加密算法
加密保证数据不会被窃取或者修改
不可逆加密算法
哈希算法
压缩映射:散列又称为哈希,是把任意长度的输入通过散列算法变换成固定长度的输出,该输出就是散列值。
哈希算法(Hash)又称摘要算法(Digest),哈希算法的目的就是为了验证原始数据是否被篡改。
主流的散列算法有MD5和SHA-1,其主要任务是验证数据的完整性

散列算法特色算法
- 固定大小:散列函数能够接收任意大小数据,并输出固定大小散列值,MD5获得的散列值大小是128bit,SHA-1获得的散列值大小是160bit
- 雪崩效应:原始数据只要修改,计算获得的散列值将会发生巨大变化
- 单向:只可能从原始数据计算获得散列值,不可能从散列值恢复数据
- 冲突避免:几乎不能找到另一个数据和当前数据计算的散列值相同,所以散列函数能确保数据的惟一性
一个字节是8位:
二进制8位:xxxxxxxx ,范围:00000000-11111111,表示0到255。
一位16进制数(0-F),用二进制表示是xxxx,范围:0000 - 1111,表示:0到161个字节=2个16进制字符
MD5算法
Java 中,java.security.MessageDigest 中已经定义了 MD5 的计算,我们只需要简单地调用即可得到 MD5 的128 位整数,然后将此 128 位计 16 个字节转换成 16 进制表示即可。
public class Net {
public static char hexDigits[]={'0','1','2','3','4','5','6','7','8','9',
'A','B','C','D','E','F','G',
'H','I','J','K','L','M','N',
'O','P','Q','R','S','T',
'U','V','W','X','Y','Z'};
public static void main(String[] args) throws Exception {
// 创建一个MessageDigest实例
MessageDigest md = MessageDigest.getInstance("MD5");
// 反复调用update输入数据
md.update("心有猛虎,细嗅蔷薇".getBytes("UTF-8"));
//MD5 的计算结果是一个128位的长整数
byte[] result = md.digest();
//16进制字符串形式密文(方式一)----------------------------------------------------------
System.out.println(new BigInteger(1, result).toString(16));
//16进制字符串形式密文(方式二)----------------------------------------------------------
//把密文转换成16进制字符串的形式
int j = result.length;
char str[] = new char[j * 2];
int k = 0;
for (int i = 0; i < j; i++) {
byte byte0 = result[i];
str[k++] = hexDigits[byte0 >>> 4 & 0xf];
str[k++] = hexDigits[byte0 & 0xf];
}
System.out.println(str);
//16进制字符串形式密文(方式三)----------------------------------------------------------
//这时需要一个StringBuffer来存储转译后的加密字符
StringBuffer sb = new StringBuffer();
//加密通常使用十六进制字符加密
char[] chars = { '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a',
'b', 'c', 'd', 'e', 'f', };
//转换为16进制字符串
for(byte b:result){
sb.append(chars[(b >> 4) & 15]);
sb.append(chars[b & 15]);
}
System.out.println(sb.toString());
}
}运行结果
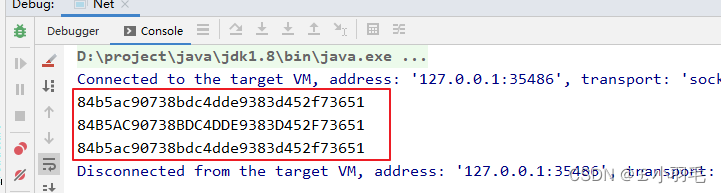 彩虹表:一个预先计算好的常用口令和它们的MD5的对照表
彩虹表:一个预先计算好的常用口令和它们的MD5的对照表
采取措施来抵御彩虹表攻击,方法是对每个口令额外添加随机数,这个方法称之为加盐(salt):
加盐的目的在于使黑客的彩虹表失效,即使用户使用常用口令,也无法从MD5反推原始口令
