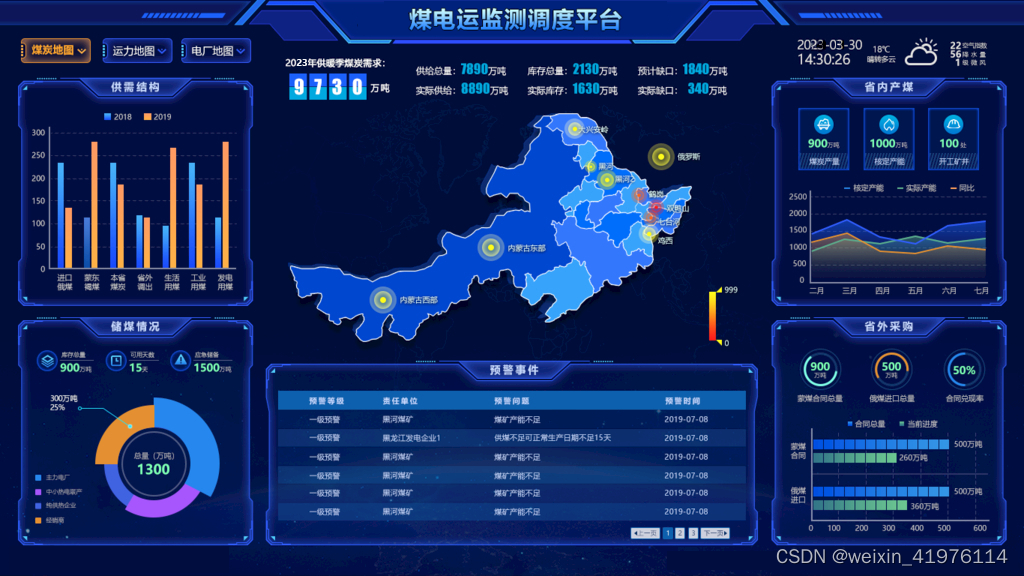
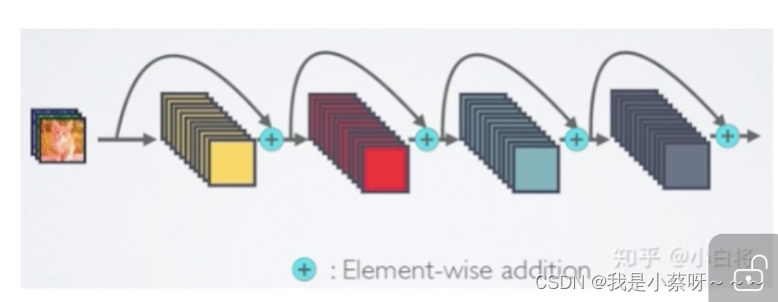
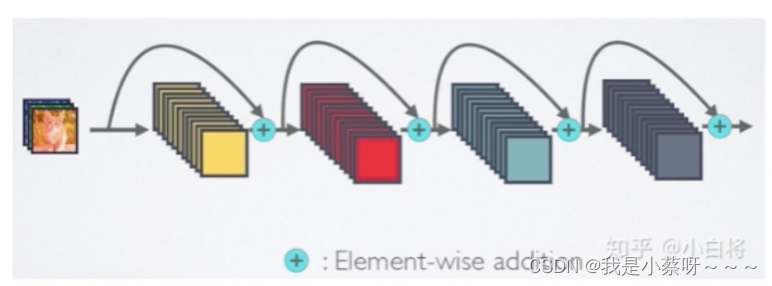
ResNet(深度残差网络)
深度残差网络
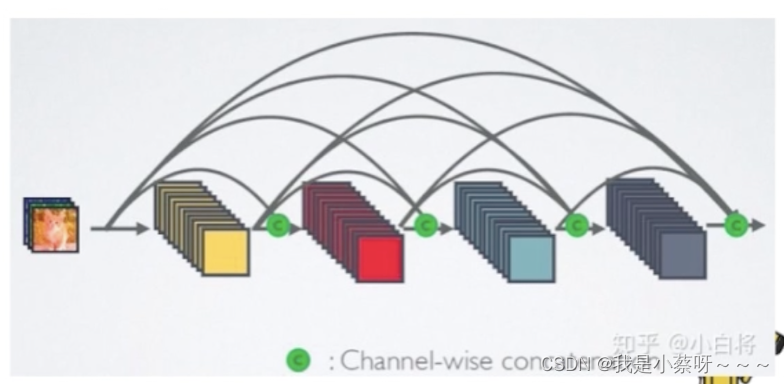
DenseNet
采用密集连接机制,即互相连接所有的层,每个层都会与前面所有层在channel维度上连接在一起,实现特征重用,作为下一层的输入。
这样不但缓解了梯度消失的现象,也使其可以在参数与计算量更少的情况下实现比ResNet更优的性能。
公式表示
H l ( ⋅ ) H_l(·) Hl(⋅)代表是非线性转化函数,是一个组合操作。其可能包括一系列的BN,ReLU,Pooling及Conv操作
传统的网络在l层的输出为:
x
l
=
H
l
(
x
l
−
1
)
x_l=H_l(x_{l-1})
xl=Hl(xl−1)

对于ResNet,增加了来自上一层输入:
x
l
=
H
l
(
x
l
−
1
)
+
x
l
−
1
x_l=H_l(x_{l-1})+x_{l-1}
xl=Hl(xl−1)+xl−1
在DenseNet中,会连接前面所有层作为输入:
x
l
=
H
l
(
[
x
0
,
x
1
,
.
