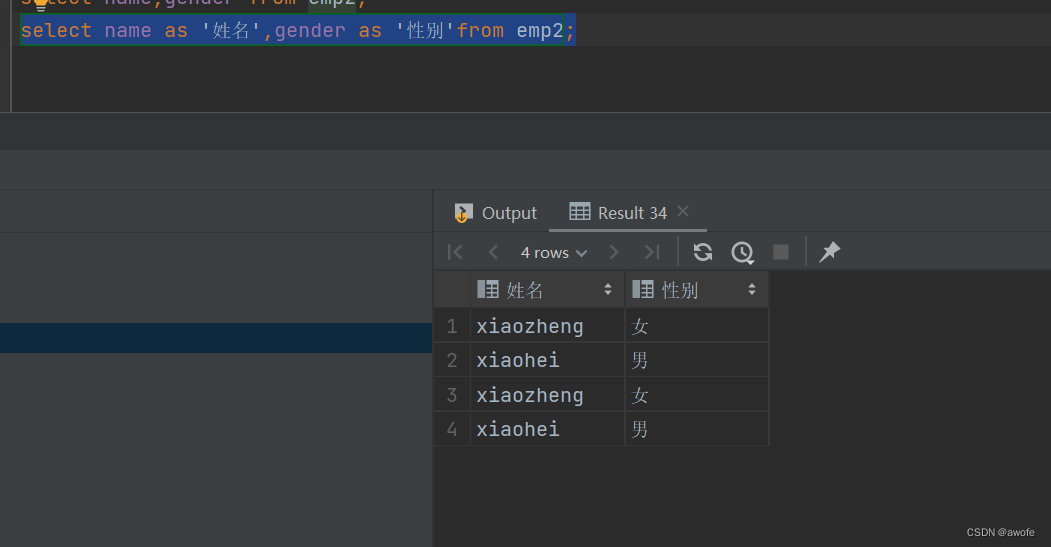
去除重复记录
select distinct 字段列表 from 表名

dql之条件查询
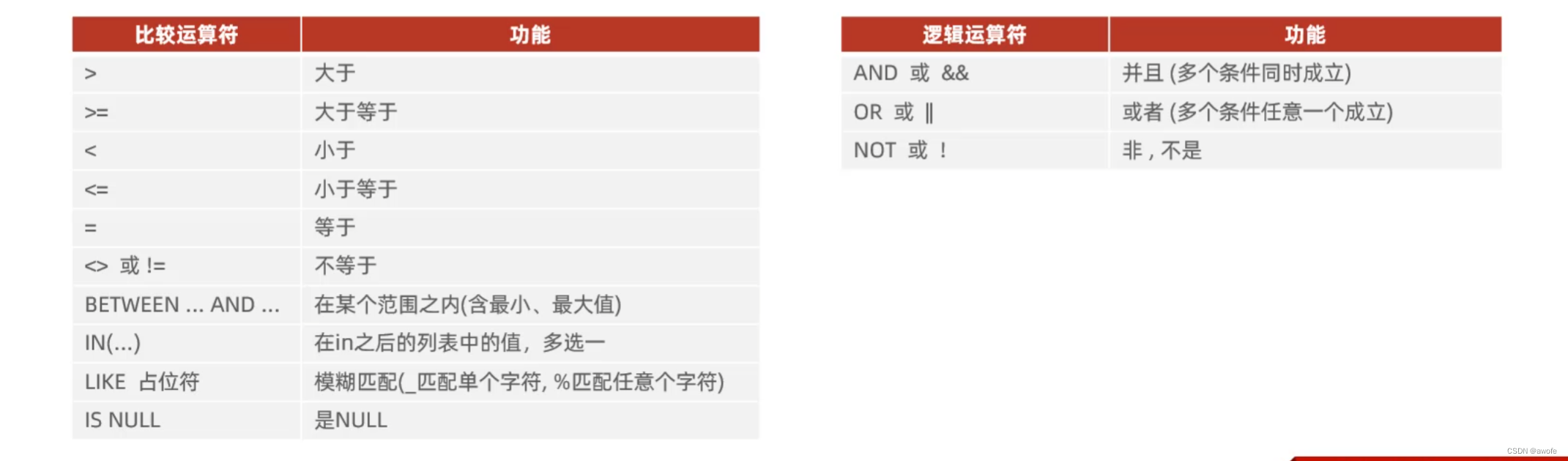
条件查询
1.查询年龄等于88的员工
select * from emp where age = 88;
2.查询年龄小于20的员工信息
select *from emp where age<20;
3.查询年龄小于等于20的员工信息
select *from emp where age<=20;
4.查询没有身份证号的员工信息
select *from emp where idcard is null;
5.查询有身份证号的员工信息
select *from emp where idcard is not null;
6.查询年龄不等于88的员工信息
select * from emp where age != 88;
select * from emp where age <> 88;
7.查询年龄在15岁(包含) 到20岁(包含)之间的员工信息
select * from emp where age>=15 and age<=20;
select * from emp where age>=15 && age<=20;
select * from emp where age between 15 and 20;
注意:between后边要跟小范围,and后边跟大范围;不能跟反,要不会出错
8.查询性别为女且年龄小于25岁的员工信息
select * from emp where gender = '女' and age <25;
9.查询年龄等于18或20或40的员工信息
selecr * from emp where age = 18 or age = 20or age = 40;
select * from emp where age in (18,20,40);
10.查询姓名为两个字的员工信息
select * from name like '__';
一个下划线代表一个字符,like模糊搜索,限定多少位
11.查询身份证最后一位为x的员工信息
select * from emp where idcard like '%x';
上边这个表示只要数据中有任意的x就会搜索到
select * from emp where idcard like '_ 17个下划线_x';