加盐Salt加密
在原始密码密文的基础之上,再加入一个随机字符串,从而达到让用户的密码更复杂的效果。这个随机字符串,便是盐。
//3、密码加密 //生成盐 String salt = UUID.randomUUID().toString().substring(0,8); //MD5加密相同的字符串加密后的结果一样 ,所以md5会结合加盐保证安全 String endcodePwd = DigestUtils.md5Hex(DigestUtils.md5Hex(password)+salt); userEntity.setSalt(salt); userEntity.setPassword(endcodePwd); //初始化用户的默认值 byte[] encode = Base64.getEncoder().encode(("谷粉" + UUID.randomUUID().toString().substring(0, 8)).getBytes()); userEntity.setNickname(new String(encode)); userEntity.setCreateTime(new Date()); userEntity.setIntegration(0); userEntity.setGrowth(0); userEntity.setLevelId(1L); userEntity.setStatus(1); //4、保存到数据库 this.save(userEntity);注意:salt我们也存储了

SHA-1算法
SHA算法实际上是一个系列,包括SHA-0(已废弃)、SHA-1、SHA-256、SHA-512等。在Java中使用SHA-1,和MD5完全一样,只需要把算法名称改为"SHA-1"
单向散列函数的安全性在于其产生散列值的操作过程具有较强的单向性。如果在输入序列中嵌入密码,那么任何人在不知道密码的情况下都不能产生正确的散列值,从而保证了其安全性
数字签名
通过散列算法可实现数字签名实现,数字签名的原理是将要传送的明文通过一种函数运算(Hash)转换成报文摘要(不同的明文对应不同的报文摘要),报文摘要加密后与明文一起传送给接受方,接受方将接受的明文产生新的报文摘要与发送方的发来报文摘要解密比较,比较结果一致表示明文未被改动,如果不一致表示明文已被篡改。
public class Net {
public static char hexDigits[] = {'0', '1', '2', '3', '4', '5', '6', '7', '8', '9',
'a', 'b', 'c', 'd', 'e', 'f'};
public static void main(String[] args) throws Exception {
// 创建一个MessageDigest实例
MessageDigest md = MessageDigest.getInstance("SHA1");
// 反复调用update输入数据
md.update("helloworld".getBytes("UTF-8"));
//MD5 的计算结果是一个128位的长整数
byte[] result = md.digest();
//16进制字符串形式密文(方式一)----------------------------------------------------------
//把密文转换成16进制字符串的形式
int j = result.length;
char str[] = new char[j * 2];
int k = 0;
for (int i = 0; i < j; i++) {
byte byte0 = result[i];
str[k++] = hexDigits[byte0 >>> 4 & 0xf];
str[k++] = hexDigits[byte0 & 0xf];
}
System.out.println(str);
//16进制字符串形式密文(方式二)----------------------------------------------------------
StringBuilder ret = new StringBuilder(result.length * 2);
for (int i = 0; i < result.length; i++) {
ret.append(hexDigits[(result[i] >> 4) & 0x0f]);
ret.append(hexDigits[result[i] & 0x0f]);
}
System.out.println(ret.toString());
//16进制字符串形式密文(方式三)----------------------------------------------------------
