Hystrix详解及实践
- 1.Hystrix简介
- 2.雪崩问题
- 3.服务降级、线程隔离、原理
- 3.1.服务降级实践(在feign的基础上实现)
- 1 添加Hystrix依赖
- 2.在yml中开启熔断功能
- 3.编写降级逻辑
- 4.重启测试
- 4.服务熔断(Circuit Breaker)、原理
- 4.1. 熔断原理
- 4.2.动手实践
- 5.Hystrix核心源码剖析
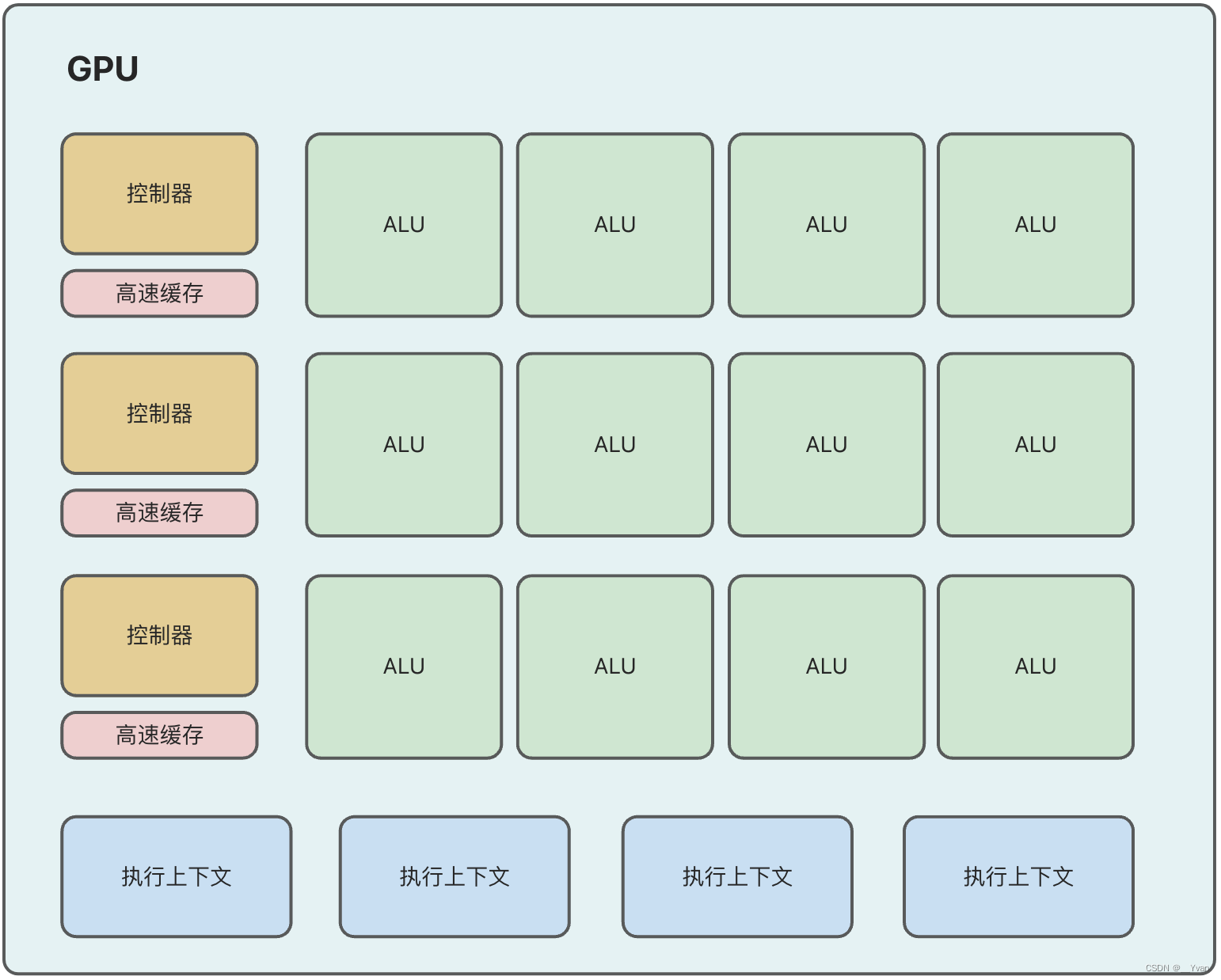
1.Hystrix简介
Hystix,英文意思是豪猪,全身是刺,看起来就不好惹,是一种保护机制。
Hystrix也是Netflix公司的一款组件。
主页:https://github.com/Netflix/Hystrix/

Hystrix 是一种开关装置,类似于熔断保险丝。在消费者端安装一个 Hystrix 熔断器,当
Hystrix 监控到某个服务发生故障后熔断器会开启,将此服务访问链路断开。不过 Hystrix 并不会将该服务的消费者阻塞,或向消费者抛出异常,而是向消费者返回一个符合预期的备选响应(FallBack)。通过 Hystrix 的熔断与降级功能,避免了服务雪崩的发生,同时也考虑到了用户体验。故 Hystrix 是系统的一种防御机制。
2.雪崩问题
如果说,我们需要访问的某个服务,Dependency-I发生了故障,此时,我们应用中,调用Dependency-I的服务,也会故障,造成阻塞。此时,其它业务似乎不受影响。

例如微服务I发生异常,请求阻塞,用户不会得到响应,则tomcat的这个线程不会释放,于是越来越多的用户请求到来,越来越多的线程会阻塞:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vZ7TdMdY-1615796261981)(assets/1604375397407.png)]](https://img-blog.csdnimg.cn/20210315164753787.