【自然语言处理(NLP)】基于Word2Vec的语言模型实践

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于Word2Vec的语言模型实践
- 前言
- (一)、任务描述
- (二)、效果说明
- 一、数据准备
- (一)、数据集下载
- (二)、模型调用
- 训练或fine-tune
- 二、进阶使用
- (一)、任务定义与建模
- (二)、模型原理介绍
- (三)、数据格式说明
- (四)、目录结构
- 三、组建模型
- (一)、自定义数据
- (二)、网络结构更改
- 四、相关代码
- (一)、解压数据集
- (二)、模型训练
- (三)、模型预测
- 总结
前言
(一)、任务描述
本文主要介绍基于lstm的语言的模型的实现,给定一个输入词序列(中文分词、英文tokenize),计算其ppl(语言模型困惑度,用户表示句子的流利程度),基于循环神经网络语言模型的介绍可以参阅论文。相对于传统的方法,基于循环神经网络的方法能够更好的解决稀疏词的问题。
(二)、效果说明
在small meidum large三个不同配置情况的ppl对比:
| small config | train | valid | test |
|---|---|---|---|
| paddle | 40.962 | 118.111 | 112.617 |
| tensorflow | 40.492 | 118.329 | 113.788 |
| medium config | train | valid | test |
|---|---|---|---|
| paddle | 45.620 | 87.398 | 83.682 |
| tensorflow | 45.594 | 87.363 | 84.015 |
| large config | train | valid | test |
|---|---|---|---|
| paddle | 37.221 | 82.358 | 78.137 |
| tensorflow | 38.342 | 82.311 | 78.121 |
一、数据准备
(一)、数据集下载
此任务的数据集合是采用ptb dataset,下载地址为: http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz
(二)、模型调用
训练或fine-tune
任务训练启动命令如下:
!python train.py --use_gpu True --data_path data/data11325/simple-examples/data --model_type small --rnn_model basic_lstm
- 需要指定数据的目录,默认训练文件名为 ptb.train.txt,可用–train_file指定;默认验证文件名为 ptb.valid.txt,可用–eval_file指定;默认测试文件名为 ptb.test.txt,可用–test_file指定
- 模型的大小(默认为small,用户可以选择medium, 或者large)
- 模型的类型(默认为static,可选项static|padding|cudnn|basic_lstm)
- batch大小默认和模型大小有关,可以通过–batch_size指定
- 训练轮数默认和模型大小有关,可以通过–max_epoch指定
- 默认将模型保存在当前目录的models目录下
二、进阶使用
(一)、任务定义与建模
此任务目的是给定一个输入的词序列,预测下一个词出现的概率。
(二)、模型原理介绍
此任务采用了序列任务常用的rnn网络,实现了一个两层的lstm网络,然后lstm的结果去预测下一个词出现的概率。计算的每一个概率和实际下一个词的交叉熵,然后求和,做e的次幂,得到困惑度ppl。当前计算方式和句子的长度有关,仍需要继续优化。
由于数据的特殊性,每一个batch的last hidden和last cell会被作为下一个batch 的init hidden 和 init cell,数据的特殊性下节会介绍。
(三)、数据格式说明
此任务的数据格式比较简单,每一行为一个已经分好词(英文的tokenize)的词序列。
目前的句子示例如下图所示:
aer banknote berlitz calloway centrust cluett fromstein gitano guterman hydro-quebec ipo kia memotec mlx nahb punts rake regatta rubens sim snack-food ssangyong swapo wachter
pierre <unk> N years old will join the board as a nonexecutive director nov. N
mr. <unk> is chairman of <unk> n.v. the dutch publishing group
特殊说明:ptb的数据比较特殊,ptb的数据来源于一些文章,相邻的句子可能来源于一个段落或者相邻的段落,ptb 数据不能做shuffle
(四)、目录结构
.
