五、阻塞队列
目录
五、阻塞队列
5.1 阻塞队列是什么 ?
5.1.1 生产者消费者模型
编辑
5.1.2 标准库中的阻塞队列
5.1.3 消息队列
5.1.4 消息队列的作用
5.2 实现一个阻塞队列
虚假唤醒
六、线程池
6.1 线程池是什么?
6.2 怎么使用线程池?
6.2.1 JDK给我们提供了一些方法来创建线程池(不建议使用)
6.2.2 工厂模式
6.2.3 自定义一个线程池
为什么不推荐使用系统自带的线程池?
5.1 阻塞队列是什么 ?
- 当队列满的时候, 继续入队列就会阻塞, 直到有其他线程从队列中取走元素.
- 当队列空的时候, 继续出队列也会阻塞, 直到有其他线程往队列中插入元素.
- 阻塞队列的一个典型应用场景就是 "生产者消费者模型". 这是一种非常典型的开发模型.
举个栗子:
5.1.1 生产者消费者模型
比如在 " 秒杀 " 场景下 , 服务器同一时刻可能会收到大量的支付请求 . 如果直接处理这些支付请求 , 服务器可能扛不住( 每个支付请求的处理都需要比较复杂的流程 ). 这个时候就可以把这些请求都放到一个阻塞队列中, 然后再由消费者线程慢慢的来处理每个支付请求 .这样做可以有效进行 " 削峰 ", 防止服务器被突然到来的一波请求直接冲垮 .
比如过年一家人一起包饺子 . 一般都是有明确分工 , 比如一个人负责擀饺子皮 , 其他人负责包 . 擀饺子皮的人就是 " 生产者 ", 包饺子的人就是 " 消费者 ".擀饺子皮的人不关心包饺子的人是谁 ( 能包就行 , 无论是手工包 , 借助工具 , 还是机器包 ), 包饺子的人也不关心擀饺子皮的人是谁( 有饺子皮就行 , 无论是用擀面杖擀的 , 还是拿罐头瓶擀 , 还是直接从超市买的).

5.1.2 标准库中的阻塞队列
- BlockingQueue 是一个接口. 真正实现的类是 LinkedBlockingQueue.
- put 方法用于阻塞式的入队列, take 用于阻塞式的出队列.
- BlockingQueue 也有 offer, poll, peek 等方法, 但是这些方法不带有阻塞特性.
BlockingQueue<String> queue = new LinkedBlockingQueue<>();
// 入队列
queue.put("abc");
// 出队列. 如果没有 put 直接 take, 就会阻塞.
String elem = queue.take();
//生产者消费者模型
public static void main(String[] args) throws InterruptedException {
BlockingQueue<Integer> blockingQueue = new LinkedBlockingQueue<Integer>();
Thread customer = new Thread(() -> {
while (true) {
try {
int value = blockingQueue.take();
System.out.println("消费元素: " + value);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "消费者");
customer.start();
Thread producer = new Thread(() -> {
Random random = new Random();
while (true) {
try {
int num = random.nextInt(1000);
System.out.println("生产元素: " + num);
blockingQueue.put(num);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "生产者");
producer.start();
customer.join();
producer.join();
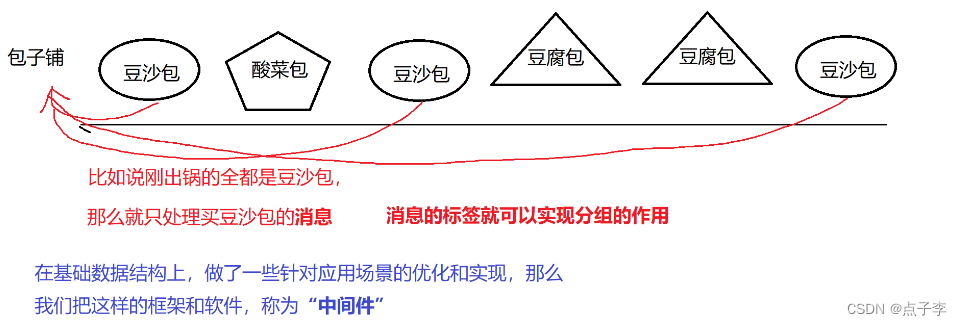
}5.1.3 消息队列
本质上就是一个阻塞队列,在此基础上为放入阻塞队列的消息打一个标签.
