Hive的概念
Hive是Facebook开源出来,后来贡献给力Apache .宗旨是:提高分析数据的能力降低分析数据的开发成本。
Hive是基于 Hadoop 的一个数据仓库工具,用于分析数据的。
为什么说Hive是基于Hadoop的呢? #作为一款数据仓库软件,应该要具备哪些能力? 具备存储数据的能力 具备分析数据的能力 Hive作为数仓软件,当然具备上述两种能力? #Hive使用Hadoop HDFS作为数据存储系统 #Hive使用Hadoop MapReduce来分析数据 基于此说Hive是基于Hadoop的数仓软件。在此过程中,Hive做了什么?其最大的魅力在哪里?
可以将结构化的数据文件映射为一张数据库表,并提供==类 SQL 查询==功能。
结构化数据:具有schema约束的数据 便于程序解读解析 映射 y=2X+1 当x=1 y=3 映射表示的就是一种对应关系。 映射成为表之后 提供了类SQl查询分析功能。 SQL叫做声明式编程,程序员不用关系过程,利于数据分析。
Hive的架构组件
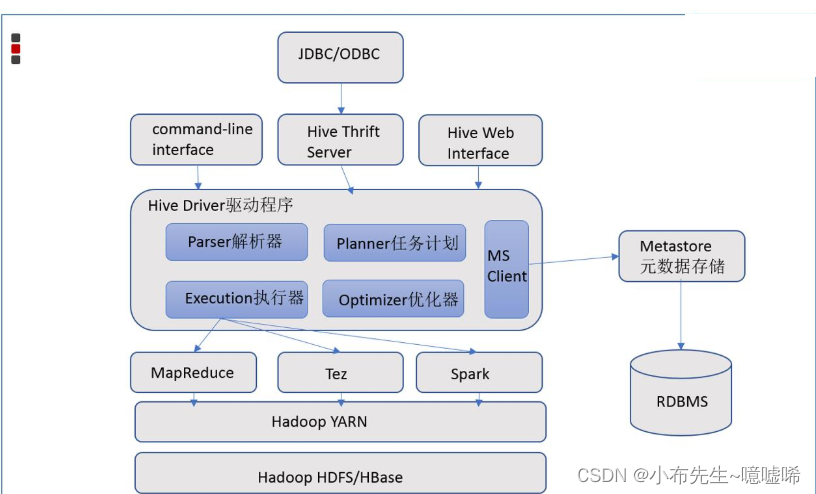
客户端用户接口
所谓的客户端指的是给用户一种方式编写Hive SQL 目前常见的客户端:CLI(命令行接口 shell)、Web UI、JDBC|ODBCHive Driver驱动程序
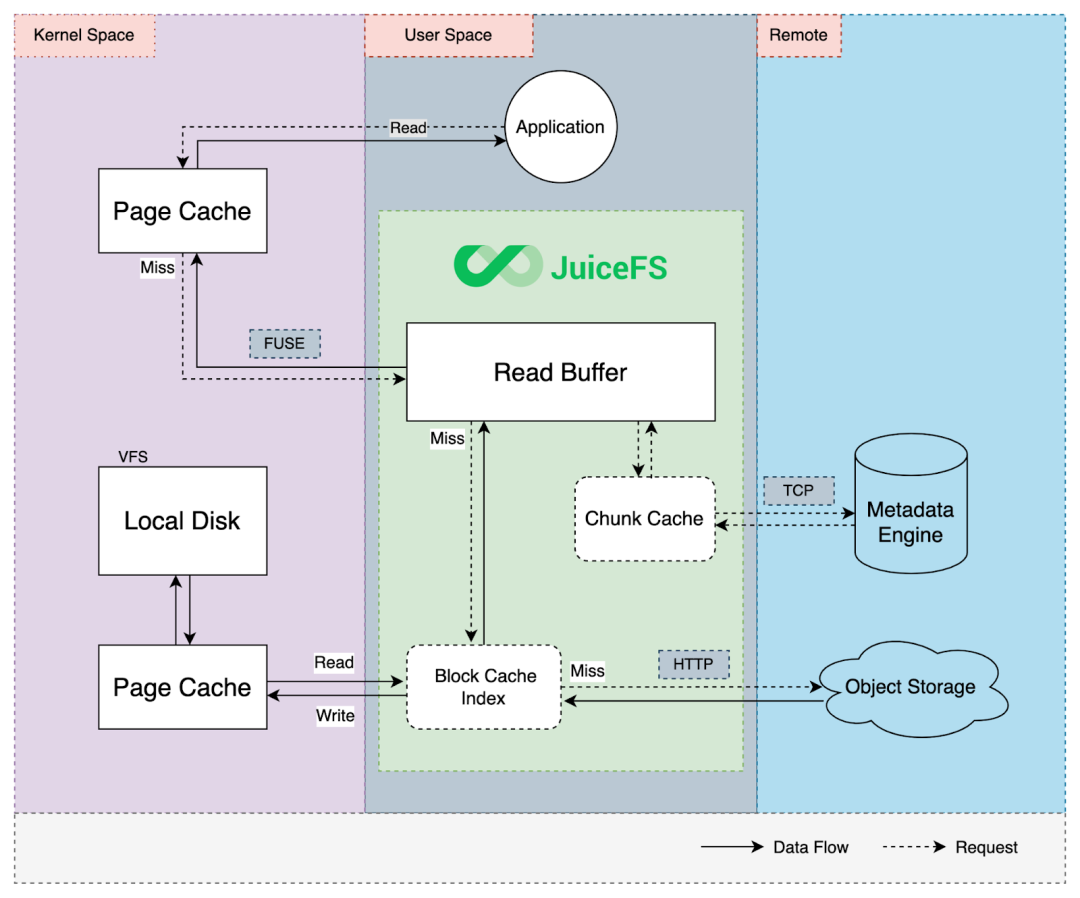
hive的核心 完成从接受HQL到编译成为MR程序的过程。 sql解释 编译 校验 优化 制定计划metadata
元数据存储。 描述性数据。 对于hive来说,元数据指的是表和文件之间的映射关系。Hadoop
HDFS 存储文件 MapReduce 计算数据 YARN 程序运行的资源分配Q:Hive是分布式的软件吗?