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MzgxMTA1Nw==,size_16,color_FFFFFF,t_70)
服务器支持的线程和并发数有限,请求一直阻塞,会导致服务器资源耗尽,从而导致所有其它服务都不可用,形成雪崩效应。
这就好比,一个汽车生产线,生产不同的汽车,需要使用不同的零件,如果某个零件因为种种原因无法使用,那么就会造成整台车无法装配,陷入等待零件的状态,直到零件到位,才能继续组装。 此时如果有很多个车型都需要这个零件,那么整个工厂都将陷入等待的状态,导致所有生产都陷入瘫痪。一个零件的波及范围不断扩大。
3.服务降级、线程隔离、原理

Hystrix为每个服务调用的功能分配一个小的线程池,如果线程池已满调用将被立即拒绝,默认不采用排队.加速失败判定时间。
用户的请求将不再直接访问服务,而是通过线程池中的空闲线程来访问服务,如果线程池已满,或者请求超时,则会进行降级处理:返回给用户一个错误提示或备选结果。
服务降级虽然会导致请求失败,但是不会导致阻塞,而且最多占用该服务的线程资源,不会导致整个容器资源耗尽,把故障的影响隔离在线程池内
3.1.服务降级实践(在feign的基础上实现)
步骤:
1.添加Hystrix依赖
2.在yml中开启熔断功能
3.编写降级逻辑
1 添加Hystrix依赖
由于Feign默认也有对Hystix的集成,所以不需要单独再添加依赖
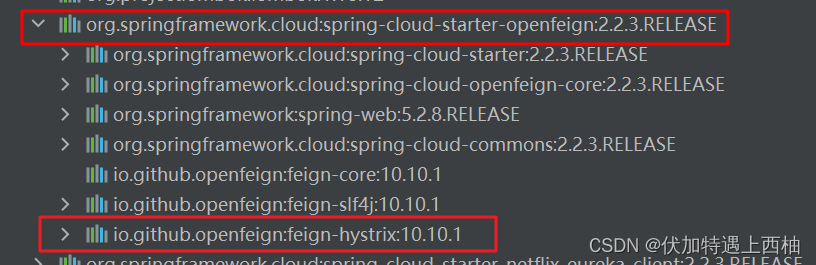
2.在yml中开启熔断功能
在feign-hystrix-consumer-8080服务中开启熔断配置
feign:
hystrix:
