一、几个概念
1. 消费者组
消费者组:一个消费者组包含多个消费者。同一个消费组的消费者,分别消费不同的partition,便于加快消费。
kafka约定在一个消费者组中,对于同一个topic,每个consumer会分配不同partition,即topic下的一个patition只能被同一个消费者组的一个消费者消费,所以当消费组中的消费者个数大于partition个数时,会存在消费者闲置的情况,因为分不到partition.
2. 点对点(P2P,point to point)和发布订阅模型(Publish/Sub)
消息中间件模型有两种经典模型:点对点(P2P,point to point)和发布订阅模型(Publish/Sub)
点对点模式是基于队列,消息生产者将消息发送到队列,消息消费者从队列拉取消息
发布订阅模式定义了如何向一个内容节点发布和订阅消息,这个内容节点称为主题(Topic),主题可以认为是消息传递的中介,消息发布者将消息发布到某个主题,而消息订阅者从主题订阅消息
kafka通过消费者和消费者组的契合可以实现点对点(P2P,point to point)和发布订阅模型(Publish/Sub):
如消费者都属于同一个消费组,那么partition的消息发给这些消费者时,一条消息只发给一个消费者,不会多发,相当于点对点模式
消费者隶属于不同消费组,那么同一个partition可能发给不同消费者组的多个消费者手中,相当于发布订阅模式;
3. 消费者再均衡:
同一个消费组内的消费者消费不同分区,当消费者组内再增加消费者时,原来的消费者对应的partition会被回收掉,然后重新分配给最新的所有消费者,这就是再均衡。
consumer.subscribe(Collections.singletonList("topic-module"), new ConsumerRebalanceListener() {
@Override
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.err.println("回收partitions:"+partitions);
}
@Override
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.err.println("再分配partitions:"+partitions);
}
});二、消费者多线程模型
kafka的consumer是非线程安全的,如果多个线程操作一个consumer实例,会报异常;因为KafkaConsumer中定义了一个acquire方法用来检测是否只有一个线程在操作,当检测到有其他线程时,会抛出ConcurrentModifactionException;
KafkaConsumer在执行所有动作时都会先执行acquire方法检测是否线程安全。
不过要实现消费者的多线程模型,也是有办法的
1. 多线程模型1

一个partition对应一个consumer,一个consumer也只运行在一个线程中。
首先新建一个 consumer线程类KafkaConsumerMultiThread1.java
public class KafkaConsumerMultiThread1 implements Runnable {
private KafkaConsumer<String, String> consumer;
private volatile boolean isRunning = true;
private String threadName;
private static AtomicInteger num = new AtomicInteger(0);
public KafkaConsumerMultiThread1(Properties properties, String topic) {
this.consumer = new KafkaConsumer<String, String>(properties);
this.consumer.subscribe(Collections.singletonList(topic));
this.threadName = "consumer-thread-" + num.getAndIncrement();
System.err.println(this.threadName + " started ");
}
@Override