实现了分组的作用
5.1.4 消息队列的作用
1.解耦:以下通过画图解释 更加易懂

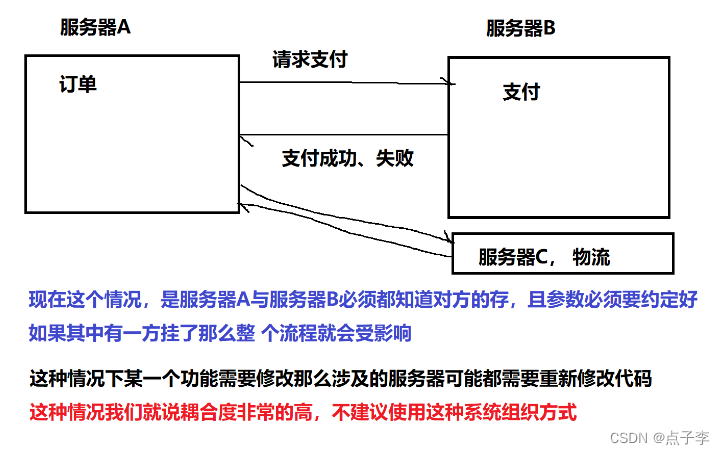
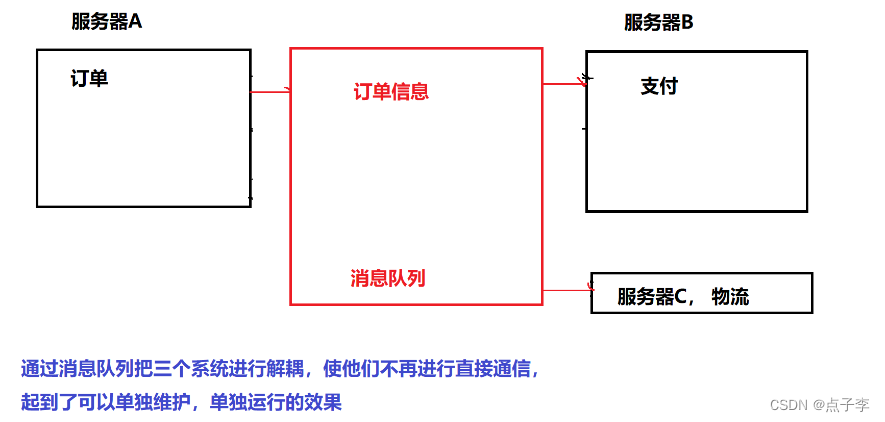
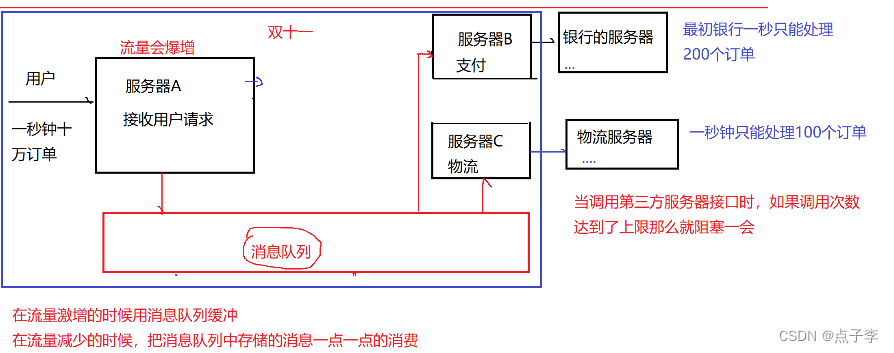
2. 削峰填谷
峰与谷指消息的密集程度
举个栗子:三峡大坝
汛期:起到蓄水的功能,防止下游遭受洪峰的冲击 削峰
旱期:可以把存的水源源不断地向下游排放 填谷
再比如说 在工程环境中的应用 微博出现热点事件时


3. 异步:发出请求之后,自己去干别的事情,有响应时会接受到通从而处理响应
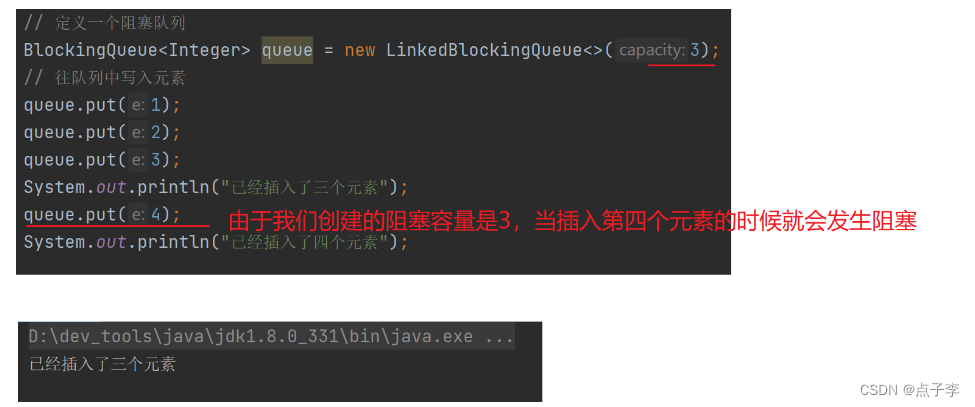
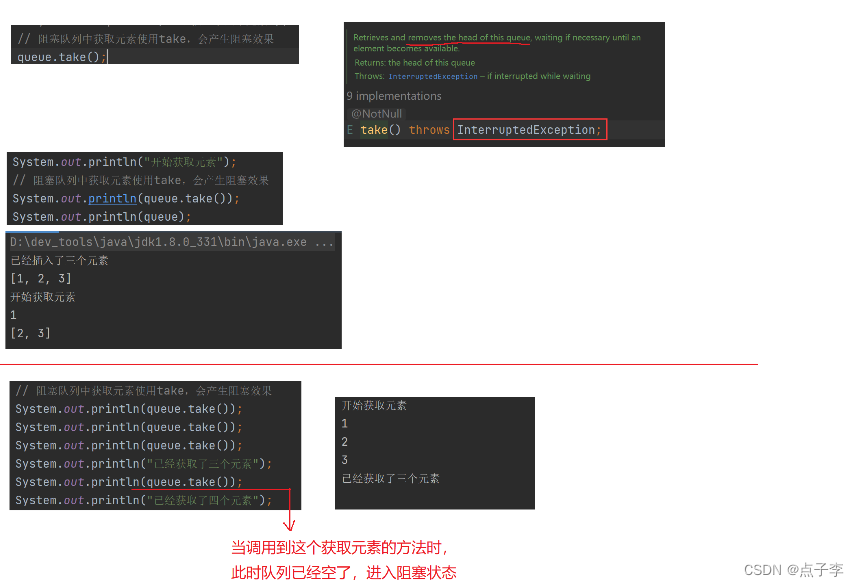
演示JDK中提供的阻塞队列:

public static void main(String[] args) throws InterruptedException {
// 定义一个阻塞队列
BlockingQueue<Integer> queue = new LinkedBlockingQueue<>(3);
// 往队列中写入元素
queue.put(1);
queue.put(2);
queue.put(3);
System.out.println("已经插入了三个元素");
System.out.println(queue);
// queue.put(4);
// System.out.println("已经插入了四个元素");
System.out.println("开始获取元素");
// 阻塞队列中获取元素使用take,会产生阻塞效果
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println(queue.take());