dql之聚合函数
将一列数据作为一个整体进行纵向计算。注意,聚合函数是作用于某一列的
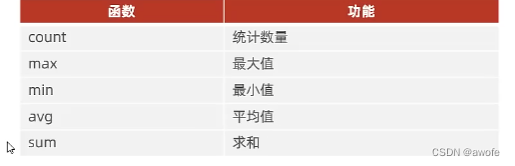
所有的null值是不计算聚合函数的。
聚合函数练习
1.统计该企业的员工数量
select count (*) from emp;查询所有数据(单位:条)
或者还可以具体到每一条
select count(idcard) from emp;
2.统计该企业员工的平均年龄
select avg(age) from emp;
3.统计该企业员工的最大年龄
select max(age) from emp;
4.统计该企业员工的最小年龄
select min (age) from emp;
5.统计西安地区所有员工的年龄之和
select sum(age) from emp where workspace = '西安';
分组查询(group by)
select 字段 from 表名 (where 条件) group by 分组字段名 (having 分组后过滤条件)
注意:
where和having的区别
执行时间不同: where是分组之前进行过滤,不满足where条件,不参与分组;而having 是分组之后对结果进行过滤。
判断条件不同: where不能对聚合函数进行判断,而having可以
分组查询举例:
1.根据性别分组,统计男性员工和女性员工的数量
select gender, count(*) from emp group by gender
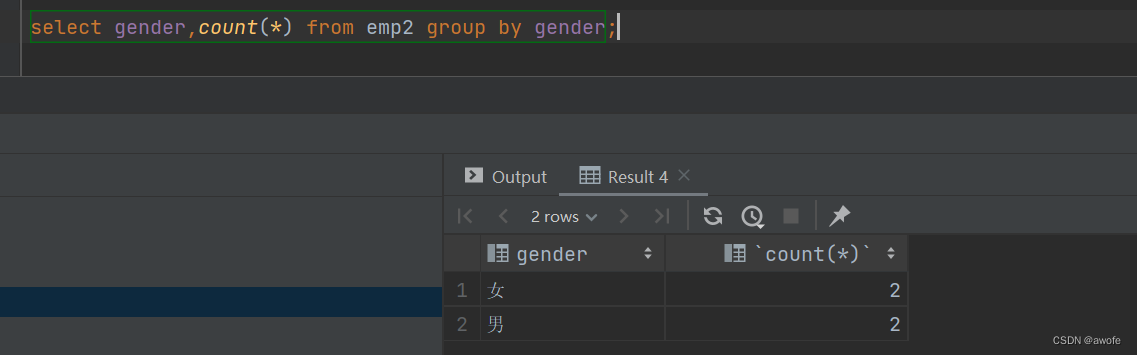
2.根据性别分组,统计男性员工和女性员工的平均年龄
select gender, avg(age) from emp group by gender ;
3.查询年龄小于45的员工,并根据工作地址分组,获取员工数量大于等于3的工作地址
select workaddress,count(* ) address_count from emp where age<45 group by workaddress having count(*)>=3;
注意:
执行顺序:where>聚合函数>having
分组之后,查询字段一般为聚合函数和分组字段,查询其他字段无任何意义。
排序查询:(order by)
语法:
select 字段列表 from 表名 order by 字段1 排序方法1,字段2 排序方法;