.
.
,
x
l
−
1
]
)
x_l=H_l([x_{0},x_{1},... ,x_{l-1}])
xl=Hl([x0,x1,...,xl−1])
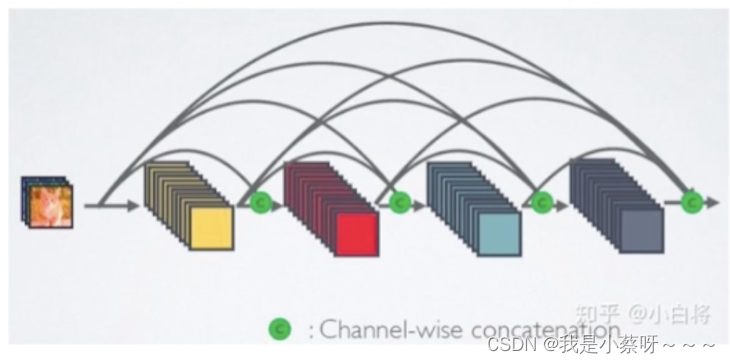
特征传递分方式是,直接将前面所有层的特征concat后传到下一层,而不是前面层都要有一个箭头指向后面所有层。
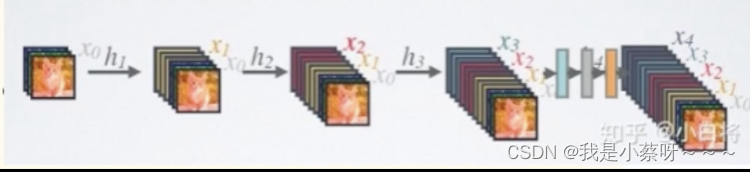
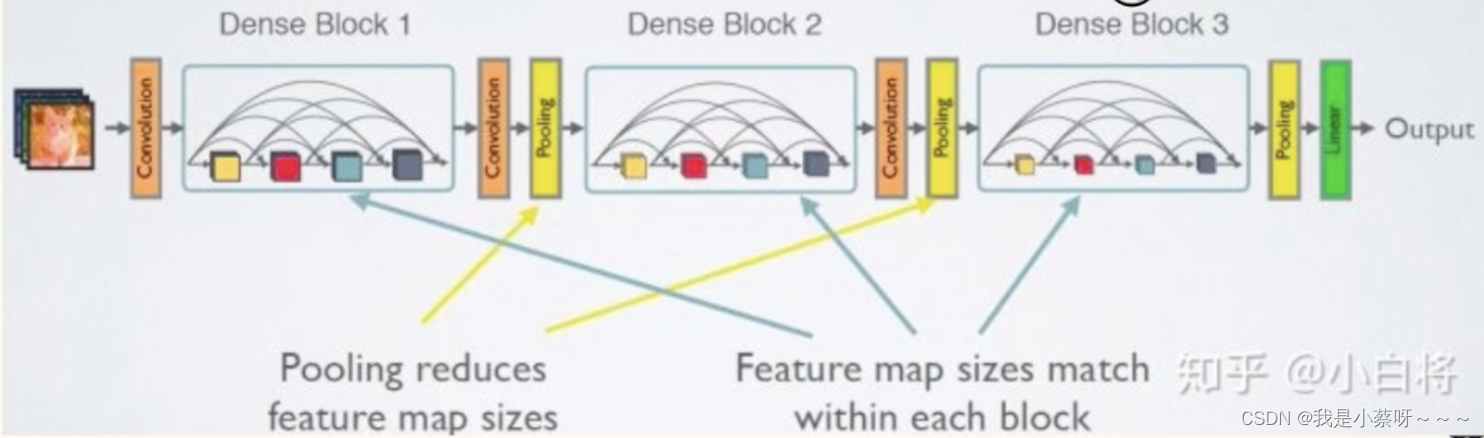
DenseNet网络结构
其密集连接方式需要特征图大小保持一致。所以Den seNet网络中使用DenseBlock+Transition的结构。
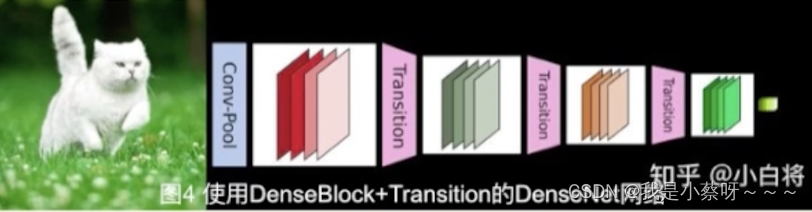
DenseBlock是包含很多层的模块,每个层的特征图大小相同,层与层之间采用密集连接方式。
Transition模块是连接两个相邻的DenseBlock,通过Pooling使特征图大小降低。
假定输入层的特征图channel数为
k
0
k_0
k0,DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,那么l层输入的channel数为
k
0
+
(
l
−
1
)
k
k_0+(l-1)k
k0+(l−1)k,我们将k称之为网络的增长率(Growth Rate),一般取k=12。
DenseBlock,采用了激活函数在前、卷积层在后的顺序,即BN-ReLU-Conv的顺序,这种方式也称为pre-activation。通常模型采用Conv-BN-ReLU,也被称为post-activation。作者证明,如果采用后者,性能会变差。
bottleneck层
由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1*1 Conv,即
BN+ReLU+1✖️1 Conv+ BN+ReLU+3✖️3 Conv
称为DenseNet-B结构。其中1✖️1 Conv得到4k个(特征数量的4倍)特征图,作用是降低特征数量,从而提升计算效率。
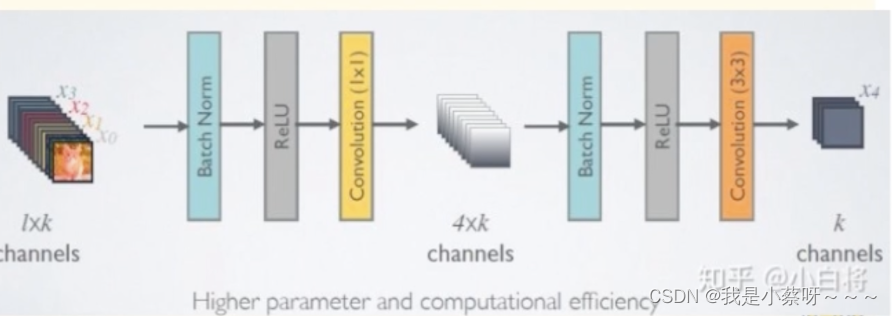
每一个Bottleneck输出的特征通道数是相同的。
1✖️1 Conv的作用是固定输出通道数,达到降维的作用,其输出的通道数通常是GrowthRate的4倍。
Transition层
主要是连接两个相邻的DenseBlock,并且降低特征图大小,其结构为:
BN+ReLU+1✖️1 Conv+2✖️2 AvgPooling
起到压缩模型的作用。假设transition的上接denseblock得到的特征图channels数为m,transition层可以产生[µm]个特征(通过卷积层),其中µ=[0,1]为压缩系数。µ=1时,特征个数经过transition层没有变化,即无压缩;µ<1时,这种结构称为DenseNet-C,一般使用µ=0.5。
对于使用bottleneck层的denseblock结构和压缩系数小于1的transition组合结构称为DenseNet-BC
DenseNet的优势
1、更强的梯度流动、减轻了梯度消失;
2、减少了参数数量;
3、保存了低纬度的特征。在标准的卷积网络中,最终输出只会利用提取最高层次的特征,而在DenseNet中,使用了不同层次的特征,倾向于给出更平滑的决策边界。这也解释了为什么训练数据不足时DenseNet表现依旧良好。
DenseNet的不足
需要进行多次concat操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术。另外,DenseNet是一种更为特殊的网络,ResNet则相对一般化一些,因此ResNet的应用范围更广泛。