enabled: true # 开启Feign的熔断功能
3.编写降级逻辑
-
在feign-provider-api新增DepartServiceFallback类实现feign接口,在每个方法中编写具体的降级方法。
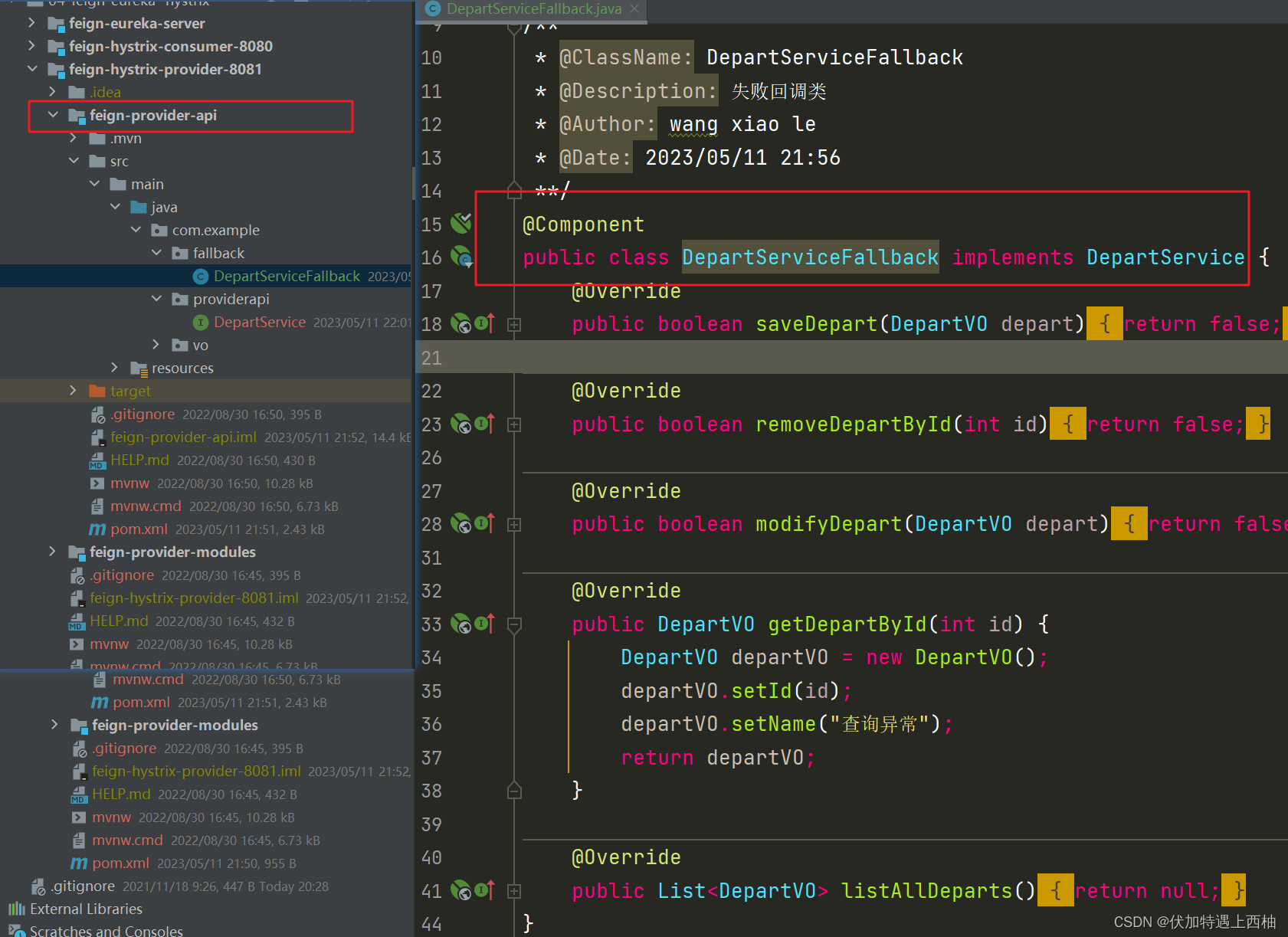
/**
1. @ClassName: DepartServiceFallback
2. @Description: 失败回调类
3. @Author: wang xiao le
4. @Date: 2023/05/11 21:56
**/
@Component
public class DepartServiceFallback implements DepartService {
@Override
public boolean saveDepart(DepartVO depart) {
return false;
}
@Override
public boolean removeDepartById(int id) {
return false;
}
@Override
public boolean modifyDepart(DepartVO depart) {
return false;
}
@Override
public DepartVO getDepartById(int id) {
DepartVO departVO = new DepartVO();
departVO.setId(id);
departVO.setName("查询异常");
return departVO;
}
@Override
public List<DepartVO> listAllDeparts() {
return null;
}
}
-
在DepartService 指定刚才编写的实现类