排序方式:
asc:升序(默认)
desc:降序
注意:如果是多个字段排序,当第一个字段相同时,才会根据第二个字段进行排序。
排序查询练习
1.根据年龄对公司的员工进行升序排序
select * from emp order by age ace;
2.根据入职时间,对员工进行降序排序
select * from emp order by worktime desc;
3.根据年龄对公司的员工进行升序挂序,年龄相同,再按照入职时间进行降序排序
select * from emp order by age ace,worktime desc;
分页查询:
select 字段列表 from 表名 limit 起始索引,查询记录数;
注意:
起始索引是从0开始的,起始索引 = (查询页码-1)*每页显示记录数;比如:我现在要查询的是第二页的10条数据,每页显示10条记录,则我的起始索引就是 (2-1)*10;
分页查询是数据库的方言,每个数据库有不同的实现方式,mysql中使用的是limit
如果查询的是第一页的数据,起始索引可以省略,直接写为limit 查询记录数;
举例:
1.查询第一页员工的数据,每页展示10条数据
select * from emp limit 0,10;
2.查询第二页员工数据,每页展示10条数据
select * from emp limit 10.10;
dcl语句:
dcl:数据控制语言,用来管理数据库用户、控制数据库的访问权限
dcl管理用户:
1.查询用户
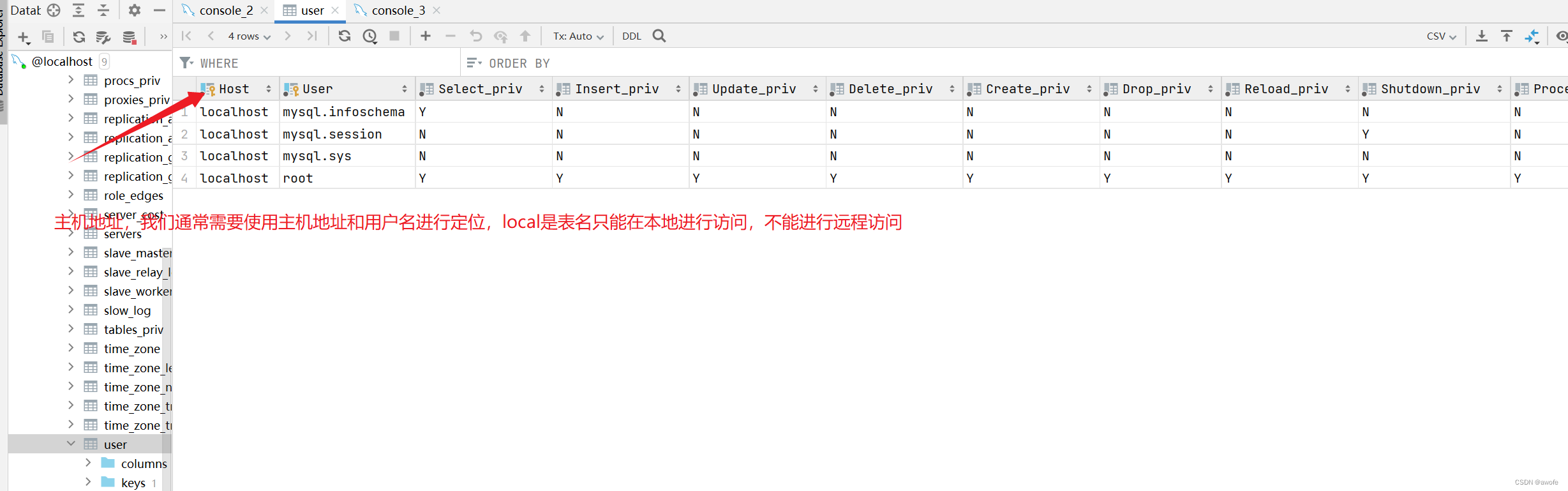
用户信息都是存放在mysql中的user表中,所以我们可以查询数据库中的user表来查看用户信息。
use mysql;
select * from user;
2.创建用户
creat user '用户名'@'主机名' identfied by '密码';
创建一个用户itcast
create user 'itcast' @ 'localhost' identified by '123123';
这时候我们刷新一下用户表会发现我们的itcast这个用户已经创建完成了,我们发现他的权限基本都是N;

这时候我们使用cmd命令登入查看该用户下的数据库,我们会发现,当前用户下只有俩个数据库,和root用户下比少了很多,即它没有访问其他用户的权限

我们目前创建的这个这个用户只能在本机上进行访问,如果我们想在任意主机上进行访问该怎么办呢?