int i;
StringBuffer buf = new StringBuffer("");
for (int offset = 0; offset < result.length; offset++) {
i = result[offset];
if (i < 0)
i += 256;
if (i < 16)
buf.append("0");
buf.append(Integer.toHexString(i));
}
System.out.println(buf.toString());
}
}运行结果

可逆加密算法
AES对称可逆加密
AES支持三种长度的密钥:128位,192位,256位。AES128,AES192,AES256,实际上就是指的AES算法对不同长度密钥的使用。
密钥 是AES算法实现加密和解密的根本。对称加密算法之所以对称,是因为这类算法对明文的加密和解密需要使用同一个密钥。
三种填充模式
AES算法在对明文加密的时候,并不是把整个明文一股脑加密成一整段密文,而是把明文拆分成一个个独立的明文块,每一个明文块长度128bit。
NoPadding:不做任何填充,但是要求明文必须是16字节的整数倍。
PKCS5Padding(默认):如果明文块少于16个字节(128bit),在明文块末尾补足相应数量的字符,且每个字节的值等于缺少的字符数。
ISO10126Padding:如果明文块少于16个字节(128bit),在明文块末尾补足相应数量的字节,最后一个字符值等于缺少的字符数,其他字符填充随机数。
总之,AES是用来替代DES的新一代加密标准,具有128bit的分组长度,支持128、192和256比特的密钥长度
在AES中生成密钥的方法有两种:
从随机数生成
KeyGenerator类,定义一种用于生成大小为n(128、192和256)位的AES密钥的方法:
/** * 用于生成大小为n(128、192和256)位的AES密钥 * @param n * @return * @throws NoSuchAlgorithmException */ public static SecretKey generateKey(int n) throws NoSuchAlgorithmException { KeyGenerator keyGenerator = KeyGenerator.getInstance("AES"); keyGenerator.init(n); SecretKey key = keyGenerator.generateKey(); return key; }
从给定密码生成
基于密码的密钥派生功能从给定的密码派生AES秘密密钥
DES对称可逆加密
DES加密运算、解密运算使用的是同样的密钥,信息的发送者和信息的接收者必须共同持有该密钥。
明文按64位进行分组,密钥长64位(56 位的密钥以及附加的 8 位奇偶校验位)。
第一步:密钥的构建
/** * 密钥生成器 * * @return * @throws Exception */ public static byte[] initKey() throws Exception { KeyGenerator keyGenerator = KeyGenerator.getInstance("DES"); //初始化密钥生成器 keyGenerator.init(56); //生成密钥 SecretKey secretKey = keyGenerator.generateKey(); //获得密钥得二进制编码形式 return secretKey.getEncoded(); }返回的二进制字节数组就是我们需要的秘密密钥,方便存储在文件或者以流的方式在网路传输。
-------------------------------
第二步,把二进制密钥转为SecretKey密钥对象
/** * 转换密钥 * * @param key * @return * @throws Exception */ private static Key generateKey(byte[] key) throws Exception { //实例化DES密钥材料 DESKeySpec dks = new DESKeySpec(key); //创建一个密匙工厂 SecretKeyFactory keyFactory = SecretKeyFactory.getInstance("DES"); //生成秘密密钥,并返回 return keyFactory.generateSecret(dks); }
有了密钥就可以对数据加密和解密了
Cipher.getInstance("DES");可以设置为Cipher.getInstance("DES/CBC/PKCS5Padding");