public void run() {
try{
while (isRunning){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for(TopicPartition topicPartition : records.partitions()){
List<ConsumerRecord<String, String>> consumerRecords = records.records(topicPartition);
int size = consumerRecords.size();
for(int i=0; i<size; i++){
ConsumerRecord<String, String> record = consumerRecords.get(i);
String value = record.value();
long messageOffset = record.offset();
System.err.println("当前消费者:"+ threadName
+ ",消息内容:" + value
+ ", 消息的偏移量: " + messageOffset
+ "当前线程:" + Thread.currentThread().getName());
}
}
}
}finally {
if(consumer != null){
consumer.close();
}
}
}
public boolean isRunning() {
return isRunning;
}
public void setRunning(boolean running) {
isRunning = running;
}
}
然后再创建一个用于生成consumer线程的线程池:
public class MultiThreadTest {
public static void main(String[] args) {
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.31.101:9092");
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "topic-module");
properties.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, 10000);
// 改成手动提交
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
int coreSize = 5;
ExecutorService executorService = Executors.newFixedThreadPool(coreSize);
for(int i=0; i<coreSize; i++){
executorService.execute(new KafkaConsumerMultiThread1(properties, "topic-module"));
}
}
}之后在生产者端发送消息,可以观察到有五个线程共同处理发来的消息:
2. 消费者多线程模型2
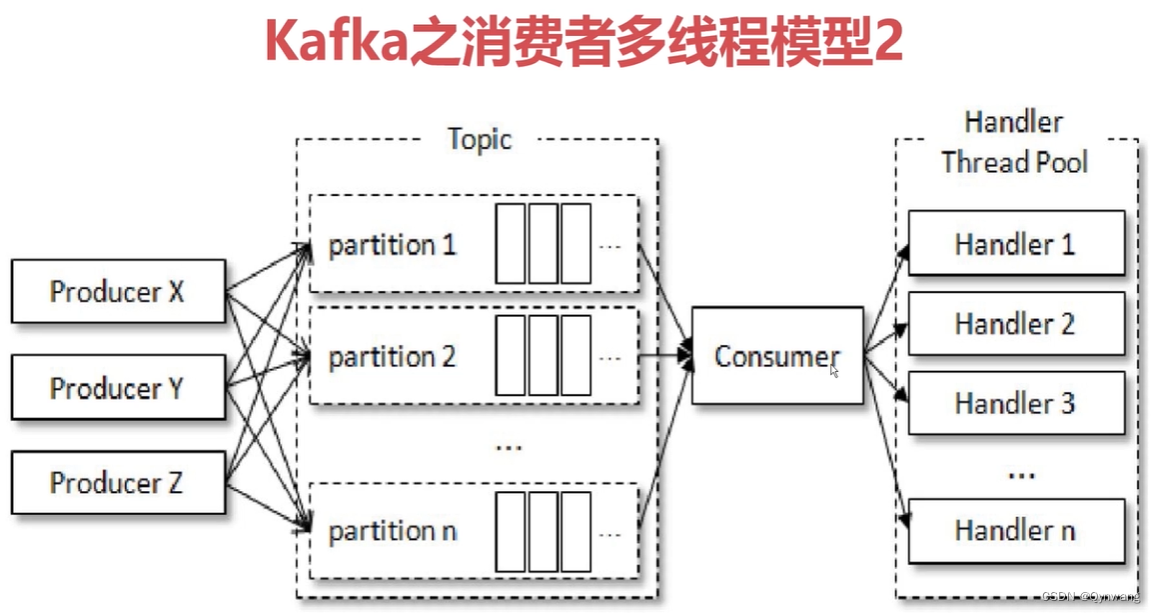
采用Master-worker模型(master负责分发,worker负责处理)。master初始化阶段,创建多个worker实例,然后master负责拉取消息,并负责分发给各个worker执行。各个worker执行完成后,将执行结果回传给master,由master统一进行commit。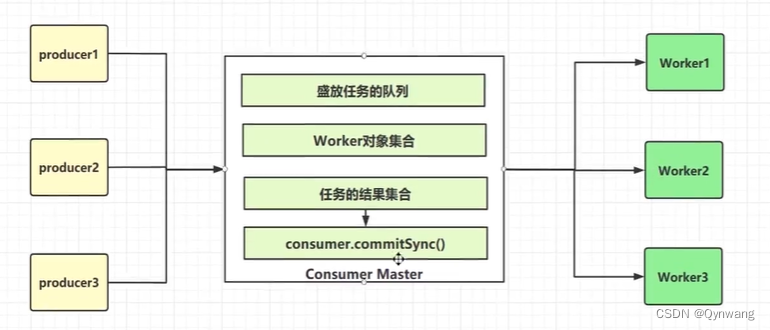
这里的master为consumer,在 consumer master 中,会有多个任务队列,用来接收生产者端的消息,consumer会创建多个worker实例,并且将任务队列中的消息交给每个队列对应的worker对象处理,,worker处理完成的结果放到任务结果集中,然后master单线程最后做 consumer.commitSync()或者consumer.commitAsync()提交操作。这里的consumer作为master是单线程的,worker是多线程的。
这样避免了多个线程操作consumer,避免出现异常ConcurrentModifacationException