我们只需要将== localhost 换成通配符 % ==
create user 'xiaowang' @ '%' identified by '123123';

修改用户密码
alter user '用户名'@'主机名' idetified with mysql_native_password by '新密码';
其中:mysql_native_password是一种mysql的加密方式,mysql_native_password 是 MySQL 中用于身份验证的默认密码策略。它使用 MySQL 服务器上的密码进行加密来验证用户的身份。
alter user 'xiaowang'@'%' identified with mysql_native_password by '123456';
这时候我们通过exit推出数据库后重新登入xiaowang用户检查密码是否修改完成
删除用户
drop user 'itcast'@'localhost';
以上介绍的sql开发人员使用的比较少,主要是dba(数据库管理员)使用。
dcl语句——权限控制
我们在刚刚创建了用户之后发现我们的用户不能访问其他数据库,这就是我们没有对其进行权限配置,接下来就让我们学习以下权限控制。
我们这里介绍常用的一些权限:

主要介绍以下三种使用:
1.查询权限
show crant for ‘用户名’@‘主机名’;
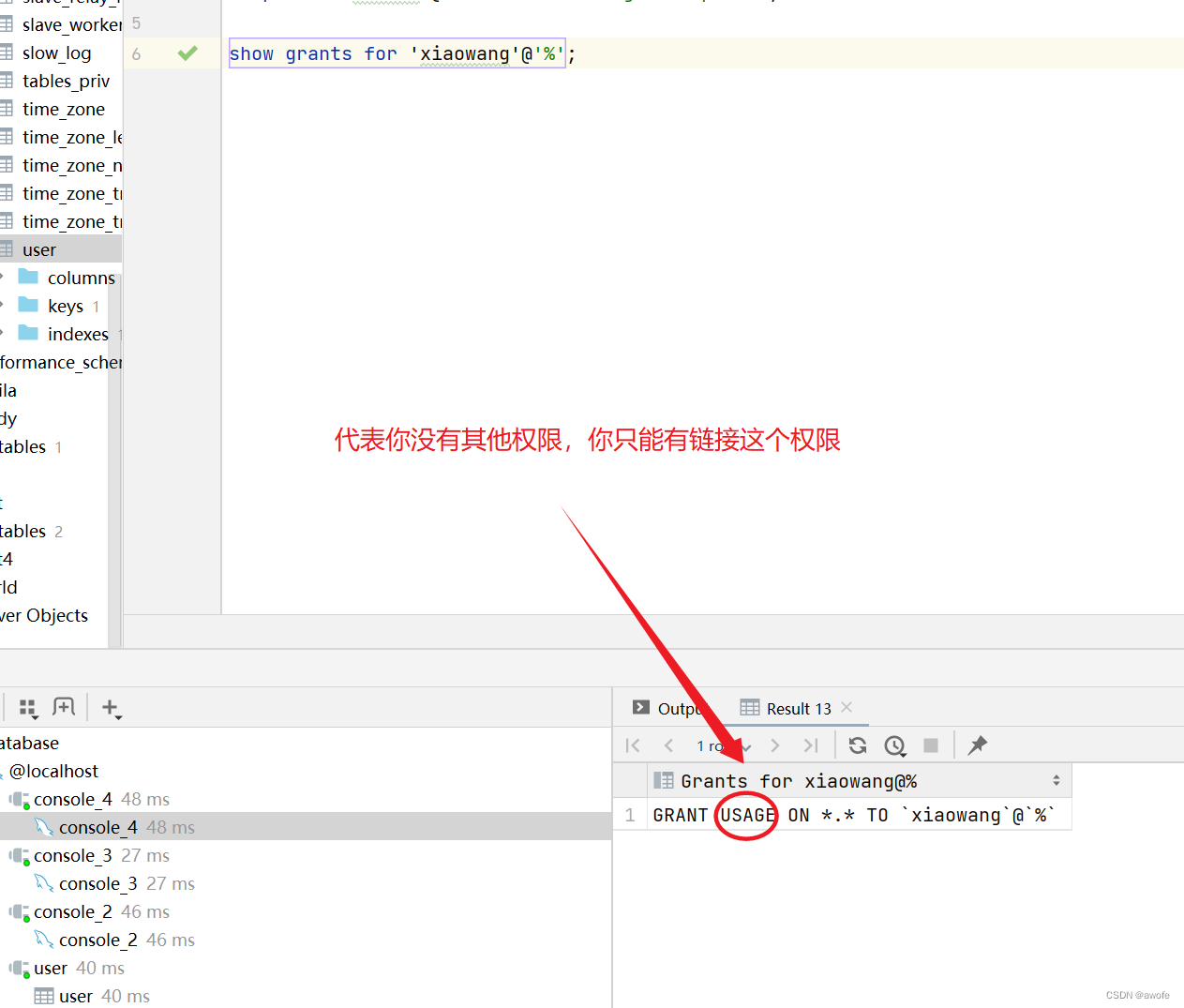
2.授予权限
grant 权限列表 on 数据库名.表名 to ‘用户名’@‘主机名’;
grant all on study.* to ‘xiaowang’@‘%’;
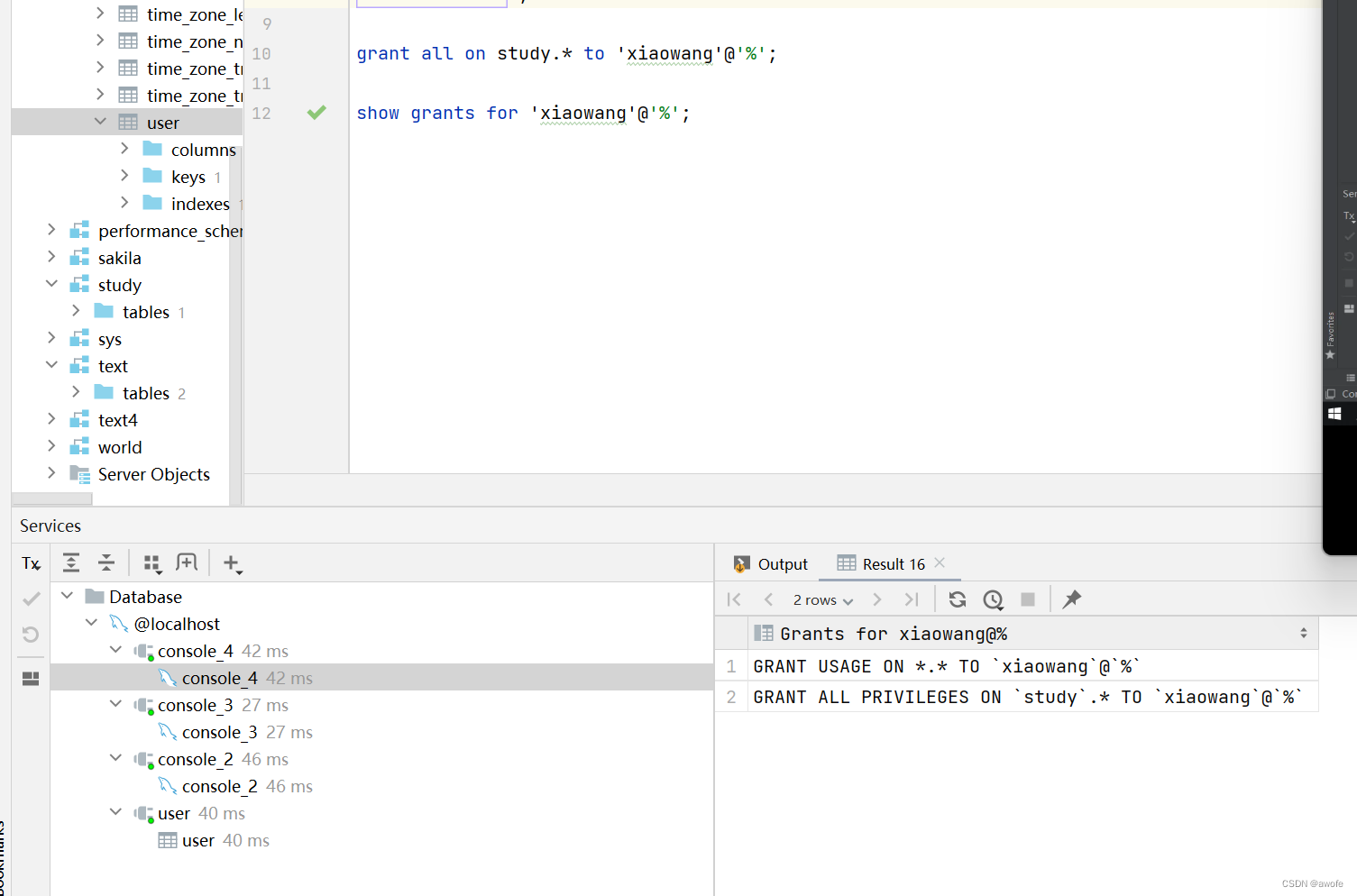
3.撤销权限
revoke 权限列表 on 数据库名.表名 from ‘用户名’@‘主机名’;