分别指 "算法/工作模式/填充模式"
使用DES加密数据
/** * DES加密 * * @param data 待加密数据 * @param key 密钥 * @return 加密后数据 */ public static byte[] encrypt(byte[] data, byte[] key) throws Exception { //还原密钥 Key secretKey = generateKey(key); //指定获取DES的Cipher对象 Cipher cipher = Cipher.getInstance("DES"); //初始化,设置加密模式 cipher.init(Cipher.ENCRYPT_MODE,secretKey); //执行操作 byte[] bytes = cipher.doFinal(data); return bytes; }------------------------------------------------------
使用DES解密数据
/** * DES解密 * * @param data 待解密数据 * @param key 密钥 * @return 解密后内容 */ public static byte[] decrypt(byte[] data, byte[] key) throws Exception { //还原密钥 Key secretKey = generateKey(key); //实例化 Cipher cipher = Cipher.getInstance("DES"); //设置为解密模式 cipher.init(Cipher.DECRYPT_MODE, secretKey); //执行操作 byte[] bytes = cipher.doFinal(data); return bytes; }
测试
public static void main(String[] args) throws Exception {
String password = "kfcKFC888888";
byte[] key = DESUtil.initKey();//拿到密钥
//对password加密
byte[] encrypt = DESUtil.encrypt(password.getBytes(), key);
System.out.println("加密后数据," +new String (encrypt,"UTF-8"));
//对password解密
byte[] decrypt = DESUtil.decrypt(encrypt, key);
System.out.println("解密后数据," +new String (decrypt,"UTF-8"));
}
RSA非对称可逆加密
RSA算法是一种非对称的加密算法(即:加密、解密的密钥不同) ,通常是生成两把密钥,分别是私钥和公钥,其中私钥保密,公钥对外公开。
RSA加解密过程:使用公钥将数据加密,并通过私钥对加密信息进行解密。针对我们遇到的问题,公钥放在前端对用户名密码进行加密,私钥放在服务端对前端提交的加密数据进行解密,然后在做登陆的业务操作
字符集
ASCII字符集
编码、解码
计算机底层并没有文本文件、图片文件之分,它只是记录着每个文件的二进制序列。
字符集:包含着字符和二进制序列之间的对应关系,一个字符对应一个二进制序列。
乱码:编码、解码使用的字符集不一致导致
Windows中文本文件的默认字符集是GBK。
MySQL在8.0版本之前,默认字符集为latin1,8.0版本默认字符集为utf8mb4
ISO8859-1 字符集,也就是 Latin-1,是西欧常用字符,包括德法两国的字母。 ISO8859-2 字符集,也称为 Latin-2,收集了东欧字符。 ISO8859-3 字符集,也称为 Latin-3,收集了南欧字符。
字符集(Character Set):是指多个字符的集合。不同的字符集包含的字符个数不一样、包含的字符不一样、对字符的编码方式也不一样。如:
ASCII字符集
字符编码是指一种映射规则,根据这个规则来将字符映射到相应的码点(数值)上面
ASCII字符集
ASCII字符集只包含了128字符,这个字符集收录的主要字符是英文字母、阿拉伯字母和一些简单的控制字符
ASCII 编码方式是一种固定长度的编码方式,每个字符都使用 7 位二进制编码来表示。长度为1个字节, 有符号字符型数
ASCII码对照表
ASCII码中,
第0~32号及第127号是控制字符,常用的有LF(换行)、CR(回车);
第33~126号是字符,
其中第48~57号为0~9十个阿拉伯数字;
65~90号为26个大写英文字母,
97~122号为26个小写英文字母,
其余的是一些标点符号、运算符号等
特殊字符解释
