文章目录
- sort命令
- uniq命令
- tr命令
- cut命令
- split命令
- paste命令
- eval命令
- 总结
sort命令
-
以行为单位对文件内容进行排序,也可以根据不同的数据类型来排序.
-
比较原则:从首字符向后,依次按ASCII码值进行比较,最后将他们按升序输出.

语法格式
sort [选项] 参数
cat file | sort 选项
常用选项
| 选项 | 命令含义 |
|---|---|
| -n | 按照数字进行排序,默认按照升序排序 |
| -r | 反向排序,按照降序排序 |
| -u | 等同于uniq,表示相同的数据仅显示一行 |
| -t | 指定字段分隔符,默认使用[Tab]键分隔 |
| -k | 指定排序字段 |
| -o | <输出文件>:将排序后的结果转存至指定文件 |
| -f | 忽略大小写,会将小写字母都转换为写字母来进行比较 |
| -b | 忽略每行前面的空格 |





uniq命令
- 用于报告或者忽略文件中连续的重复行,常与sort 命令结合使用.
语法格式
uniq [选项] 参数
cat file | uniq 选项
常用选项
| 选项 | 命令含义 |
|---|---|
| -c | 进行计数,并删除文件中重复出现的行 |
| -d | 仅显示连续的重复行 |
| -u | 仅显示出现一次的行 |


例题演练一:
查找已知文件中出现超过三次的IP地址;

[root@clr /opt/practice]# vim 1.sh
#!/bin/bash
#查找已知文件test4中出现超过三次的IP地址
cat test4 | sort -n -t '.' -k4 | uniq -c > ./count.txt
#将test4文件中的IP地址以.分割,按照地字段进行排序后,统计重复行数,并删除重复行,将结果重定向写入到当
前目录下的count.txt文件中
IFSB=$IFS
IFS=$'\n' #修改for循环的IFS环境只以\n换行符进行分割
for i in $(cat ./count.txt)
do
num=$(echo $i | awk '{print $1}') #获取重复行出现的次数
#echo $num #输出重复次数
if [ $num -gt 3 ];then #判断重复次数大于3次,输出第二字段的ip地址
echo $i | awk '{print $2}'
fi
done
IFS=$IFSB
[root@clr /opt/practice]# vim test4
192.168.80.1
192.168.80.45
192.168.80.1
192.168.80.1
192.168.80.79
192.168.80.11
192.168.80.100
192.168.80.100
192.168.80.561
192.168.80.11
192.168.80.11
192.168.80.100
192.168.80.561
192.168.80.87
192.168.80.11
192.168.80.3
192.168.80.100
192.168.80.51111
[root@clr /opt/practice]# vim count.txt
3 192.168.80.1
1 192.168.80.3
4 192.168.80.11
1 192.168.80.45
1 192.168.80.79
1 192.168.80.87
4 192.168.80.100
2 192.168.80.561
1 192.168.80.51111
例题演练二:
查找一分钟内五次登录系统输入密码错误的用户,并将该IP地址加入到黑名单/etc/hosts.deny中;


[root@clr /opt/practice]# vim 2.sh
#!/bin/bash
#查找一分钟内五次登录系统输入密码错误的用户,并将该IP地址加入到黑名单/etc/hosts.deny中
count=$(cat /var/log/secure|grep 'Failed password'|grep 'root'|awk '{print $11}'|sort -n -t '.' -k4|uniq -c)
#将test4文件中的IP地址以.分割,按照地字段进行排序后,统计重复行数,并删除重复行,将结果赋值给变量count
IFSB=$IFS
IFS=$'\n' #修改for循环的IFS环境只以\n换行符进行分割
for i in $count
do
num=$(echo $i | awk '{print $1}') #获取重复行出现的次数
#echo $num #输出重复次数
if [ $num -gt 5 ];then #判断重复次数大于3次,输出第二字段的ip地址
echo $i | awk '{print $2}'
fi
done
IFS=$IFSB