System.out.println("已经获取了三个元素");
System.out.println(queue.take());
System.out.println("已经获取了四个元素");
System.out.println(queue);
}
}
5.2 实现一个阻塞队列
- 之前实现一个普通队列,底层运用到了两种数据结构,一个是链表,一个是循环数组
- 阻塞队列就是在普通的队列上加入了阻塞等待的操作
代码实现:
public class MyBlockingQueue {
// 定义一个保存元素的数组
private int[] elementData = new int[100];
// 定义队首下标
private volatile int head;
// 定义队尾下标
private volatile int tail;
// 定义一个有效元素的个数
private volatile int size;
/**
* 插入一个元素
* @param value
*/
public void put (int value) throws InterruptedException {
// 根所修改共享变量的范围加锁,锁对象this即可
synchronized (this) {
// 判断数据是不是已经满了
while (size >= elementData.length) {
// 阻塞等待
this.wait();
}
// 向队尾去插入元素
elementData[tail] = value;
// 移动队尾下标
tail++;
// 修正队尾下标
if (tail >= elementData.length) {
tail = 0;
}
// 修改有效元素的个数
size++;
// 做唤醒操作
this.notifyAll();
}
}
/**
* 获取一个元素
* @return
*/
public int take() throws InterruptedException {
// 根所修改共享变量的范围加锁
// 锁对象this即可
synchronized (this) {
// 判断队列是否为空
while (size <= 0) {
this.wait();
}
// 从队首出队
int value = elementData[head];
// 移动队首下标
head++;
// 修改队首下标
if (head >= elementData.length) {
head = 0;
}
// 修改有效元素的个数
size--;
// 唤醒操作
this.notifyAll();
// 返回队首元素
return value;
}
}
}
图文分析:
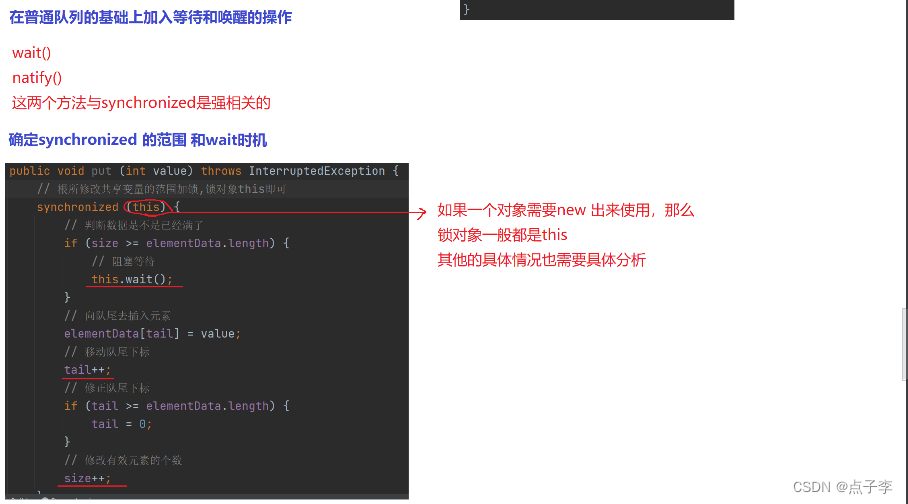
分析后发现整个方法都存在修改共享变量的操作,所以给整个方法加锁
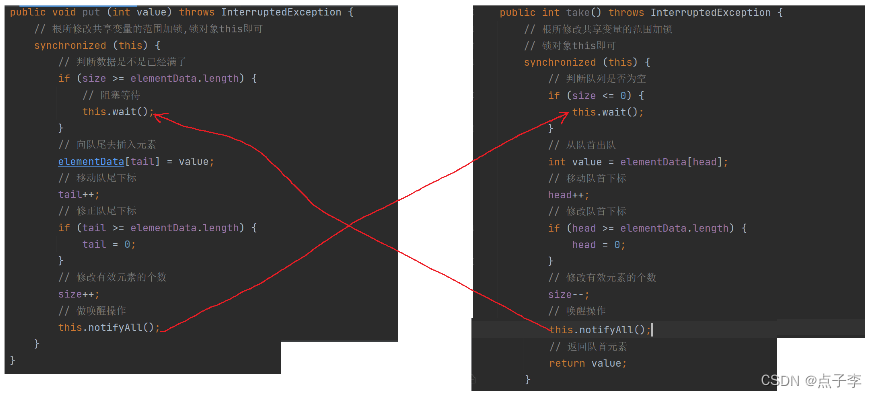
确定唤醒时机

测试结果符合预期
虚假唤醒

线程也可以在没有通知、中断或超时的情况下唤醒,即所谓的虚假唤醒。虽然这种情况在现实生活中很少发生,但应用程序必须通过测试应该导致线程被唤醒的条件来防止这种情况,如果条件不满足,则继续等待。换句话说,等待应该总是出现在循环中。
简而言之,第一次满足的条件,线程进入阻塞状态,那被唤醒之后,这期间会发生很多事情,有一种可能是被唤醒之后等待条件依然成立,答案是肯定的,所以需要再次检查等待条件。
所以代码中所有需要条件判断的wait,强烈建议加入到while循环中
六、线程池
6.1 线程池是什么?
JDBC编程中,通过DataSourse获取Connection的时候就已经用到了池的概念

当JAVA程序需要数据库连接的时候,就从池子中拿一个空闲的连接对象给JAVA程序,JAVA程序用完了连接之后就会返回给连接池,线程池就是在池子里放的线程本身,当程序启动的时候就创建出若干个线程,如果有任务就处理,没有任务就阻塞等待.