ASCII值 控制字符 ASCII值 控制字符 ASCII值 控制字符 ASCII值 控制字符 0 NUT 32 (space) 64 @ 96 、 1 SOH 33 ! 65 A 97 a 2 STX 34 " 66 B 98 b 3 ETX 35 # 67 C 99 c 4 EOT 36 $ 68 D 100 d 5 ENQ 37 % 69 E 101 e 6 ACK 38 & 70 F 102 f 7 BEL 39 , 71 G 103 g 8 BS 40 ( 72 H 104 h 9 HT 41 ) 73 I 105 i 10 LF 42 * 74 J 106 j 11 VT 43 + 75 K 107 k 12 FF 44 , 76 L 108 l 13 CR 45 - 77 M 109 m 14 SO 46 . 78 N 110 n 15 SI 47 / 79 O 111 o 16 DLE 48 0 80 P 112 p 17 DCI 49 1 81 Q 113 q 18 DC2 50 2 82 R 114 r 19 DC3 51 3 83 S 115 s 20 DC4 52 4 84 T 116 t 21 NAK 53 5 85 U 117 u 22 SYN 54 6 86 V 118 v 23 TB 55 7 87 W 119 w 24 CAN 56 8 88 X 120 x 25 EM 57 9 89 Y 121 y 26 SUB 58 : 90 Z 122 z 27 ESC 59 ; 91 [ 123 { 28 FS 60 < 92 / 124 | 29 GS 61 = 93 ] 125 } 30 RS 62 > 94 ^ 126 ` 31 US 63 ? 95 _ 127 DEL
NUL空 VT 垂直制表 SYN 空转同步 STX 正文开始 CR 回车 CAN 作废 ETX 正文结束 SO 移位输出 EM 纸尽 EOY 传输结束 SI 移位输入 SUB 换置 ENQ 询问字符 DLE 空格 ESC 换码 ACK 承认 DC1 设备控制1 FS 文字分隔符 BEL 报警 DC2 设备控制2 GS 组分隔符 BS 退一格 DC3 设备控制3 RS 记录分隔符 HT 横向列表 DC4 设备控制4 US 单元分隔符 LF 换行 NAK 否定 DEL 删除
Unicode字符集
Unicode字符集
Unicode 标准始终使用十六进制数字标识唯一的码点(code point),码点用于表示该字符在字符集中的位置
Unicode字符集
Unicode字符集是一个很大的字符集合,包含了世界上几乎所有的字符,用于表示人类语言、符号和表情等各种信息
UTF-8编码
UTF-8就是在互联网上使用最广的一种Unicode的实现方式。UTF-8编码是Unicode的实现方式之一。只有 UTF-8 兼容 ASCII,UTF-32 和 UTF-16 都不兼容 ASCII,因为它们没有单字节编码
UTF-8最大的一个特点,就是它是一种可变长度的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度
UTF-8 是一种可变长度的编码方式
- 对于 ASCII 字符(码点范围为 0x00~0x7F ),使用一个字节表示
- 对于其他 Unicode 字符,使用两个、三个或四个字节表示
通常⼀个 字节=两个16进制位 过程解析:1个16进制数 = 4个⼆进制数位,2个16进制数 = 8个⼆进制数位 = 1字节一位16进制数(用二进制表示是xxxx)最多只表示到15(即对应16进制的F)

UTF-8 使用 1 个字节表示 ASCII 字符;
UTF-8 使用 2 个字节表示带有附加符号的拉丁文、希腊文等;
UTF-8 使用 3 个字节表示其他基本多文种平面(BMP)中的字符(包含了大部分常用字,如大部分的汉字);
UTF-8 使用 4 个字节表示 Unicode 辅助平面的字符。
UTF-8 编码的规则:
在 ASCII 码范围内的代码点,UTF-8 使用 1 个字节表示。
大于 ASCII 码范围的代码点,UTF-8 使用多个字节表示。UTF-8 使用第一个字节的前几位表示该 Unicode 字符的字节长度(第一个字节的开头 1 的数目就是该 Unicode 字符的字节长度),其余字节的前两位固定为 10,作为标记
如果第一个字节的前两位为 1,第三位为 0(110xxxxx),则表示 UTF-8 使用 2 个字节表示该 Unicode 字符;
如果第一个字节的前三位为 1,第四位为 0(1110xxxx),则表示 UTF-8 使用 3 个字节表示该 Unicode 字符;
依此类推;
如果第一个字节的前四位为 1,第五位为 0(11110xxx),则表示 UTF-8 使用 4 个字节表示该 Unicode 字符;
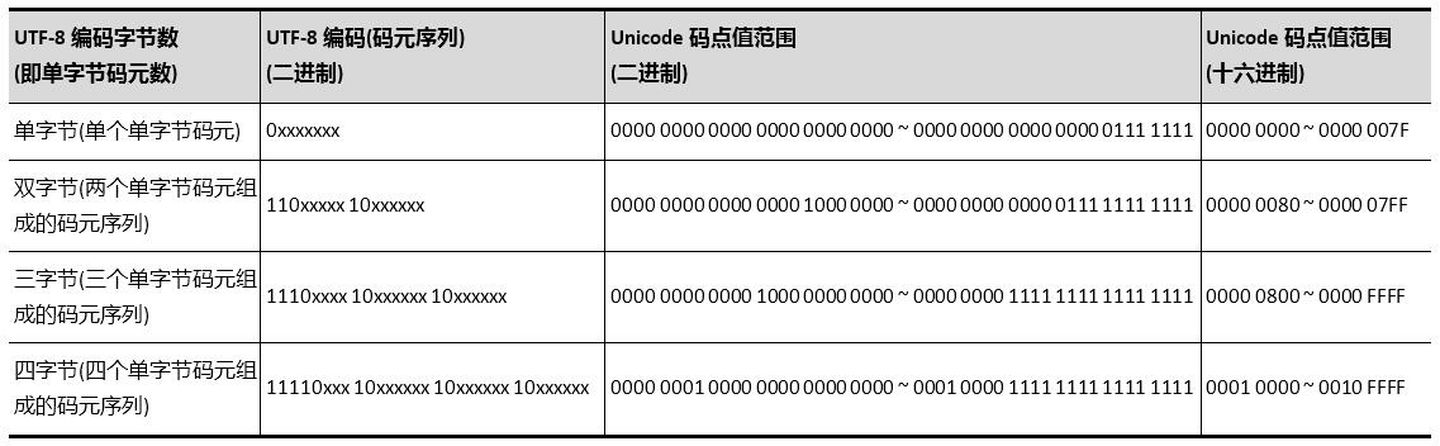