Hive不是分布式软件。只需要在一台机器上部署Hive服务即可; Hive的分布式处理能力是借于Hadoop完成的。HDFS分布式存储 MapReduce分布式计算。
Hive和Mysql的区别
Metadata、metastore
#Metadata 元数据
对于hive来说,元数据主要指的是表和文件之间的映射关系。
元数据也是数据,存储在哪里呢?Hive当下支持两种地方存储元数据。
1、存储在Hive内置的RDBSM中,Apache Derby(内存级别轻量级关系型数据库)
2、存储在外界第三方的RDBMS中,比如:MySQL。 企业中常用的方式。#metastore 元数据访问服务
专门用于操作访问metadata的一种服务,对外暴露服务地址给各个不同的客户端使用访问Hive的元数据。
并且某种程度上保证了metadata的安全。
Hive的安装部署模式
如何区别,关键在于两个问题?
==metadata元数据是存储在哪里的?== 内置derby还是外置的Mysql。
==metastore服务是否需要单独配置,单独手动启动?==
具体来说
==内嵌模式==
1、元数据存储在内置的derby 2、不需要单独配置metastore 也不需要单独启动metastore服务 安装包解压即可使用。 适合测试体验。实际生产中没人用。适合单机单人使用。==本地模式==
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。 2、不需要单独配置metastore 也不需要单独启动metastore服务==远程模式==
1、元数据使用外置的RDBMS,常见使用最多的是MySQL。 2、metastore服务单独配置 单独手动启动 全局唯一。 这样的话各个客户端只能通过这一个metastore服务访问Hive. 企业生产环境中使用的模式,支持多客户端远程并发操作访问Hive. 也是我们课程中使用的模式。对比
metadata存储在哪 metastore服务如何 内嵌模式 Derby 不需要配置启动 本地模式 MySQL 不需要配置启动 ==远程模式== ==MySQL== ==单独配置、单独启动==
安装Hive
#apache-hive-3.1.2-bin.tar.gz 上传、解压 tar zxvf apache-hive-3.1.2-bin.tar.gz
0、解决Hive与Hadoop之间guava版本差异
cd /export/server/apache-hive-3.1.2-bin/ rm -rf lib/guava-19.0.jar cp /export/server/hadoop-3.3.0/share/hadoop/common/lib/guava-27.0-jre.jar ./lib/
1、==hive-env.sh==
cd /export/server/apache-hive-3.1.2-bin/conf mv hive-env.sh.template hive-env.sh vim hive-env.sh export HADOOP_HOME=/export/server/hadoop-3.3.0 export HIVE_CONF_DIR=/export/server/apache-hive-3.1.2-bin/conf export HIVE_AUX_JARS_PATH=/export/server/apache-hive-3.1.2-bin/lib2、==hive-site.xml==
vim hive-site.xml
<configuration> <!-- 存储元数据mysql相关配置 --> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://node1:3306/hive3?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <!-- H2S运行绑定host --> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> </property> <!-- 远程模式部署metastore metastore地址 --> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> <!-- 关闭元数据存储授权 --> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> </configuration> 3、上传Mysql jdbc驱动到Hive安装包的Lib目录下
mysql-connector-java-5.1.32.jar4、手动执行命令初始化Hive的元数据
cd /export/server/apache-hive-3.1.2-bin/ bin/schematool -initSchema -dbType mysql -verbos #初始化成功会在mysql中创建74张表5、在hdfs创建hive存储目录
hadoop fs -mkdir /tmp hadoop fs -mkdir -p /user/hive/warehouse hadoop fs -chmod g+w /tmp hadoop fs -chmod g+w /user/hive/warehouse
Hive 服务的启动
metastore服务
前台启动
#前台启动 /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore #前台启动开启debug日志 /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore --hiveconf hive.root.logger=DEBUG,console #前台启动关闭方式 ctrl+c结束进程后台挂起启动
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore & #后台挂起启动 结束进程 使用jps查看进程 使用kill -9 杀死进程 #nohup 命令,在默认情况下(非重定向时),会输出一个名叫 nohup.out 的文件到当前目录下
Hive的客户端
Hive的第一代客户端
==bin/hive==
直接访问metastore服务
配置
<configuration> <property> <name>hive.metastore.uris</name> <value>thrift://node1:9083</value> </property> </configuration>弊端:
第一代客户端属于shell脚本客户端 性能友好安全方面存在不足 Hive已经不推荐使用 官方建议使用第二代客户端beelineHive的第二代客户端
bin/beeline
无法访问metastore服务,只能够访问==Hiveserver2服务==。
使用
# 拷贝node1上 hive安装包到beeline客户端机器上(node3) scp -r /export/server/apache-hive-3.1.2-bin/ node3:/export/server/ #1、在安装hive的服务器上 首先启动metastore服务 再启动hiveserver2服务 nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore & nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 & #2、在任意机器(如node3)上使用beeline客户端访问 [root@node3 ~]# /export/server/apache-hive-3.1.2-bin/bin/beeline beeline> ! connect jdbc:hive2://node1:10000 #jdbc访问HS2服务 Connecting to jdbc:hive2://node1:10000 Enter username for jdbc:hive2://node1:10000: root #用户名 要求具备HDFS读写权限 Enter password for jdbc:hive2://node1:10000: #密码可以没有