实验二 RDD基础编程
前提是配置好大数据环节。
hadoop,spark,scala等必须的软件
以及下载pyshark
1.实验目的
1. 掌握 RDD 基本操作;
2. 熟悉使用 RDD 编程解决实际具体问题的方法;
2.实验内容
本人仅提供测试代码!可以给你提供思路的代码,仅供参考!
1.pyspark 交互式编程
下载 chapter4-data1.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所 示: Tom,DataBase,80 Tom,
Algorithm,50 Tom,
DataStructure,60 Jim,
DataBase,90 Jim,
Algorithm,60 Jim,
DataStructure,80 ……
请根据给定的实验数据,在 pyspark 中通过编程来计算以下内容:
(1)该系总共有多少学生;
(2)该系共开设了多少门课程;
(3)Tom 同学的总成绩平均分是多少;
(4)求每名同学的选修的课程门数;
(5)该系 DataBase 课程共有多少人选修;
(6)各门课程的平均分是多少;
(7)使用累加器计算共有多少人选了 DataBase 这门课。
# 导入必要的模块
from pyspark import SparkConf, SparkContext
# 创建 SparkConf 对象
conf = SparkConf().setAppName("SparkRDD").setMaster("local[*]")
# 创建 SparkContext 对象
sc = SparkContext(conf=conf)
# 设置日志级别为 ALL
sc.setLogLevel("WARN")
# 读取数据文件 自己改成绝对路径比较好
data_rdd = sc.textFile("./chapter4-data01.txt")
# (1) 该系总共有多少学生
students = data_rdd.map(lambda stu: stu.split(',')[0]).distinct().count()
print("该系总共有 %d 名学生" % students)
# (2) 该系共开设了多少门课程
courses = data_rdd.map(lambda c: c.split(',')[1]).distinct().count()
print("该系共开设了 %d 门课程" % courses)
# (3) Tom 同学的总成绩平均分是多少
tom_scores = data_rdd.filter(lambda s: s.startswith("Tom")).map(lambda g: int(g.split(',')[2]))
tom_avg_score = tom_scores.mean()
print("Tom 同学的总成绩平均分是 %.2f 分" % tom_avg_score)
# (4) 求每名同学的选修的课程门数
student_courses = data_rdd.map(lambda cs: (cs.split(',')[0], 1)).reduceByKey(lambda a, b: a + b).collect()
for student, course_count in student_courses:
print("%s 同学选修了 %d 门课程" % (student, course_count))
# (5) 该系 DataBase 课程共有多少人选修
db_selected_count = data_rdd.filter(lambda c: c.split(',')[1] == "DataBase").count()
print("该系 DataBase 课程共有 %d 人选修" % db_selected_count)
# (6) 各门课程的平均分是多少
course_scores = data_rdd.map(lambda line: (line.split(',')[1], int(line.split(',')[2]))).groupByKey().mapValues(lambda scores: sum(scores) / len(scores)).collect()
for course, avg_score in course_scores:
print("%s 课程的平均分是 %.2f 分" % (course, avg_score))
# (7) 使用累加器计算共有多少人选了 DataBase 这门课
db_selected_acc = sc.accumulator(0) #创建累加器对象,初始化值0
def count_db_selected(score): #将选择DataBase+1
if score.split(',')[1] == "DataBase":
db_selected_acc.add(1)
data_rdd.foreach(count_db_selected) #遍历累加
db_selected_count_acc = db_selected_acc.value #获取累加值
print("使用累加器计算,共有 %d 人选了 DataBase 这门课" % db_selected_count_acc)
# 关闭 SparkContext 对象
sc.stop()


2.编写独立应用程序实现数据去重
