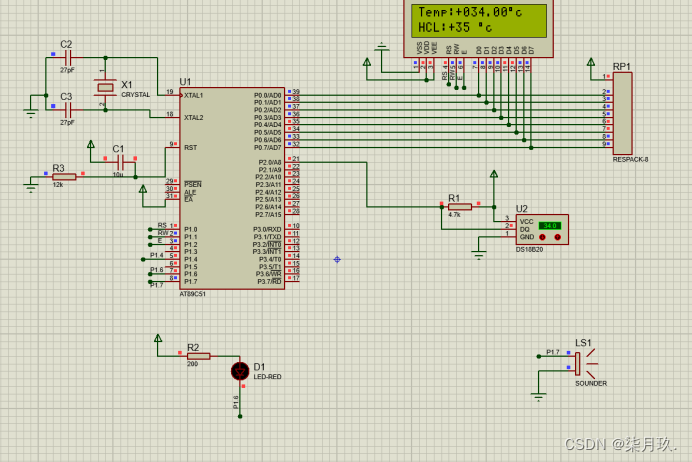
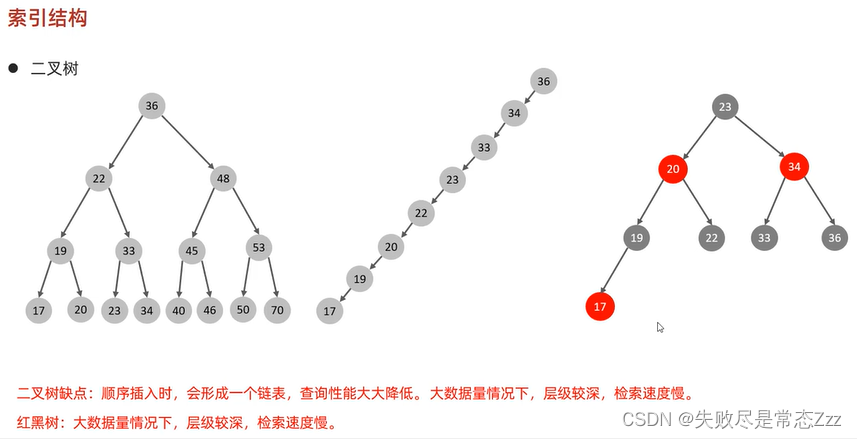
二叉树
B-Tree

B+Tree
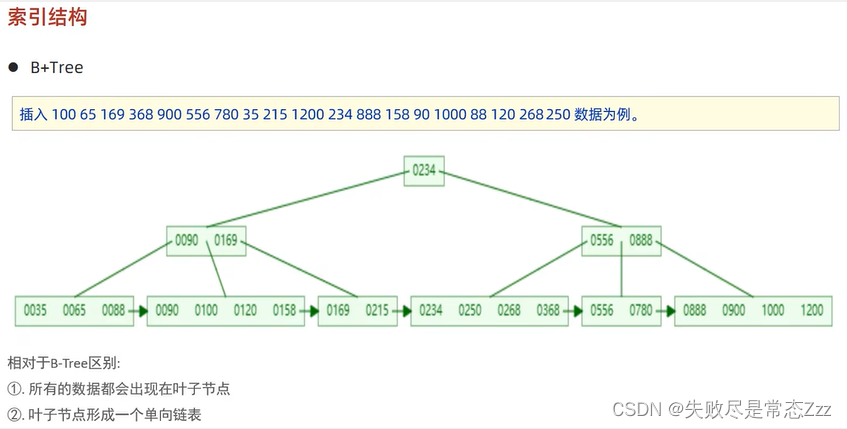
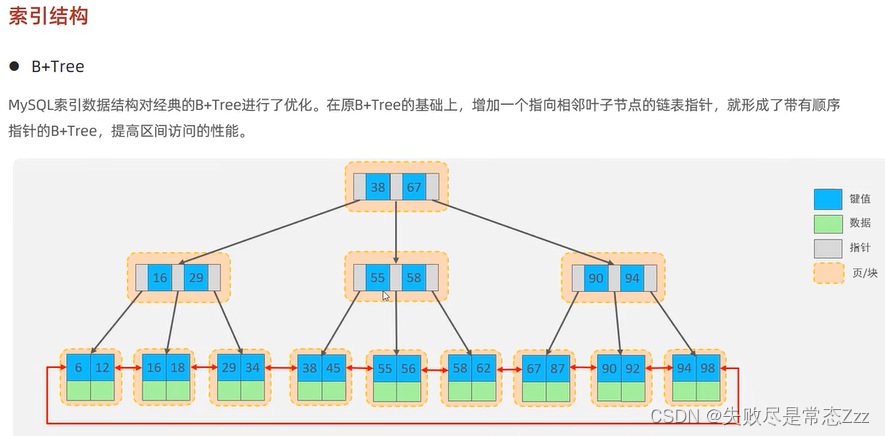
一、为何使用 B+ 树而非二叉查找树做索引?
我们知道二叉树的查找效率为 O(logn),当树过高时,查找效率会下降。另外由于我们的索引文件并不小,所以是存储在磁盘上的。
文件系统需要从磁盘读取数据时,一般以页为单位进行读取,假设一个页内的数据过少,那么操作系统就需要读取更多的页,涉及磁盘随机 I/O 访问的次数就更多。将数据从磁盘读入内存涉及随机 I/O 的访问,是数据库里面成本最高的操作之一。
因而这种树高会随数据量增多急剧增加,每次更新数据又需要通过左旋和右旋维护平衡的二叉树,不太适合用于存储在磁盘上的索引文件。
二、为何使用 B+ 树而非 B 树做索引?
B+ 树和 B 树的区别:
B 树非叶子结点和叶子结点都存储数据,因此查询数据时,时间复杂度最好为 O(1),最坏为 O(log n)。而 B+ 树只在叶子结点存储数据,非叶子结点存储关键字,且不同非叶子结点的关键字可能重复,因此查询数据时,时间复杂度固定为 O(log n)。
B+ 树叶子结点之间用链表相互连接,因而只需扫描叶子结点的链表就可以完成一次遍历操作,B 树只能通过中序遍历。
为什么 B+ 树比 B 树更适合应用于数据库索引?
1.B+ 树减少了 IO 次数。
由于索引文件很大因此索引文件存储在磁盘上,B+ 树的非叶子结点只存关键字不存数据,因而单个页可以存储更多的关键字,即一次性读入内存的需要查找的关键字也就越多,磁盘的随机 I/O 读取次数相对就减少了。
2.B+ 树查询效率更稳定
由于数据只存在在叶子结点上,所以查找效率固定为 O(log n),所以 B+ 树的查询效率相比B树更加稳定。
3.B+ 树更加适合范围查找
B+ 树叶子结点之间用链表有序连接,所以扫描全部数据只需扫描一遍叶子结点,利于扫库和范围查询;B 树由于非叶子结点也存数据,所以只能通过中序遍历按序来扫。也就是说,对于范围查询和有序遍历而言,B+ 树的效率更高。