├── train.py # 训练代码
├── reader.py # 数据读取
├── args.py # 参数读取
├── config.py # 训练配置
├── data # 数据下载
├── language_model.py # 模型定义文件
三、组建模型
(一)、自定义数据
关于数据,如果可以把自己的数据先进行分词(或者tokenize),然后放入到data目录下,并修改reader.py中文件的名称,如果句子之间没有关联,用户可以将train.py中更新的代码注释掉。
init_hidden = np.array(fetch_outs[1])
init_cell = np.array(fetch_outs[2])
(二)、网络结构更改
网络只实现了基于lstm的语言模型,用户可以自己的需求更换为gru或者self等网络结构,这些实现都是在language_model.py 中定义
四、相关代码
(一)、解压数据集
# 解压数据集
!cd data/data11325 && unzip -qo simple-examples.zip
(二)、模型训练
# 运行训练,使用GPU,并且使用小模型
# 训练轮数也限制到3轮,以避免日志过多
# 最终可以通过提高训练轮数达到比较好的效果
!echo "training"
!python train.py --use_gpu True --data_path data/data11325/simple-examples/data --model_type small --rnn_model basic_lstm --max_epoch=3
部分输出结果如下图1所示:
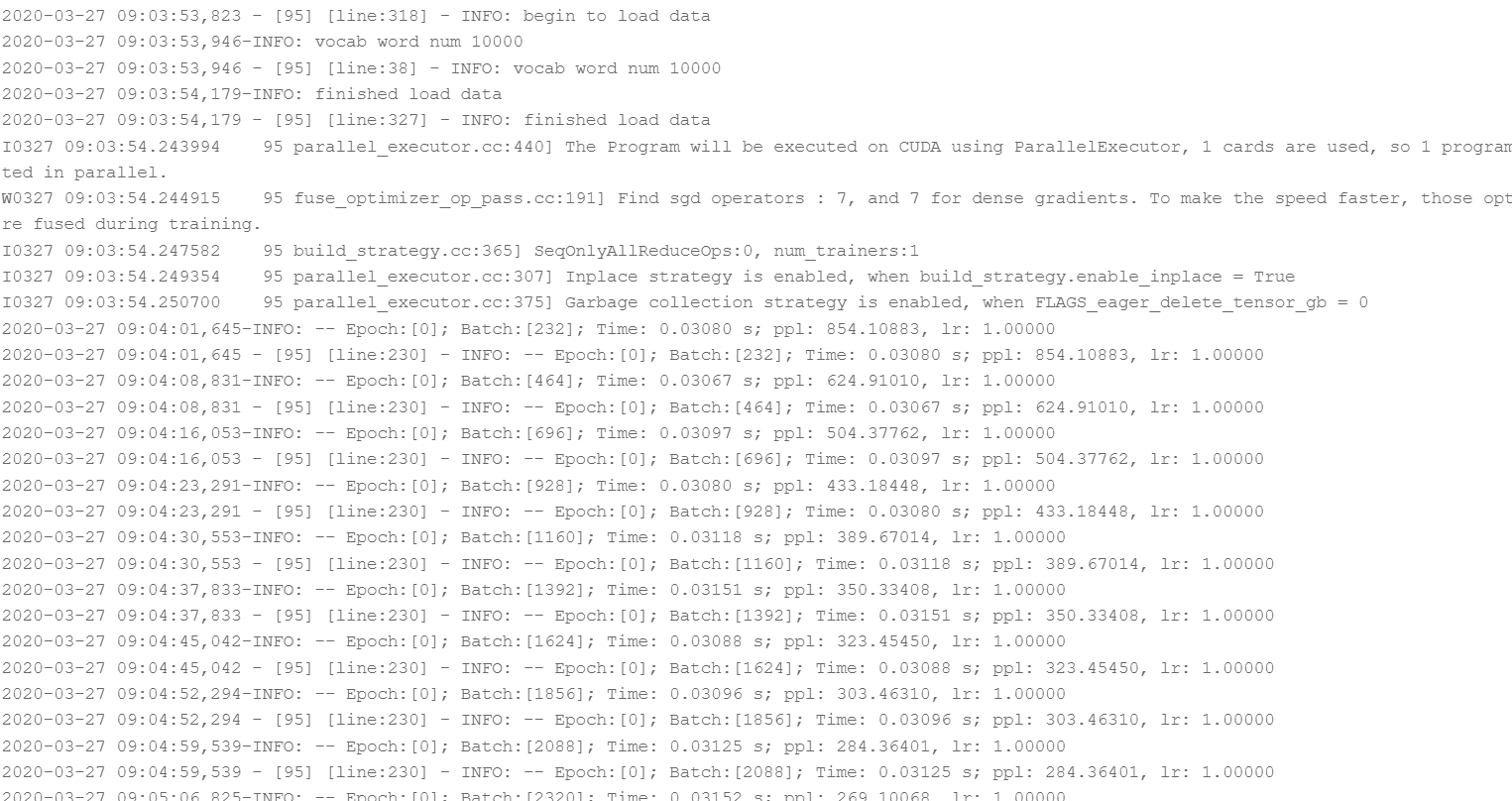
(三)、模型预测
# 加模型进行预测
!python infer.py --rnn_model basic_lstm
输出结果如下图2所示:
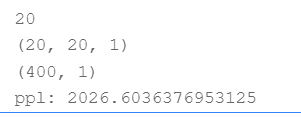
总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~




![[附源码]JAVA毕业设计高校在线办公系统(系统+LW)](https://img-blog.csdnimg.cn/a993363041b94a318ebba697c7a2916a.png)
![[附源码]计算机毕业设计springboot社区住户信息管理系统](https://img-blog.csdnimg.cn/5e667633faf542a9acd0c8cbf7a28ce7.png)
![[附源码]Python计算机毕业设计Django高校商铺管理系统论文](https://img-blog.csdnimg.cn/19d749d6f74545939e45d2db8c293f7a.png)