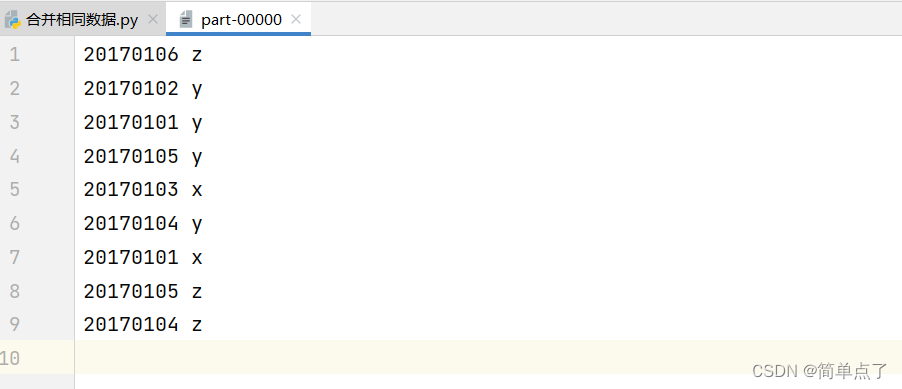
对于两个输入文件 A 和 B,编写 Spark 独立应用程序,对两个文件进行合并,并剔除其 中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的一个样例,供参考。
输入文件 A 的样例如下:
20170101 x
20170102 y
20170103 x
20170104 y
20170105 z
20170106 z
输入文件 B 的样例如下:
20170101 y
20170102 y
20170103 x
20170104 z
20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x
20170101 y
20170102 y
20170103 x
20170104 y
20170104 z
20170105 y
20170105 z
20170106 z
参考代码:
from pyspark import SparkContext, SparkConf
# 创建Spark配置对象并设置应用名称
conf = SparkConf().setAppName("Deduplication")
# 创建SparkContext对象
sc = SparkContext(conf=conf)
# 读取文件A和B 设置自己的路径
fileA = sc.textFile("A.txt")
fileB = sc.textFile("B.txt")
# 合并两个文件
mergedRDD = fileA.union(fileB)
# 去重操作
distinctRDD = mergedRDD.distinct()
# 写入输出文件C
distinctRDD.coalesce(1)
distinctRDD.saveAsTextFile("C")
# 关闭SparkContext对象
sc.stop()
3.编写独立应用程序实现求平均值问题
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生 名字,第二个是学生的成绩;
编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到 一个新文件中。下面是输入文件和输出文件的一个样例,供参考。
Algorithm 成绩: 小明 92 小红 87 小新 82 小丽 90
Database 成绩: 小明 95 小红 81 小新 89 小丽 85
Python 成绩: 小明 82 小红 83 小新 94 小丽 91
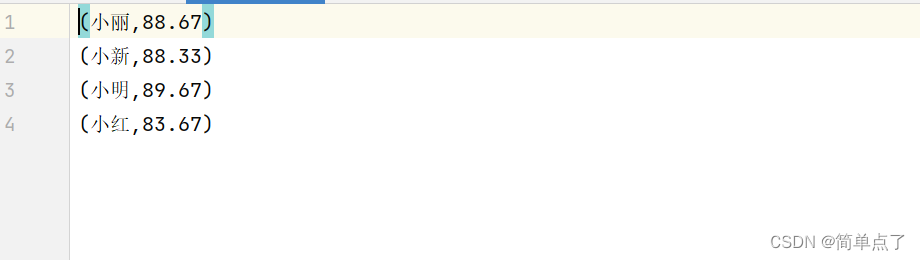
平均成绩如下: (小红,83.67) (小新,88.33) (小明,89.67) (小丽,88.67)
创建的项目不要起中文的名称
from pyspark.sql import SparkSession
from pyspark.sql.functions import split, avg
# 创建SparkSession
spark = SparkSession.builder \
.appName("CalculateAverageScore") \
.getOrCreate()
# 读取输入文件并创建DataFrame
input_files = [
".\\input\\input_file1.txt",
".\\input\\input_file2.txt",
".\\input\\input_file3.txt"
]
# 合并所有输入文件的数据
scores_df = spark.read.text(input_files)
scores_df = scores_df.withColumn("data", split(scores_df["value"], " "))
scores_df = scores_df.select(scores_df["data"][0].alias("name"), scores_df["data"][1].cast("float").alias("score"))
# 使用DataFrame进行数据处理,计算每个学生的平均成绩
average_scores_df = scores_df.groupBy("name").agg(avg("score").alias("average_score"))
average_scores_df = average_scores_df.orderBy("name")
# 将结果输出到新文件
output_file = "./output.txt"
# 将结果转换为字符串格式
result_str = average_scores_df.rdd \
.map(lambda row: f"({row['name']},{row['average_score']:.2f})") \
.collect()
# 将结果写入文件
with open(output_file, "w") as file:
file.write("\n".join(result_str))
# 停止SparkSession
spark.stop()
生成的效果图
 3.资源地址
3.资源地址
https://download.csdn.net/download/weixin_41957626/87780485