tr命令
- 常用来对来自标准输入的字符进行替换、压缩和删除.
语法格式
tr [选项] [参数]
常用选项
| 选项 | 命令含义 |
|---|---|
| -c | 保留字符集1的字符,其他的字符(包括换行符\n)用字符集2替换 |
| -d | 删除所有属于字符集1的字符 |
| -s | 将重复出现的字符串压缩为一个字符:用字符集2 替换 字符集1 |
| -t | **字符集2 替换 字符集1,不加选项同结果 |
参数
字符集1:指定要转换或删除的原字符集。当执行转换操作时,必须使用参数"字符集2"指定转换的目标字符集。但执行删除操作时,不需要参数"字符集2;
字符集2:指定要转换成的目标字符集。


删除空行的两种方法;
[root@clr /opt/practice]# echo -e "ab\n\n\n\n\n\ncd"
ab
cd
[root@clr /opt/practice]# echo -e "ab\n\n\n\n\n\ncd" | tr -s "\n" #将重复出现的换行符压缩为一个,起到删除空行的效果
ab
cd
[root@clr /opt/practice]# echo -e "ab\n\n\n\n\n\ncd" | grep -v "^$" #grep -v反向取空格,将空格以外的左右行输出
ab
cd

实战演练
利用sort和tr命令,实现元素序列的排序;

[root@clr /opt/practice]# vim 4.sh
#!/bin/bash
#利用sort和tr命令,实现元素序列的排序
arr=(14 25 78 36 1 3 5 45 39 68 14)
echo "排序前数据的值为:${arr[@]}"
newarr=($(echo ${arr[@]}| tr ' ' '\n' | sort -n | tr '\n' ' '))
echo "排序后数据的值为:${newarr[@]}"
windows的换行:由回车符/r和换行符/n组成;而linux的换行:由换行符/n组成.


安装dos2unix工具,即可解决windows与linux文件不能兼容使用的问题;
[root@clr /opt/practice]# yum install -y dos2unix
已加载插件:fastestmirror, langpacks
Loading mirror speeds from cached hostfile
* base: mirrors.nju.edu.cn
* extras: mirrors.huaweicloud.com
* updates: mirrors.huaweicloud.com
正在解决依赖关系
--> 正在检查事务
---> 软件包 dos2unix.x86_64.0.6.0.3-7.el7 将被 安装
--> 解决依赖关系完成

cut命令
显示行中的指定部分,删除文件中指定字段.
语法格式
cut 参数
cat file | cut选项
常用选项
| 选项 | 命令含义 |
|---|---|
| -f | 通过指定哪一个字段进行提取。cut命令使用"TAB"作为默认的字段分隔符 |
| -d | "TAB”是默认的分隔符,使用此选项可以更改为其他的分隔符 |
| –complement | 此选项用于排除所指定的字段 |
| –output-delimiter | 更改输出内容的分隔符 |
注意:
sort -t 指定分隔符 -k 指定字段号
cut -d 指定分隔符 -f 指定字段号




