facial expression recognition
表情,人脸上的肌肉状态,可以表达人类的情绪。
1970年,Ekman定义了六种基本表情

如何定义?
动作单元(action unit)是定义表情的重要工具。
心理学家和生物学家认为,人的表情可以分解为不同面部肌肉的状态组合。
人脸动作编码系统,是定义AU的最重要系统之一,其中定义了几十个表情动作单元,且每个单元都存在一定的强度级别,从而可以通过组合得到上千种人类表情。
| Action Unit | 描述 |
|---|---|
| 1 | 皱眉毛 |
| 2 | 眼头上扬 |
| 4 | 眼角上扬 |
| 5 | 上眼睑上升 |
| 6 | 下眼睑上升 |
| 7 | 眼睛紧闭 |
| 9 | 鼻翼扩张 |
| 10 | 上唇上扬 |
| 12 | 嘴角上扬 |
| 14 | 嘴巴张开 |
如此,即可得到一些典型表情的编码公式:
- 愤怒:AU4 + AU5 + AU7 + AU23
- 高兴:AU6 + AU12
- 伤心:AU1 + AU4 + AU15
- 惊讶:AU1 + AU2 + AU5 + AU26
- 厌恶:AU9 + AU15 + AU16
- 恐惧:AU1 + AU2 + AU4 + AU5 + AU20
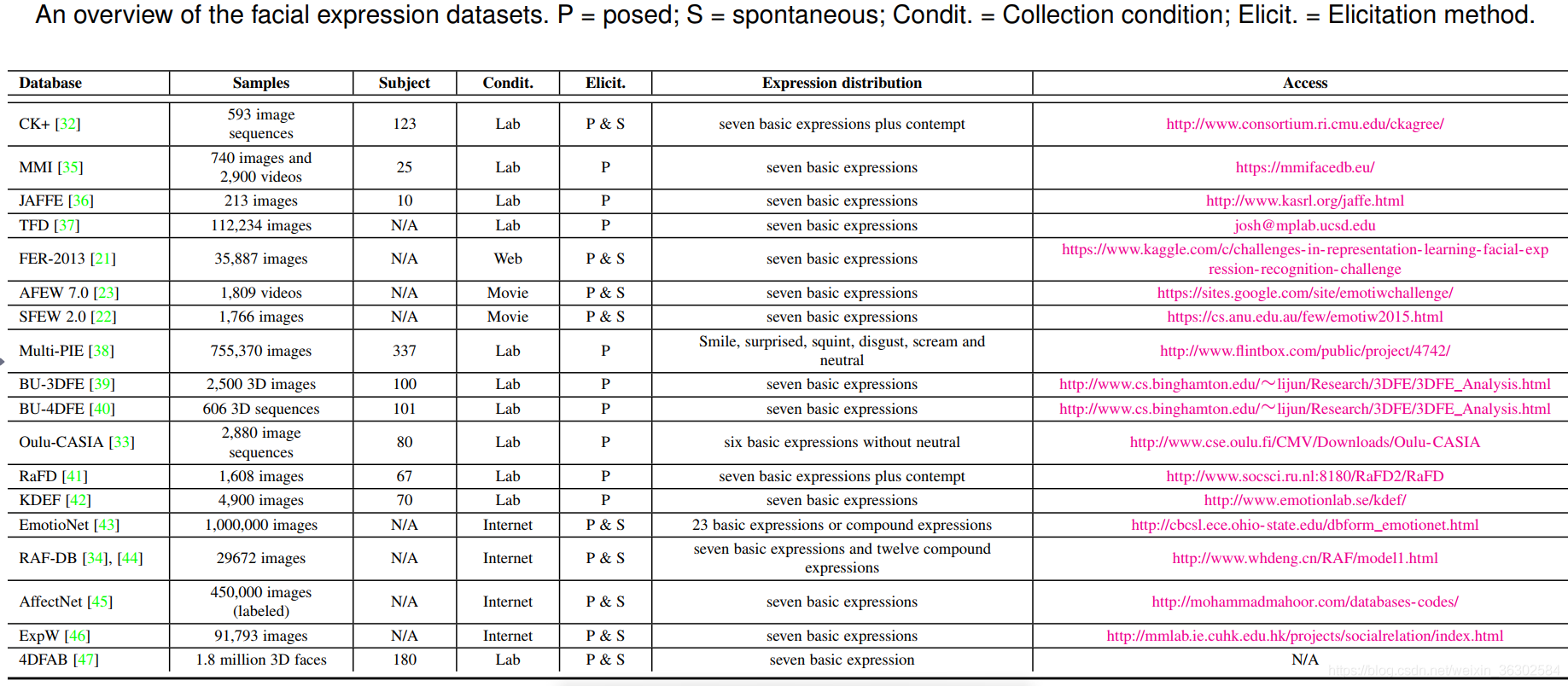
典型数据集
- CK+:包含123个人的327个标注的表情图片序列,共7种表情 (缺点:太小)
- FER2013: 包含35887张图像,共分为7种表情。(缺点:标注噪声太大)
- FER plus: 微软针对FER2013重新标记的数据集
- JAFFE: 213张图片,10个人,每个人3-4张图像(缺点:太小)
同时,还有一些视频相关的数据集。
表情识别研究趋势
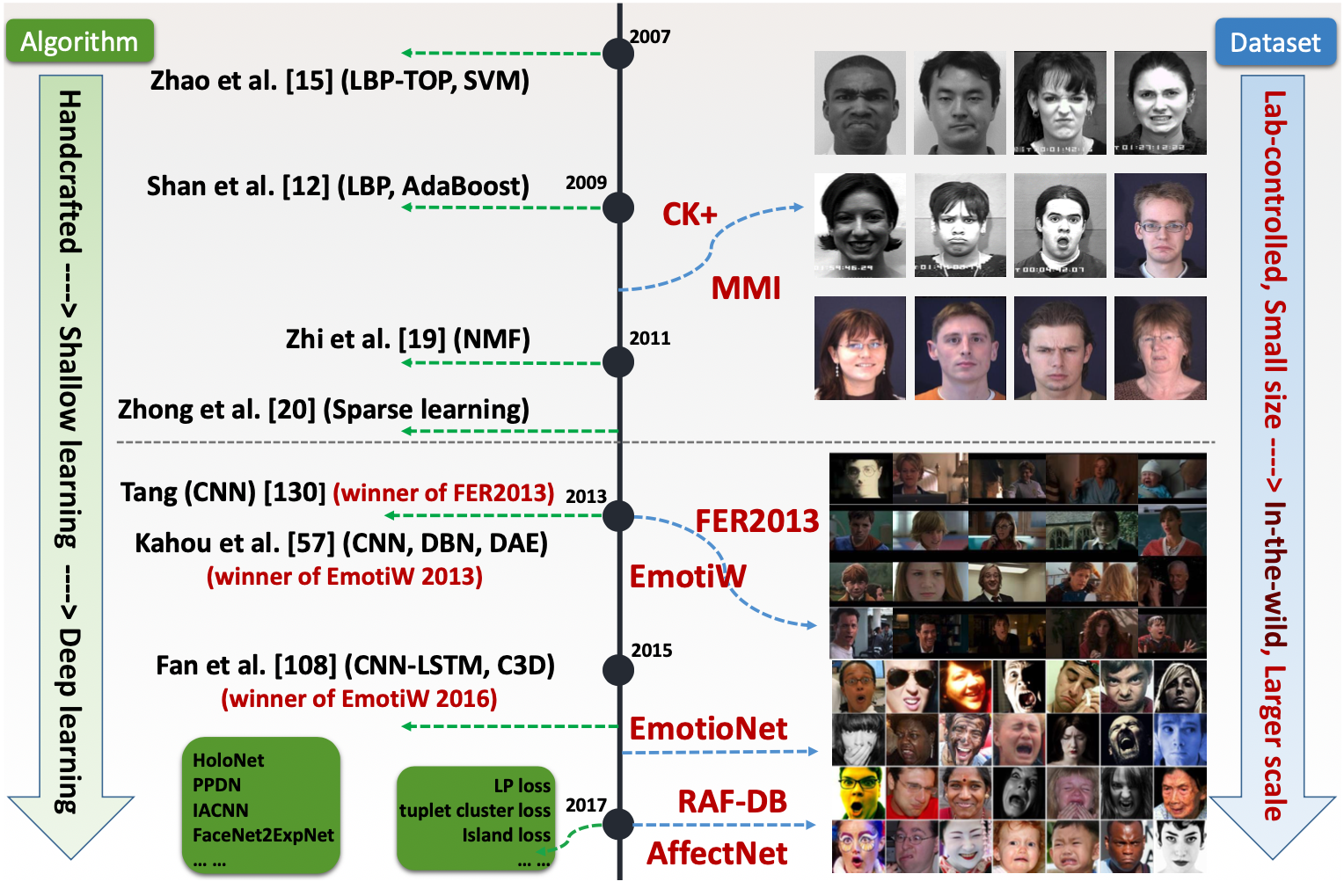
从数据上说,表情识别分为两种类型:
- 静态图像的表情识别(最典型的表情识别)
- 动态视频的表情识别(更丰富的表情类型,微表情)
表情识别问题的基本思路
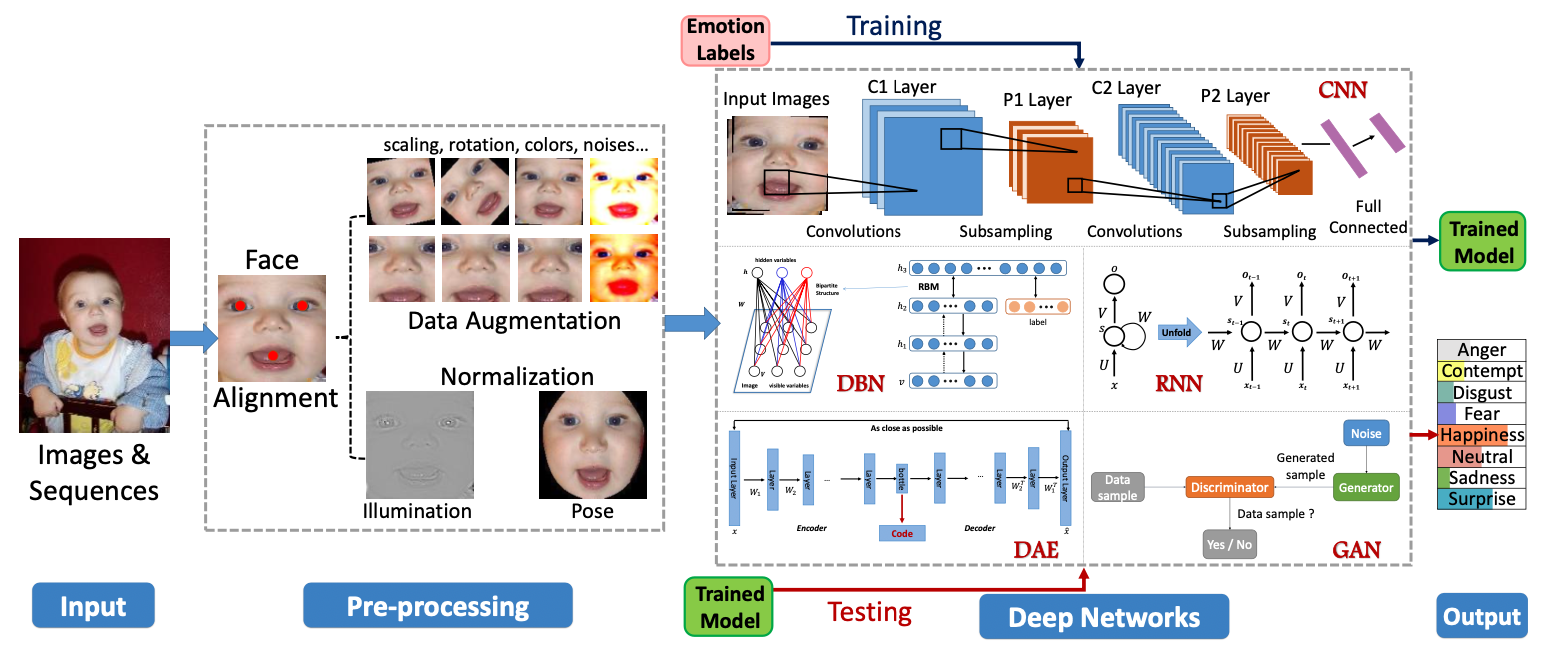
人脸对齐
在检测到人脸后,表情识别首先要做的事情就是:人脸对齐
通常,人脸对齐的方法有很多,但大部分的方法都是基于面部特征点的方法。
如最简单的将五个特征点对齐到目标位置,或者通过deepface通过3d的方法进行建模
图像正则化
图像正则化包含两个方面的内容:
- 亮度正则化
- 姿势正则化
亮度归一化的主要方法包括
- DoG滤波(高斯差金字塔):图像减去均值除以标准差,消除光照影响
- DCT(余弦傅里叶变换)滤波:压缩低频信号的振幅,减弱亮度(光照:低频信号)
- 直方图均衡化
