- 聚类假设
假设输入数据点形成簇,每个簇对应于一个输出类,那么如果点在同一个簇中,则它们可以认为属于同一类。聚类假设也可以被视为低密度分离假设,即:给定的决策边界位于低密度地区。两个假设之间的关系很容易看出。一个高密度区域,可能会将一个簇分为两个不同的类别,从而产生属于同一聚类的不同类,这违反了聚类假设。在这种情况下,我们可以限制我们的模型在一些小扰动的未标记数据上具有一致的预测,以将其判定边界推到低密度区域。 - 深度半监督学习的一个新的研究方向是利用未标记的数据来强化训练模型,使其符合聚类假设,即学习的决策边界必须位于低密度区域。这些方法基于一个简单的概念,即如果对一个未标记的数据应用实际的扰动,则预测不应发生显著变化,因为在聚类假设下,具有不同标签的数据点在低密度区域分离。

3. Temporal Ensembling for Semi-Supervised Learning
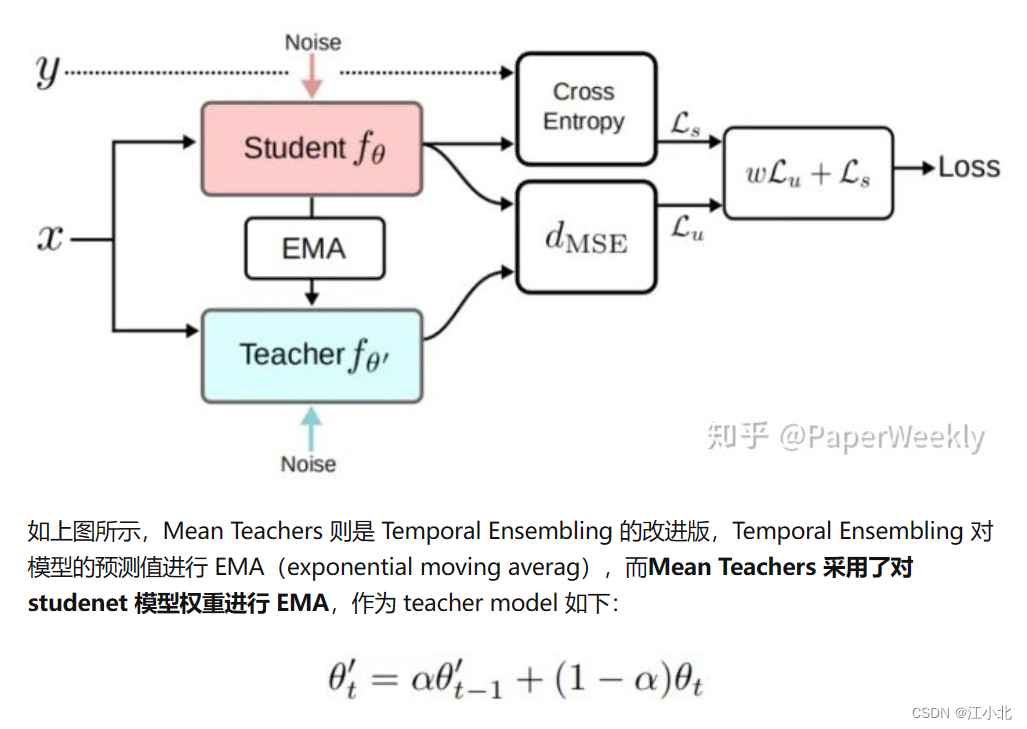
4. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
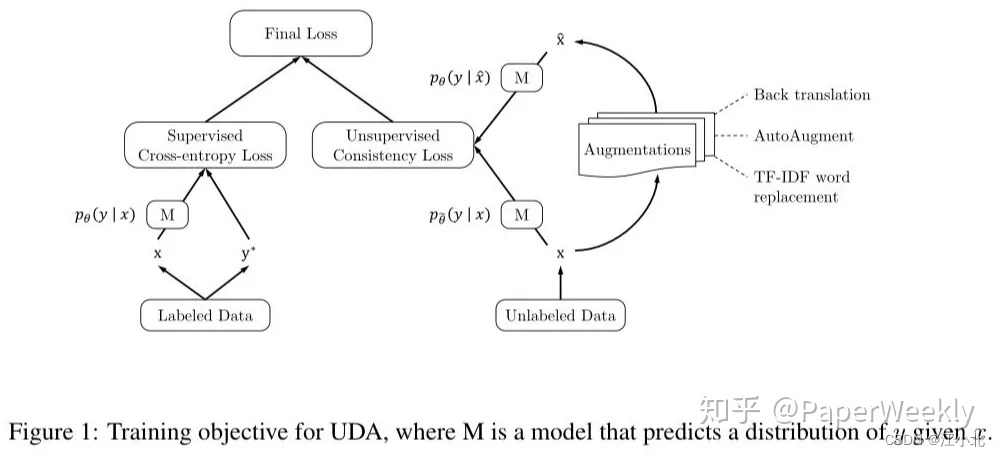
5. Unsupervised Data Augmentation for Consistency Training
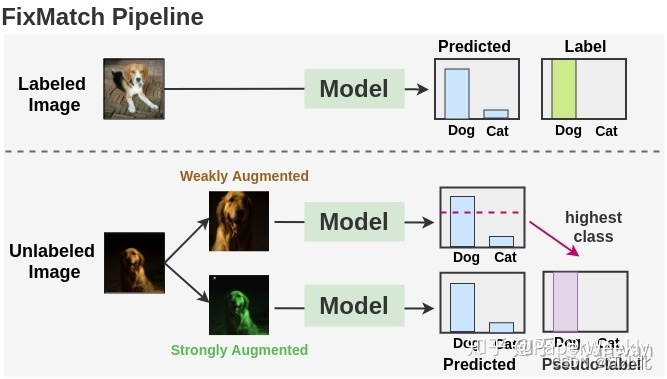
6. FixMatch
FixMatch 是 Google Brain 提出的一种 Holistic 的半监督学习方法,与以往的Holistic Methods不同的是,FixMatch 使用交叉熵将 weakly augment 和 strong augment 的无标签数据进行比较,并取得了不错的效果。其巧妙之处是:一致性正则化使用的是交叉熵损失函数。FixMatch 是对弱增强图像与强增强图像之间的进行一致性正则化,但是其没有使用两种图像的概率分布一致,而是使用弱增强的数据制作了伪标签,这样就自然需要使用交叉熵进行一致性正则化了。此外,FixMatch 仅使用具有高置信度的未标记数据参与训练。









![[架构之路-195]-《软考-系统分析师》- MVC、MVP、MVVM架构各自的优缺点](https://img-blog.csdnimg.cn/img_convert/81699fd66df3c2b96a522056182d6288.png)