举个栗子:
在学校附近新开了一家快递店老板很精明,想到一个与众不同的方法来经营,店里没有雇人,而是每次有业务来了,就现场找一名同学把快递送了,然后解雇同学,这个类比我们平时来一个任务,起一个线程进行处理的模式。
很快,老板发现问题来了,每次招聘和解雇同学的成本还是非常高的,老板还是很善于变通的,知道为什么大家都要雇人了,所以指定每一个指标,公司业务人员会扩张到三个人,但是还是随着业务逐步雇人,于是再有业务来了,老板就看,如果现在公司还没三个人,就雇一个人去送快递,否则只是把业务放在一个本本上,等着三个快递人员空闲的时候去处理。这就是我们要带出的线程池的模式线程池,最大的好处就是减少每次启动销毁线程的损耗。

6.2 怎么使用线程池?
6.2.1 JDK给我们提供了一些方法来创建线程池(不建议使用)
// 1. 用来处理大量短时间工作任务的线程池,如果池中没有可用的线程将创建新的线程,如果线程空闲60秒将收回并移出缓存
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
// 2. 创建一个操作无界队列且固定大小线程池 (3)创建线程时,池中包含了3条线程
(无界队列:对于队列中的元素不加个数,可能会出现内存被消耗殆尽的情况)
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
// 3. 创建一个操作无界队列且只有一个工作线程的线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
// 4. 创建一个单线程执行器,可以在给定时间后执行或定期执行。
ScheduledExecutorService singleThreadScheduledExecutor = Executors.newSingleThreadScheduledExecutor();
// 5. 创建一个指定大小的线程池,可以在给定时间后执行或定期执行。
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(3);
// 6. 创建一个指定大小(不传入参数,为当前机器CPU核心数)的线程池,并行地处理任务,不保证处理顺序
Executors.newWorkStealingPool();6.2.2 工厂模式
解决构造方法创建对象的不足
举个栗子:
class Student {
private int id;
private int age;
private String name;// 通过id和name属性来构造一个学生对象
public Student (int id , String name) {
this.id = id;
this.name = name;
}
// 通过age 和 name 属性来构造一个学生对象
public Student (int age , String name) {
this.age = age;
this.name = name;
}由于重载过程参数列表相同而报错!
// 通过id和name属性来构造一个学生对象
public static Student createByIdAndName (int id, String name) {
Student student = new Student();
student.setId(id);
student.setName(name);
return student;
}
// 通过age 和 name 属性来构造一个学生对象
public static Student createByAgeAndName (int age, String name) {
Student student = new Student();
student.setAge(age);
student.setName(name);
return student;
}工厂模式就是:传来什么样的数据,按照工厂方法里的逻辑返回什么对象
6.3 自定义一个线程池
1.可以考虑提交任务到线程池,那么就会有一种数据结构来保存我们提交的任务,
可以考虑用阻塞队列来保存任务.
2.创建线程池是需要指定初始化线程数据,这些线程不停的扫描阻塞队列,如果有任务就立即执行
可以考虑使用线程池对象的构造方法,接受要创建线程的数据,并在构造方法中完成线程的创建
public class Demo03_ThreadPool_Use {
public static void main(String[] args) throws InterruptedException {
// 创建一个线程池
ExecutorService threadPool = Executors.newFixedThreadPool(3);
// 提交任务到线程池
for (int i = 0; i < 10; i++) {
int taskId = i;
threadPool.submit(() -> {
System.out.println("我是任务 " + taskId + ", " + Thread.currentThread().getName());
});
}
// 模拟等待任务
TimeUnit.SECONDS.sleep(5);
System.out.println("第二阶段开始");
// 提交任务到线程池
for (int i = 10; i < 20; i++) {
int taskId = i;
threadPool.submit(() -> {
System.out.println("我是任务 " + taskId + ", " + Thread.currentThread().getName());
});
}
}
}
实现过程:
public class MyThreadPool {
// 1. 定义一个阻塞队列来保存我们的任务
BlockingQueue<Runnable> queue = new LinkedBlockingQueue<>(3);
// 2. 对外提供一个方法,用来往队列中提交任务
public void submit (Runnable task) throws InterruptedException {
queue.put(task);
}
// 3. 构造方法
public MyThreadPool (int capacity) {
if (capacity <= 0) {
throw new RuntimeException("线程数量不能小于0.");
}
// 完成线程的创建,扫描队列,取出任务并执行
for (int i = 0; i < capacity; i++) {
// 创建线程
Thread thread = new Thread(() -> {
while (true) {
try {
// 取出任务(扫描队列的过程)
Runnable take = queue.take();
// 执行任务
take.run();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
// 启动线程
thread.start();
}
}
}
6.3.1 为什么不推荐使用系统自带的线程池?
通过工厂方法获取的线程池,最终都是ThreadPoolExecutor类的对象。