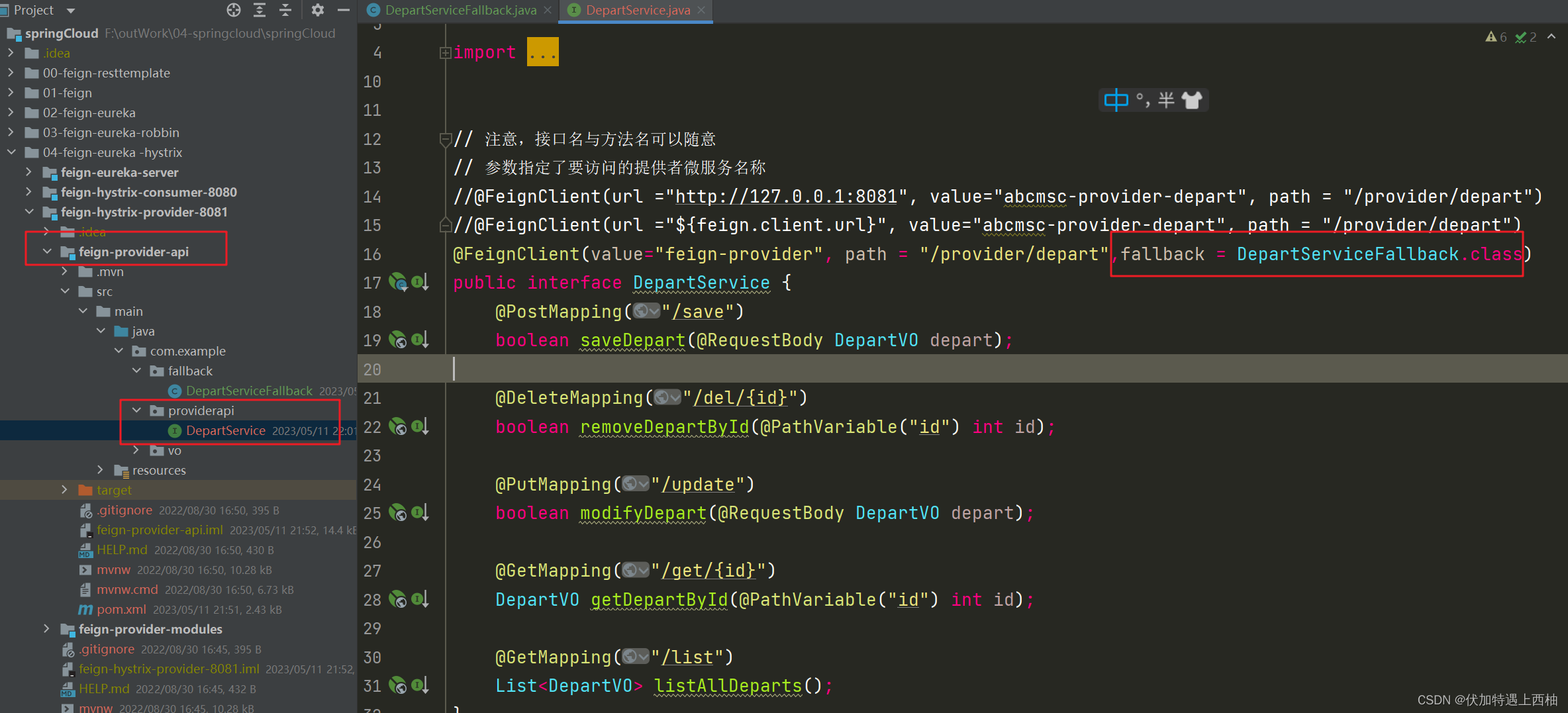
// 注意,接口名与方法名可以随意
// 参数指定了要访问的提供者微服务名称
//@FeignClient(url ="http://127.0.0.1:8081", value="abcmsc-provider-depart", path = "/provider/depart")
//@FeignClient(url ="${feign.client.url}", value="abcmsc-provider-depart", path = "/provider/depart")
@FeignClient(value="feign-provider", path = "/provider/depart",fallback = DepartServiceFallback.class)
public interface DepartService {
@PostMapping("/save")
boolean saveDepart(@RequestBody DepartVO depart);
@DeleteMapping("/del/{id}")
boolean removeDepartById(@PathVariable("id") int id);
@PutMapping("/update")
boolean modifyDepart(@RequestBody DepartVO depart);
@GetMapping("/get/{id}")
DepartVO getDepartById(@PathVariable("id") int id);
@GetMapping("/list")
List<DepartVO> listAllDeparts();
}
4.重启测试
我们只重启consumer,不启动provider服务,模拟provider服务宕机
