前言
图存储的全称叫图数据库存储引擎或图数据库存储层(组件)。在功能层面,它负责图数据库或图数仓的数据的持久化存储。因为存储距离用户层的应用较图计算更为遥远,过往很少有论著会专门讲述图存储环节,但笔者要说的是,图存储是图数据库不可或缺的环节。下面,我将分两篇文章来重点讲讲。
首先要问大家一个问题——目前市场上主流的数据库存储引擎都有哪些呢?
大而化之大概分为两类,一类是基于B-Tree的存储引擎,一类是基于LSM-Tree的存储引擎。此外,当然还有很多其他类型的存储方式,笔者简单地罗列一下:
- 基于文件的,有序或无序的
- 基于堆的,(也是一种文件)
- 基于哈希桶的
- 基于索引顺序存储(ISAM)文件系统的
- 其他的存储模式
那么,如果是按照数据存储的排列方式,还可以分为:
- 行存储
- 列存储
- KV存储
- 关联存储
我们知道,B-Tree是一种自平衡的树状、有序数据结构。它最早源自上世纪70年代的波音实验室研究院发明出来的。但B到底到底代表了什么,从来没有定论。那么,B-tree在数据库存储引擎端通常会实现什么功能呢?
- 保证键排序已支持顺序排序
- 使用层级化索引来最小化磁盘读操作次数
- 通过块操作来对插入和删除进行加速
- 通过递归算法来保持索引平衡性
B-tree可以让数据查找、顺序访问、插入及删除等操作的时间复杂度对数时间内。实际上,工业界的B-tree索引通常都采用辅助索引的方式来进行加速。我们熟知的很多关系型数据库例如Oracle、SQL Server、IBM DB2、MySQL InnoDB、PostgreSQL到B-tree的身影。
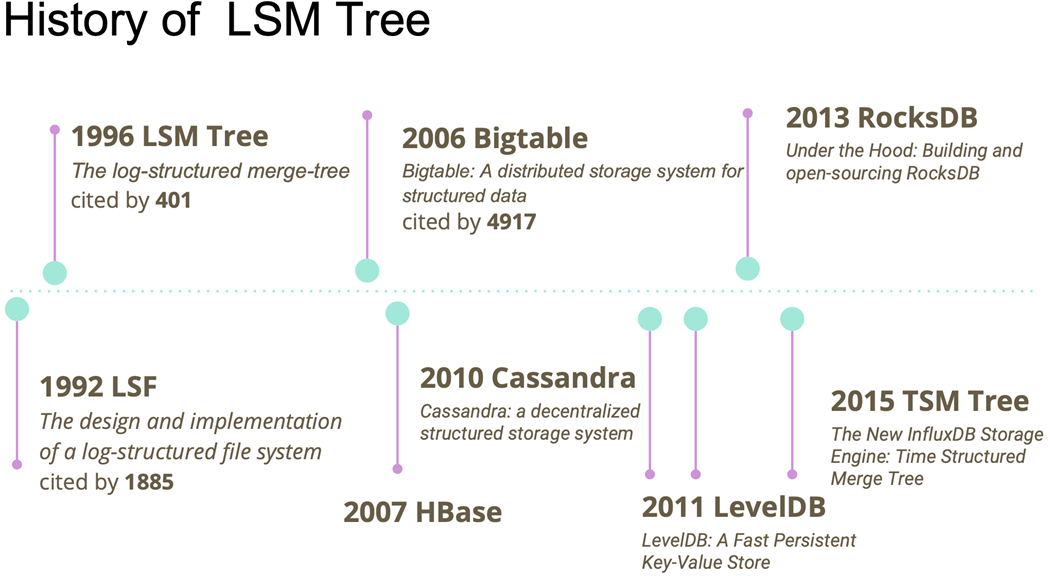
LSM-tree的全称是Log-Structured Merge-Tree(日志结构化合并树),它诞生的背景是大数据情况下快速增长的数据,数据量日益增大,写操作较之前的关系型数据库更为频繁,非关系型数据库快速崛起,这些新兴的数据库和大数据框架更多的用于分析和决策支撑。它设计之初的目标就是提供对磁盘文件的高写入性能索引。
我们知道,与LSMT相关的论文最早是上世纪的90年代初,在加州的DEC公司由帕特里克·奥尼尔等人在进行数据库研发时发明的,并最终于1996年发布。今天几乎所有的NoSQL数据库实现中都可以看到它的身影:
- Bigtable
- HBase
- LevelDB
- SQLite
- RocksDB
- Cassandra
- InfluxDB
- ScyllaDB
LSMT的设计理念用最简单的语言描述是构造了两套大小不同的树状数据结构。它展现给我们最核心的理念是:分层存储加速!充分利用内存加速,当内存空间不够的时候再利用硬盘加速,特别是随着新型存储硬件,例如SSD、NVMe-SSD、持久化内存PMEM的不断发展,LSMT的理念至今为止可谓长盛不衰。
LSMT并非没有缺点,实际上它相比与B-Tree而言有两个问题:
- 读性能瓶颈(CPU资源消耗更高)
- (更高的)读以及空间放大效果(占用更多内存、硬盘空间)
当然,在实际应用中,LSMT与B-Tree通常是同时被使用的。并且,LSMT的读性能问题通过布隆过滤器(Bloom Filter)得到了大幅提升。对Bloom Filter有兴趣深入研究的读者可以尝试阅读这篇文章What are Bloom filters? https://blog.medium.com/what-are-bloom-filters-1ec2a50c68ff。
我们花了不小的篇幅介绍了“传统”数据库的存储引擎。现在,我们来剖析一下图数据库的存储引擎的原理。
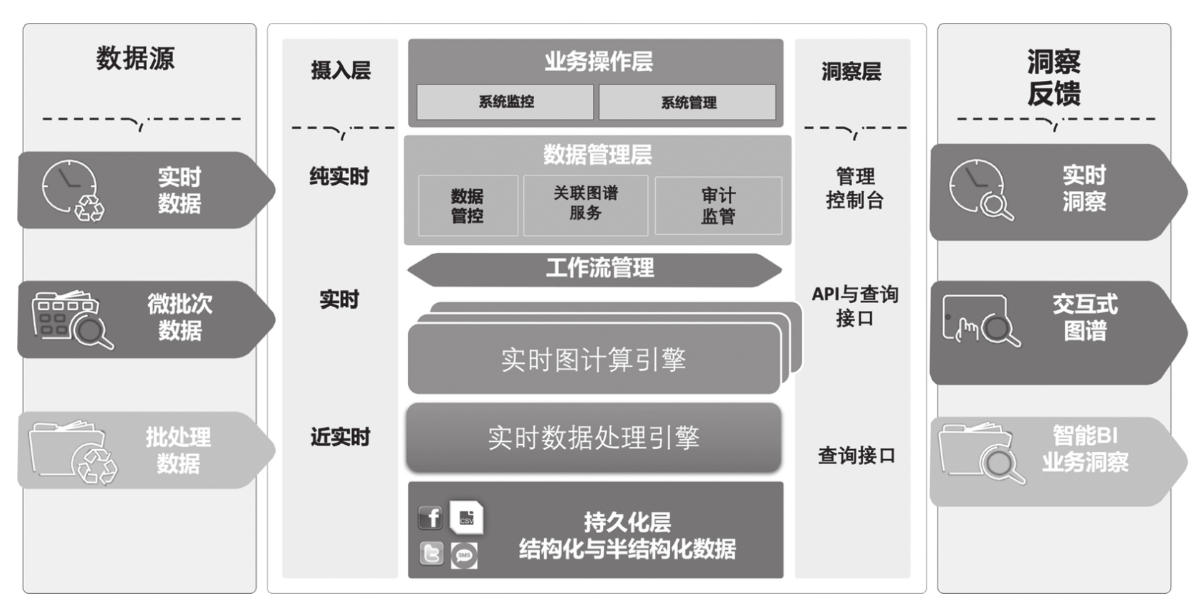
图存储与图计算组件在图数据库框架内的层级逻辑关系
上图中就是图存储引擎、计算引擎、数据管理、操作管理等组件有机的结合成为一个相对完整的产品时的样子。
之前的文章中,笔者就介绍过图数据库的计算引擎数据结构,这些数据在逻辑上都是源自持久化存储的数据,或者需要与存储引擎保持某种一致性,以实现数据库的事务正确性(即ACID,原子性、一致性、隔离性与持久性对应的四个英文单词的首字母)。
图的存储无非是最主要的两种基础数据结构——顶点和边,其他所有数据结构都是在这两者的基础上衍生而来的,例如各类索引、中间、临时的数据结构,用来实现查询与计算加速等,以及那些需要异构返回的数据结构,如路径、子图等。
- 顶点
- 边
支持点、边结合的数据类型如果是完全静态的,也就是说点或边的数量不会变化,不会增加、减少或更新,也不会发生它们各自属性的变化,那么映射到文件系统上的数据结构就可以作为图存储的核心数据结构。
如果真是这样的话,我们可以复用传统数据库的存储引擎,例如MySQL的InnoDB或MyISAM(ISAM的变种)引擎,更有甚者,只使用磁盘文件就可以支持静态的图数据库。然而,效率在大多数情况下是不可或缺的。上面“静态”数据的假设在商业场景中是极少成立的,因为无论是交易系统还是业务管理系统,数据都是动态的、流动的。任何贴近真实业务场景的系统都需要支持对数据(存储引擎)的更新操作。因此,图存储引擎的架构设计中有一对重要的概念:非原生图与原生图。所谓非原生图是指它的存储与计算是以传统的表结构(行或列数据库)的方式进行的;而原生图则采用更能直接反映关联关系的方式构造而成,也因此会有更高效的存储和计算效率。
- 非原生图
- 原生图
如果用关系型数据库MySQL、宽列数据库(wide-column)HBase或二维的KV数据库Cassandra来作为底层存储引擎,也可以把点、边数据以表(或列表)的方式存储起来,它们在进行图查询与计算时的逻辑大体如下图所示。

非原生图(关系型、SQL类数据库)存储查询模式示意图
举个例子,查询某位员工隶属于什么部门,返回该员工姓名、员工编号、部门名称、部门编号等信息。用关系型数据库来表达,这个简单的查询要涉及3张表之间的关联关系:员工表、部门表和员工部门对照表。
整个查询过程分为如下几步:
- ①在员工表中,定位007号员工;
- ②在对照表中,定位007号员工所对应的全部部门ID;
- ③在部门表中,定位步骤②中的全部ID所对应的部门名称;
- ④组装以上①~③步骤中的全部信息,返回。
我在上已经介绍过数据库存储加速的概念,上面每个步骤的时间复杂度如下表所示:
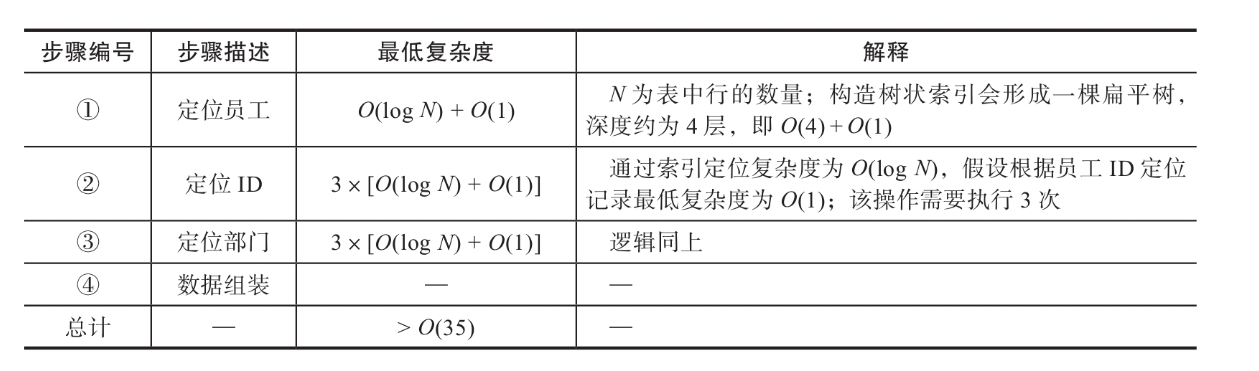
上面的查询(时间)复杂度并没有考虑任何硬盘操作的物理延迟或文件系统上的定位寻址时间,实际的时间复杂度在这样简单的一个查询操作中,如果数据量在千万以上,可能会以分钟计。如果是更复杂的查询,涉及多表之间复杂的关联,则可能会出现多次扫表操作,试想在硬盘上这个操作的复杂度和时延会是何等量级。如果用原生图的“近邻无索引”模式来完成以上查询,整个流程如下图所示。
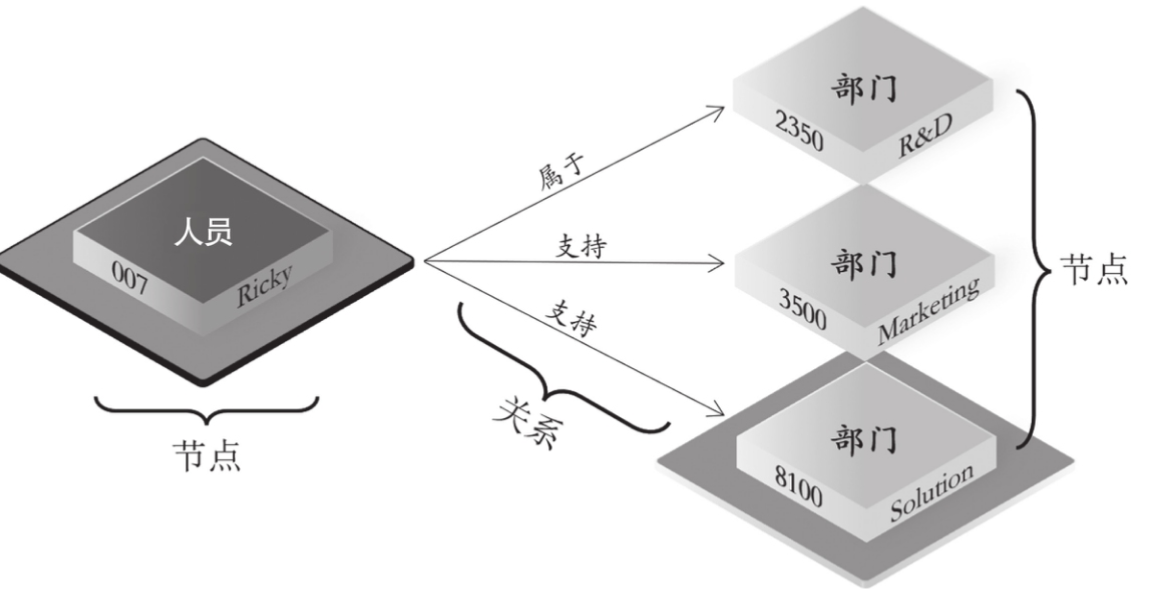
在原生图上的查询步骤细分如下:
- ①在图存储数据结构中定位员工;
- ②从该员工顶点出发,通过员工-部门关系,找到它所隶属的部门;
- ③返回员工、员工编号、部门、部门编号。
以上第一步的时间复杂度与非原生图(SQL)基本相当,但是第二步会有明显的缩短。因为近邻无索引的数据结构,员工顶点通过3条边直接链接到3个部门。如果SQL查询的方式最优解是O(35),原生图则可以做到O(8),分解如下表所示。

原生图查询复杂度
以上的例子显示,原生图与非原生图在事件复杂度上存在较大的性能差异。以较简单的1度(1-Hop)查询为例,有330%的性能提升。如果是更为复杂、深度更大的查询,则会产生乘积的效果,也就是说随着深度增加而性能差异指数级飙升,如下表所示。
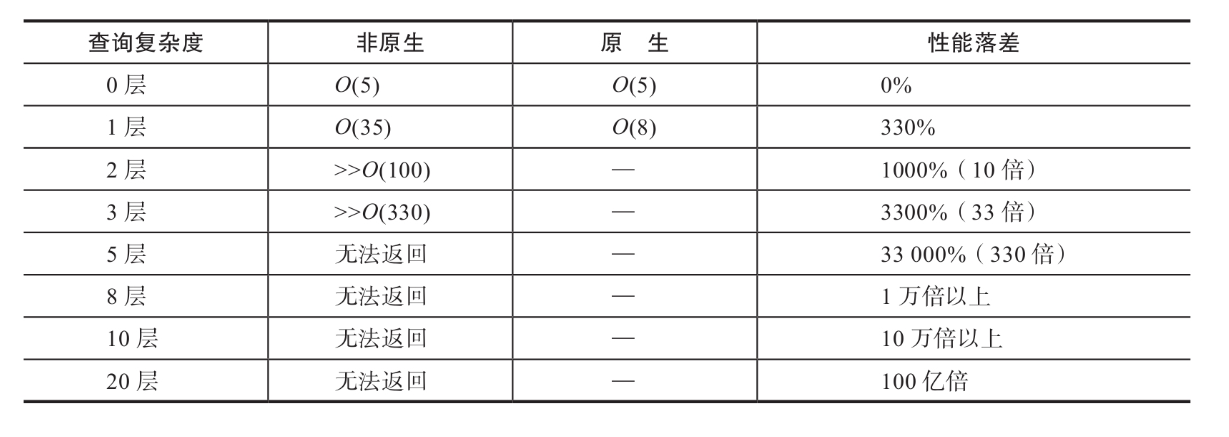
非原生图VS.原生图性能落差示意图
(文 / 孙宇熙 Ricky 业界知名高性能计算与存储系统专家、大数据专家、图数据库专家及学者。 )
·End·
预告:这期我们就图查询的基本概念讲了讲,下期我们再围绕图存储的数据结构与构图聊聊。当然,有兴趣的读者,也可以看我发布的新书——《图数据库原理、架构与应用》,里面有更详尽的内容!






![[附源码]SSM计算机毕业设计音乐网站JAVA](https://img-blog.csdnimg.cn/3efbb3f30271465ea7e63e01e74da075.png)