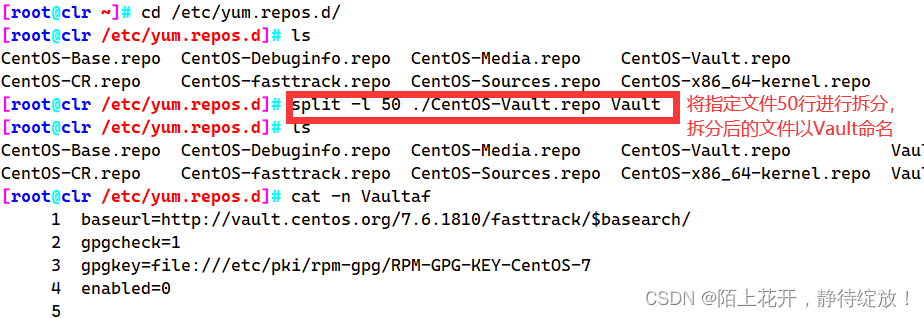
split命令
split命令可以将一个大文件分割成很多个小文件,有时需要将文件分割成更小的片段,比如为提高可读性,生成日志等。
语法格式
split 选项 参数 原始文件 拆分后文件名前缀
常用选项
-l:以行数拆分
-b:以大小拆分
| 选项 | 命令含义 |
|---|---|
| -l | 按照行数分割文件,默认1000行一个文件 |
| -b | 按照文件大小分割文件,单位:字节 |
paste命令
paste可以将不同文件的数据放在一行。缺省情况下,paste使用空格或者tab键分隔新行中的不同文件。
命令格式
paste <-d> <-s> file1 file2
常用选项
| 选项 | 命令含义 |
|---|---|
| -d | 制定不同于空格或tab键的分隔符。比如使用@分隔符,就可以-d @ |
| -s | 将每个文件合并成行,而不是按行合并。(即每个文件中的内容占一行。而不是从每个文件取行,合并成新行) |


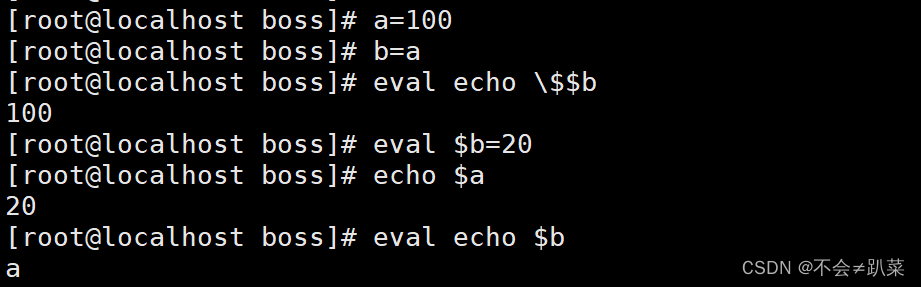
eval命令
命令字前加上eval时,shell会在执行命令之前扫描它两次。eval命令将首先会先扫描命令行进行所有的置换,然后再执行该命令。该命令适用于那些一次扫描无法实现其功能的变量。该命令对变量进行两次扫描。
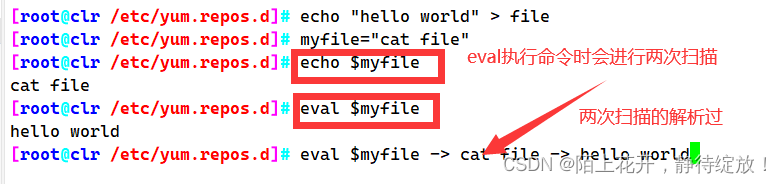

[root@clr /etc/yum.repos.d]# bash 4.sh 1 2 3 7 6 6
6
[root@clr /etc/yum.repos.d]# cat 4.sh
#!/bin/bash
eval echo \$$#
[root@clr /etc/yum.repos.d]# eval echo |$$# -> echo $6 -> 6

总结
| 命令关键字 | 命令含义 | 常用选项 |
|---|---|---|
| sort | 排序 | -n(数字排序) -r(反向排序) -t(指定分隔符) -k(指定排序字段) |
| tr | 替换、删除、压缩 | -t(字符集2替换字符集1) -d(删除) -s(压缩重复字符) -c(保留字符集1,其余所有用字符集2替换) |
| cut | 截取字段 | -d(更改分隔符) -f(指定提取字段) --output-delimiter(更改输出分割符) --complement(排除指定字段) |
| uniq | 去重、统计重复次数 | -c(删除重复行,并进行计数) -d(显示连续的重复行) -u(仅显示出现一次的行) |
| split | 拆分文件 | -l(以行数拆分) -b(以大小拆分) |
| paste | 按列合并文件 | -d(指定分割符) -s(转置,将列转换为行) |
| eval | 扫描两次执行命令,放在命令前使用 | —— |