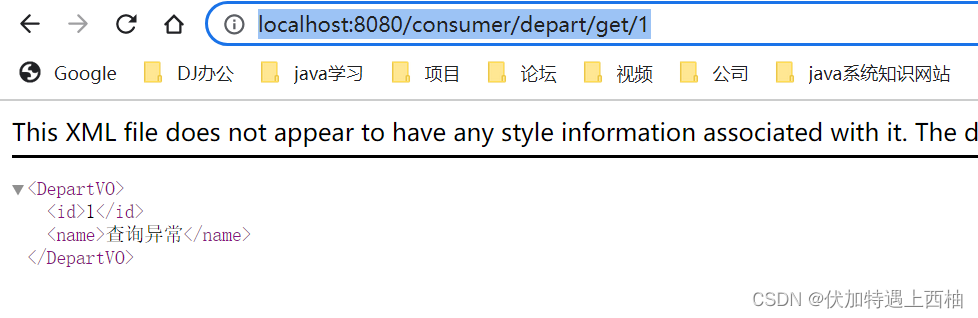
访问http://localhost:8080/consumer/depart/get/1
显示为失败回调的结果
4.服务熔断(Circuit Breaker)、原理
4.1. 熔断原理
尽管隔离可以避免服务出现级联失败,但是对于访问服务I(故障服务 的其它服务,每次处理请求都要等待 数秒直至fallback,显然是对系统资源的浪费。
因此,当Hystix判断一个依赖服务失败比例较高时,就会对其做熔断处理: 拦截对故障服务的请求,快速失 败,不再阻塞等待,就像电路的断路器断开了,保护电路。
熔断器,也叫断路器,其英文单词为:Circuit Breaker 
Hystix的熔断状态机模型:

状态机有3个状态:
- Closed:关闭状态(断路器关闭),所有请求都正常访问。
- Open:打开状态(断路器打开),所有请求都会被降级。Hystix会对请求情况计数,当一定时间内失败请求百分比达到阈值,则触发熔断,断路器打开。默认失败比例的阈值是50%,请求次数最少不低于20次。
- Half Open:半开状态,open状态不是永久的,打开后会进入休眠时间(默认是5S)。随后断路器会自动进入半开状态。此时会释放1次请求通过,若这个请求是健康的,则会关闭断路器,否则继续保持打开,再次进行5秒休眠计时。
4.2.动手实践
为了能够精确控制请求的成功或失败,在feign-provider-modules的调用业务中加入一段逻辑:
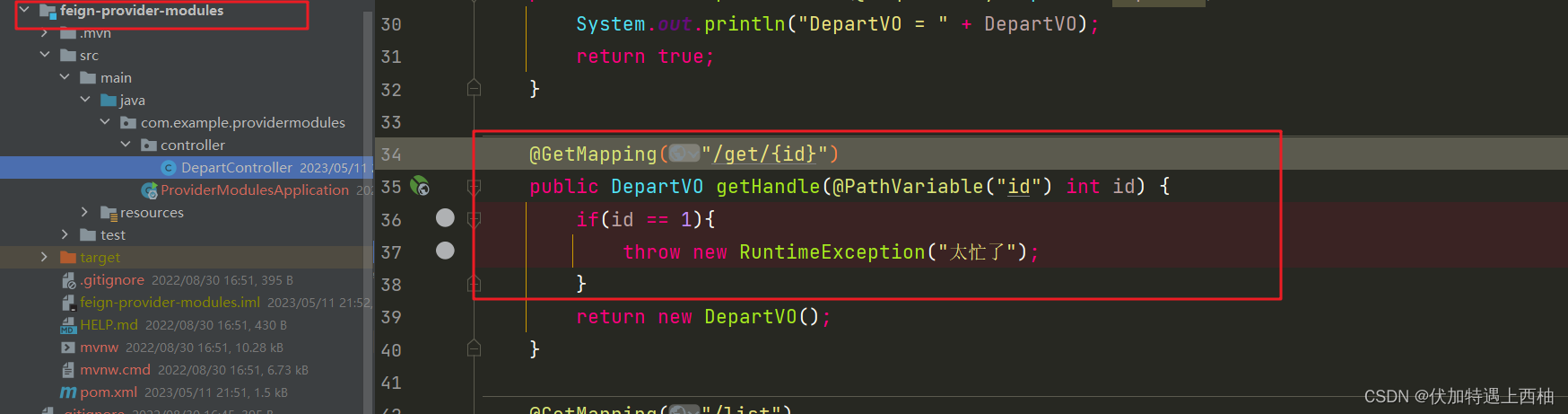
@GetMapping("/get/{id}")
public DepartVO getHandle(@PathVariable("id") int id) {
if(id == 1){
throw new RuntimeException("太忙了");