UTF-16编码和UTF-32 编码
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,
GBK相关字符集
GB2312字符集
GB2312 :《信息交换用汉字编码字符集》
GB2312和GBK都是在 ASCII 的基础上发展起来的,它们都兼容 ASCII,
以 GB2312 为例,该字符集收录的字符较少,所以使用 1~2 个字节编码。
- 对于 ASCII 字符,使用一个字节存储,并且该字节的最高位是 0;
- 对于中国的字符,使用两个字节存储,并且规定每个字节的最高位都是 1。
GB2312汉字编码规则
GB2312 把每个汉字都编码成两个字节,第一个字节是高位字节,第二个字节是低位字节
GBK 字符集
GBK:《汉字内码扩展规范》
GBK 包含了 GB2312 字符集中的字符,同时还扩展了许多其他汉字字符和符号,共收录了 21,913 个字符。
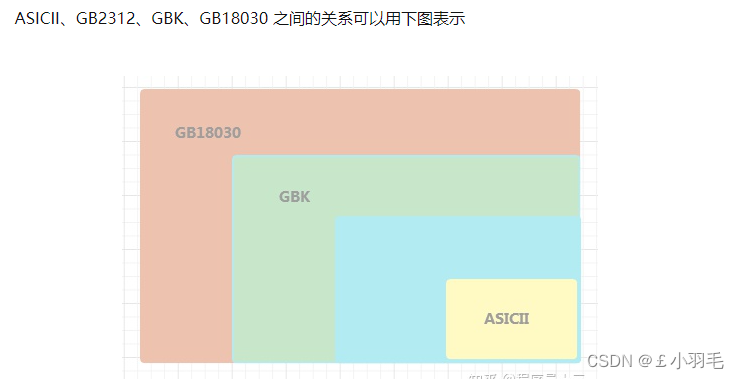
GB18030 字符集
GB18030 全称《信息技术 中文编码字符集》 ,共收录七万多个汉字和字符, 它在 GBK 的基础上增加了中日韩语中的汉字 和 少数名族的文字及字符,完全兼容 GB2312,基本兼容 GBK
编码方式
浏览器百分号编码

URL 只能使用 ASCII 字符集来通过因特网进行发送。由于 URL 常常会包含 ASCII 集合之外的字符,URL 必须转换为有效的 ASCII 格式。
转化格式为:URL 编码使用 "%" 其后跟随两位的十六进制数来替换非 ASCII 字符
浏览器提交数据时默认会使用UrlEcode对内容进行编码,tomcat服务器默认会使用UrlDecode对内容进行解码,来解决中文乱码问题
测试一:
UrlEncode编码,对acsII码表中的大部分内容不会处理
//测试UrlEncode编码: //1、编码:对acs码表中的大部分内容不会处理 String s ="abc123456."; String encode = URLEncoder.encode(s, "UTF-8"); System.out.println("编码后: "+encode); //2、解码 String decode = URLDecoder.decode(encode, "UTF-8"); System.out.println("解码后: "+decode);

测试二:使用UrlEcode解决中文乱码
//测试UrlEncode编码: //1、编码:UTF-8的中文会转为三个%组成的字符串 String s ="http://localhost:8080?keyword=华为手机"; String encode = URLEncoder.encode(s, "UTF-8"); System.out.println("编码后: "+encode); //2、解码 String decode = URLDecoder.decode(encode, "UTF-8"); System.out.println("解码后: "+decode);

Base64编码
jwt: jwt将载荷头 签名 使用Base64的算法处理后得到一个可读的字符串
base64:提供了64个字符
a~z A~Z 0~9 / + = 保留字符 不解析
以后需要base64处理的字符串,每个字符只要可以转为64个字符的某一个就没有乱码
base64将数据转为字节数组,每3个字节重新分为一组,如果一组不足三个使用=补齐
再将三个字节拆分为4个字节,并在高位补充0//1 byte = 8bit [ 1010 0101 ] [ 1110 0101 ] [ 0010 0101 ] 拆分后 [ 00 1010 01 ] [ 00 01 1110 ] [ 00 0101 00 ] [00 10 0101]处理后每个字节最大是00 1111 11 取值范围一共有64种可能,每一个值对应base64提供的码表中的一个字符 a~z A~Z 0~9 / +
String s = "金三银四?";
byte[] encode = Base64.getEncoder().encode(s.getBytes("UTF-8"));
String s1 = new String(encode);
System.out.println("base64编码后:"+s1);
byte[] decode = Base64.getDecoder().decode(s1);
String s2 = new String(decode);
System.out.println("解码后: "+s2);
如果把字符串改为:
String s = "金三银四a";
如果把字符串改为:
String s = "金三银四ab";