姿势正则化的主要方法包括
- deepface:利用三维人脸矫正信息
- GAN生成不同角度的人脸,或者让GAN帮你生成正脸图像
识别人脸表情
表情识别本质上是一个分类问题。
在分类问题上的思路实际上有如下几个思路
- 端到端的模型
给定一个标签和图像,训练一个cnn模型,得到一个表情分类器。
代表性方法: faceNet2emotionNet
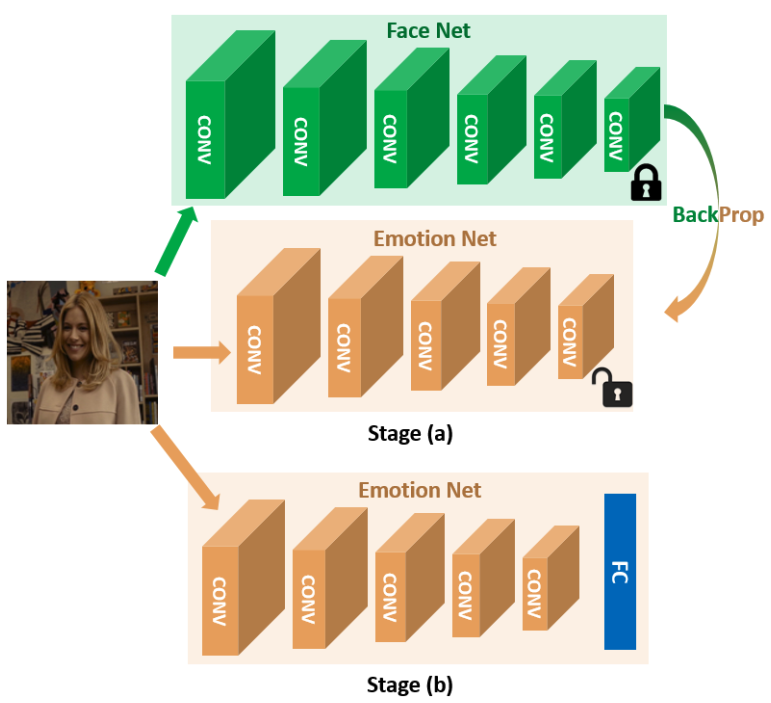
图中,绿色的部分是已经训练完成的人脸识别模型,该模型已经学习到了不同人脸之间的区别。
第一阶段训练时,先冻结绿色部分,监督emotion net进行训练。注意到这里facenet的特征作为emotionnet的标签,令emotionnet的卷积层的输出尽可能与facenet接近。本质上,此部分是为了让facenet的知识迁移到新的网络中(教师学生网络)。
第二阶段,在emotion net的网络基础之上,加入分类器,用表情标签指导训练。最终得到emotion net的模型。
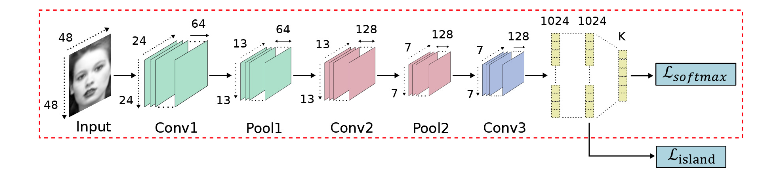
代表性方法2:island loss

代表性方法3: N+M元组损失
三元组损失的一个弱点认为,anchor的正负例选择至关重要,选不好了可能会对模型性能没有促进。
干脆选n个正例,m个负例,从而获得更好的效果。

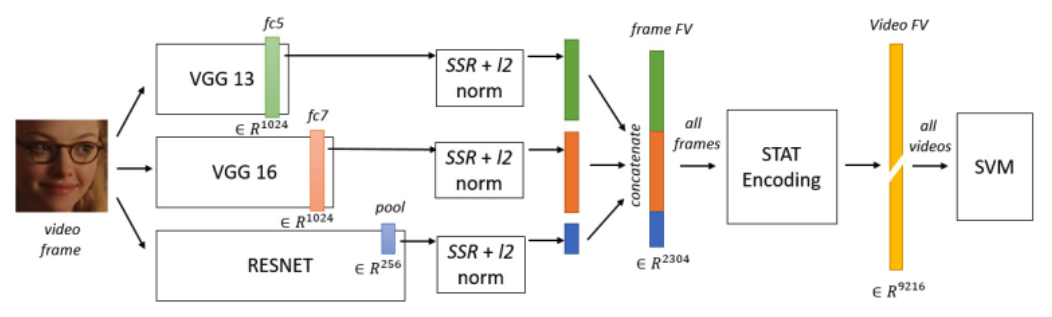
代表性方法4: backbone集成
把三种不同网络的不同层拿出来,进行融合后送到分类器中。

除了上述端到端的模型之外,还有一种思路是考虑对AU进行预测,从而获取表情编码。
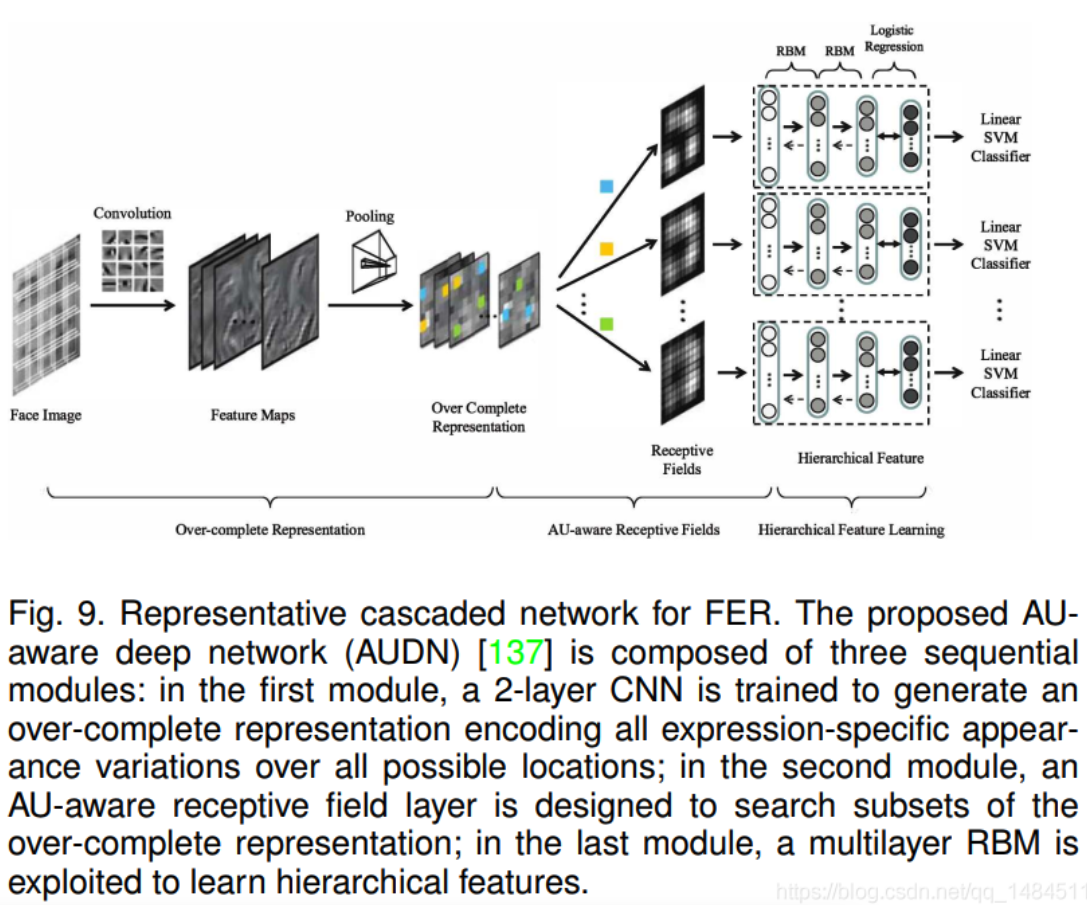
代表性方法:AUDN