}
return new DepartVO();
}
这样如果参数是id为1,一定失败,其它情况都成功。
我们准备两个请求窗口:
- 一个请求:http://localhost:8080/consumer/1,注定失败
- 一个请求:http://localhost:8080/consumer/2,肯定成功
熔断器的默认触发阈值是20次请求,不好触发。休眠时间时5秒,时间太短,不易观察,为了测试方便。我们在consumer服务配置中修改熔断策略:
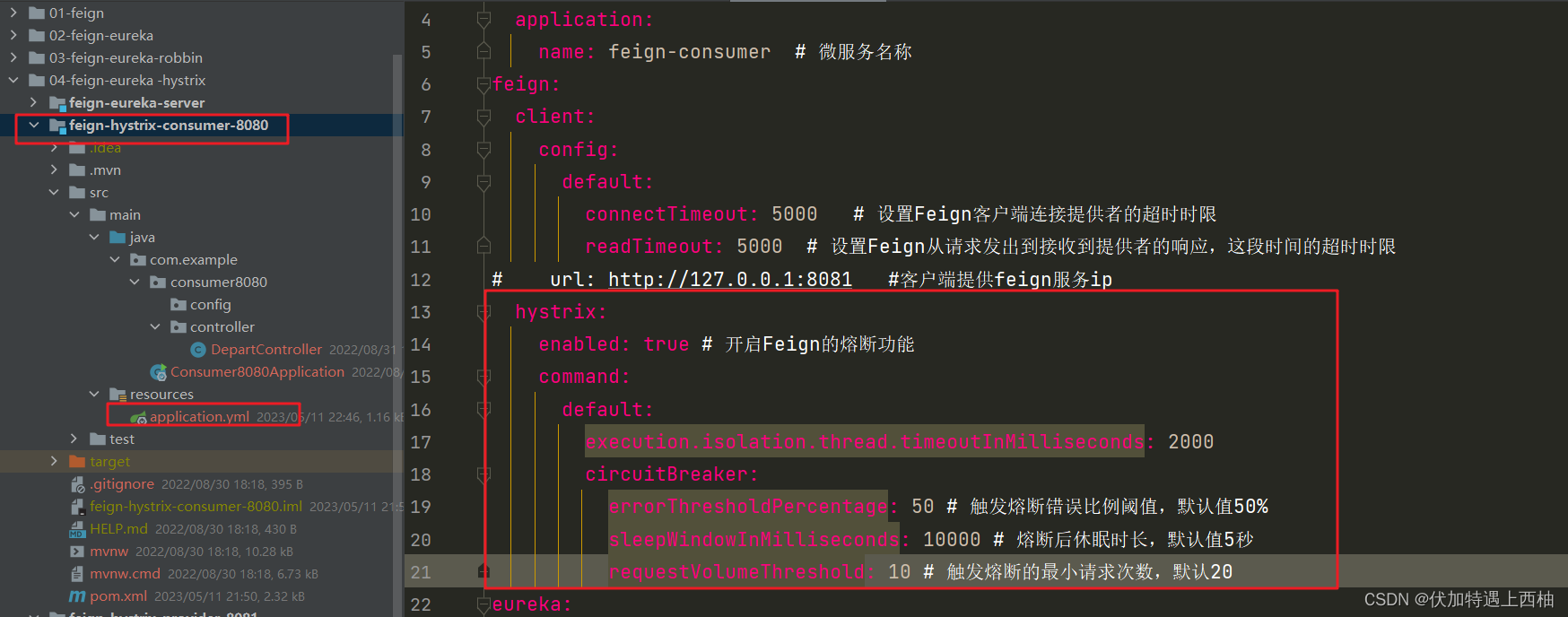
hystrix:
enabled: true # 开启Feign的熔断功能
command:
default:
execution.isolation.thread.timeoutInMilliseconds: 2000
circuitBreaker:
errorThresholdPercentage: 50 # 触发熔断错误比例阈值,默认值50%
sleepWindowInMilliseconds: 10000 # 熔断后休眠时长,默认值5秒
requestVolumeThreshold: 10 # 触发熔断的最小请求次数,默认20
解读:
requestVolumeThreshold:触发熔断的最小请求次数,默认20,这里我们设置为10,便于触发errorThresholdPercentage:触发熔断的失败请求最小占比,默认50%sleepWindowInMilliseconds:休眠时长,默认是5000毫秒,这里设置为10000毫秒,便于观察熔断现象
当我们疯狂访问id为1的请求时(10次左右),就会触发熔断。断路器会进入打开状态,一切请求都会被降级处理。

此时你访问id为2的请求,会发现返回的也是失败,而且失败时间很短,只有20毫秒左右: