目录
MyBatis-缓存-提高检索效率的利器
缓存-官方文档
一级缓存
基本说明
一级缓存原理图
代码演示
修改MonsterMapperTest.java, 增加测试方法
结果
debug 一级缓存执行流程
一级缓存失效分析
关闭sqlSession会话后 , 一级缓存失效
如果执行sqlSession.clearCache() , 会导致一级缓存失效
如果修改了同一个对象 , 会导致一级缓存[对象数据]失效
MyBatis--之二级缓存
基本介绍
示意图
二级缓存快速入门
mybatis-config.xml 配置中开启二级缓存
在对应的 XxxMapper.xml 中设置二级缓存的策略
解读
name:缓存名称。
修改 MonsterMapperTest.java , 完成测试
语句发送的顺序:
语句返回的顺序:
注意事项和使用陷阱
理解二级缓存策略的参数
上面的配置意思如下:
四大策略
如何禁用二级缓存
MonsterMapper.xml
或者更加细粒度的, 在配置方法上指定
mybatis 刷新二级缓存的设置
注意
EhCache 缓存-细节说明
MyBatis-缓存-提高检索效率的利器
缓存-官方文档
文档地址: https://mybatis.org/mybatis-3/zh/sqlmap-xml.html#cache
一级缓存
基本说明
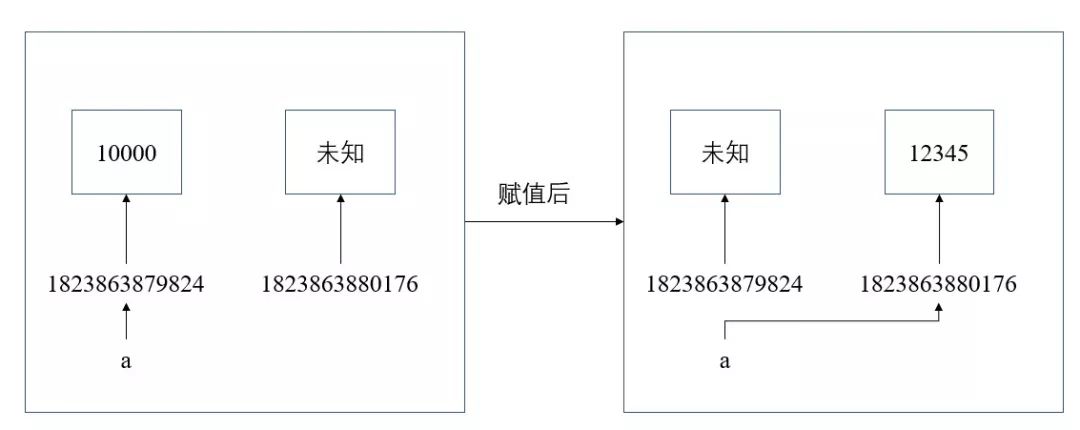
1. 默认情况下,mybatis 是启用一级缓存的/本地缓存/local Cache,它是 SqlSession 级别的。
2. 同一个 SqlSession 接口对象调用了相同的 select 语句,会直接从缓存里面获取,而不是再去查询数据库
一级缓存原理图
代码演示
需求: 当我们第 1 次查询 id=1 的 Monster 后,再次查询 id=1 的 monster 对象,就会直接从一级缓存获取,不会再次发出sql
创建新module: mybatis_cache , 必要的文件和配置直接从mybatis_quickstart module拷贝即可

使用 MonsterMapperTest.java , 运行 getMonsterById() 看看是否可以看到日志输出,结论我们多次运行,总是会发出 SQL.

修改MonsterMapperTest.java, 增加测试方法
测试一级缓存的基本使用
public class MonsterMapperTest {
//属性
private SqlSession sqlSession;
private MonsterMapper monsterMapper;
/**
* 解读
* 1. 当方法标注 @Before, 表示在执行你的目标测试方法前,会先执行该方法
* 2. 这里在测试的时候,可能小伙伴们会遇到一些麻烦,老师说了解决方案
*/
//编写方法完成初始化
@Before
public void init() {
//获取到sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//获取到到MonsterMapper对象 class com.sun.proxy.$Proxy7 代理对象
//, 底层是使用了动态代理机制, 后面我们自己实现mybatis底层机制时,会讲到
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
System.out.println("monsterMapper=" + monsterMapper.getClass());
}
@Test
public void getMonsterById() {
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster=" + monster);
if (sqlSession != null) {
sqlSession.close();
}
System.out.println("查询成功~~~~");
}
//测试一级缓存
@Test
public void level1CacheTest() {
//查询id=3的monster
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster=" + monster);
monsterMapper.getMonsterById(8);
//再次查询id=3的monster
//当我们再次查询 id=3的Monster时,直接从一级缓存获取,不会再次发出sql
System.out.println("--一级缓存默认是打开的,当你再次查询相同的id时, 不会再发出sql----");
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println("monster2=" + monster2);
if (sqlSession != null) {
sqlSession.close();
}
}
}结果
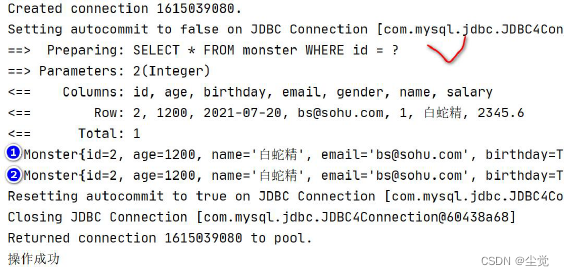
debug 一级缓存执行流程

一级缓存失效分析
1. 关闭sqlSession 会话后, 再次查询,会到数据库查询, 修改MonsterMapperTest.java,
关闭sqlSession会话后 , 一级缓存失效
//测试一级缓存,失效
//关闭sqlSession会话后 , 一级缓存失效
@Test
public void level1CacheTest2() {
//查询id=3的monster
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster=" + monster);
//关闭sqlSession, 一级缓存失效
if (sqlSession != null) {
sqlSession.close();
}
//因为关闭了sqlSession,所以需要重新初始化sqlSession和 monsterMapper
sqlSession = MyBatisUtils.getSqlSession();
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
//再次查询id=3的monster
System.out.println("--如果你关闭了sqlSession,当你再次查询相同的id时, 仍然会发出sql----");
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println("monster2=" + monster2);
if (sqlSession != null) {
sqlSession.close();
}
}如果执行sqlSession.clearCache() , 会导致一级缓存失效
@Test
public void level1CacheTest3() {
//查询id=3的monster
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster=" + monster);
//执行clearCache
/**
* @Override
* public void clearCache() {
* executor.clearLocalCache();
* }
*/
sqlSession.clearCache();
//再次查询id=3的monster
System.out.println("--如果你执行sqlSession.clearCache(),当你再次查询相同的id时, 仍然会发出sql----");
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println("monster2=" + monster2);
if (sqlSession != null) {
sqlSession.close();
}
}如果修改了同一个对象 , 会导致一级缓存[对象数据]失效
@Test
public void level1CacheTest4() {
//查询id=3的monster
Monster monster = monsterMapper.getMonsterById(3);
System.out.println("monster=" + monster);
//如果修改了同一个对象 , 会导致一级缓存[对象数据]失效
monster.setName("蚂蚱精");
monsterMapper.updateMonster(monster);
//再次查询id=3的monster
System.out.println("--如果你修改了同一个对象,当你再次查询相同的id时, 仍然会发出sql----");
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println("monster2=" + monster2);
if (sqlSession != null) {
sqlSession.commit();//这里需要commit
sqlSession.close();
}
}MyBatis--之二级缓存
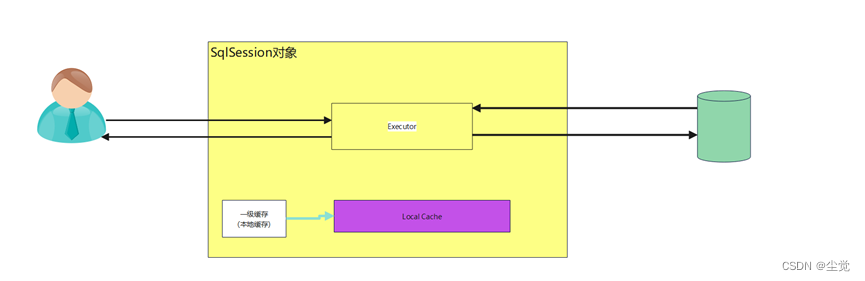
基本介绍
1. 二级缓存和一级缓存都是为了提高检索效率的技术
2. 最大的区别就是作用域的范围不一样,一级缓存的作用域是 sqlSession 会话级别,在一次会话有效,而二级缓存作用域是全局范围,针对不同的会话都有效
示意图
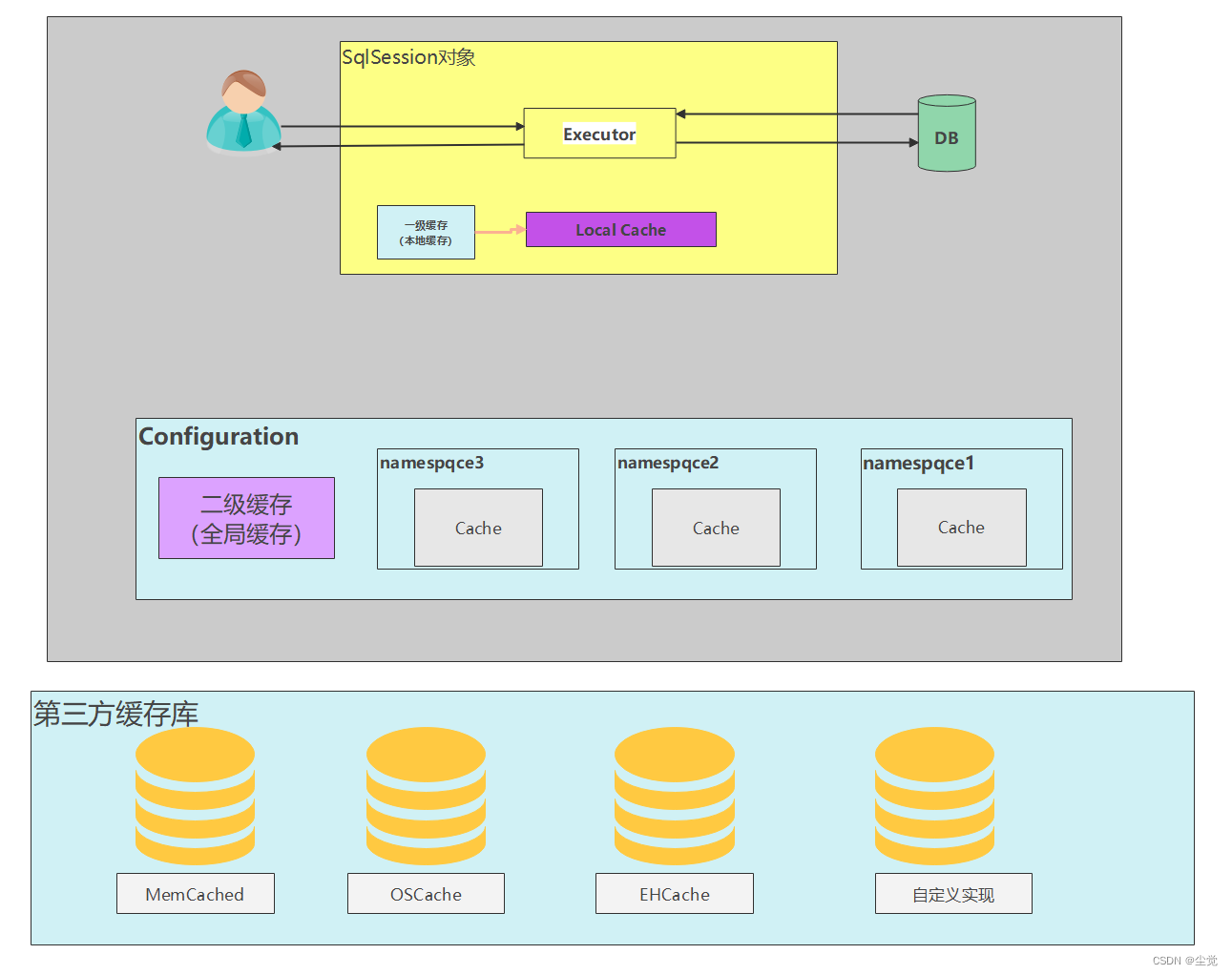
二级缓存快速入门
mybatis-config.xml 配置中开启二级缓存
<!--配置MyBatis自带的日志输出-查看原生的sql-->
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!--
1、全局性地开启或关闭所有映射器配置文件中已配置的任何缓存, 可以理解这是一个总开关
2、默认就是: true
-->
<!--开启二级缓存-->
<setting name="cacheEnabled" value="true"/>
</settings>使用二级缓存时 entity 类实现序列化接口 (serializable),因为二级缓存可能使用到序列化技术
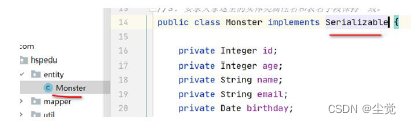
在对应的 XxxMapper.xml 中设置二级缓存的策略
如我这里是ehcache.xml.
<?xml version="1.0" encoding="UTF-8"?>
<ehcache>
<!--
diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数解释如下:
user.home – 用户主目录
user.dir – 用户当前工作目录
java.io.tmpdir – 默认临时文件路径
-->
<diskStore path="java.io.tmpdir/Tmp_EhCache"/>
<!--
defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。
-->
<!--
name:缓存名称。
maxElementsInMemory:缓存最大数目
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
overflowToDisk:是否保存到磁盘,当系统宕机时
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
diskPersistent:是否缓存虚拟机重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量最大时是否清除。
memoryStoreEvictionPolicy:可选策略(清除策略)有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
-->
<defaultCache
eternal="false"
maxElementsInMemory="10000"
overflowToDisk="false"
diskPersistent="false"
timeToIdleSeconds="1800"
timeToLiveSeconds="259200"
memoryStoreEvictionPolicy="LRU"/>
</ehcache>解读
diskStore:为缓存路径,ehcache分为内存和磁盘两级,此属性定义磁盘的缓存位置。参数
解释如下:
user.home – 用户主目录.
user.dir – 用户当前工作目录.
java.io.tmpdir – 默认临时文件路径.
defaultCache:默认缓存策略,当ehcache找不到定义的缓存时,则使用这个缓存策略。只能定义一个。
name:缓存名称
maxElementsInMemory:缓存最大数目.
maxElementsOnDisk:硬盘最大缓存个数。
eternal:对象是否永久有效,一但设置了,timeout将不起作用。
overflowToDisk:是否保存到磁盘,当系统宕机时.
timeToIdleSeconds:设置对象在失效前的允许闲置时间(单位:秒)。仅当eternal=false对象不是永久有效时使用,可选属性,默认值是0,也就是可闲置时间无穷大。
timeToLiveSeconds:设置对象在失效前允许存活时间(单位:秒)。最大时间介于创建时间和失效时间之间。仅当eternal=false对象不是永久有效时使用,默认是0.,也就是对象存活时间无穷大。
diskPersistent:是否缓存虚拟机-重启期数据 Whether the disk store persists between restarts of the Virtual Machine. The default value is false.
diskSpoolBufferSizeMB:这个参数设置DiskStore(磁盘缓存)的缓存区大小。默认是30MB。每个Cache都应该有自己的一个缓冲区。
diskExpiryThreadIntervalSeconds:磁盘失效线程运行时间间隔,默认是120秒。
memoryStoreEvictionPolicy:当达到maxElementsInMemory限制时,Ehcache将会根据指定的策略去清理内存。默认策略是LRU(最近最少使用)。你可以设置为FIFO(先进先出)或是LFU(较少使用)。
clearOnFlush:内存数量-最大时是否清除。
memoryStoreEvictionPolicy:可选策略(清除策略)有:LRU(最近最少使用,默认策略)、FIFO(先进先出)、LFU(最少访问次数)。
FIFO,first in first out,这个是大家最熟的,先进先出。
LFU, Less Frequently Used,就是上面例子中使用的策略,直白一点就是讲一直以来最少被使用的。如上面所讲,缓存的元素有一个hit属性,hit值最小的将会被清出缓存。
LRU,Least Recently Used,最近最少使用的,缓存的元素有一个时间戳,当缓存容量满了,而又需要腾出地方来缓存新的元素的时候,那么现有缓存元素中时间戳离当前时间最远的元素将被清出缓存。
修改 MonsterMapperTest.java , 完成测试
@Test
public void level2CacheTest() {
//查询id=3的monster
Monster monster = monsterMapper.getMonsterById(3);
//会发出SQL, 到db查询
System.out.println("monster=" + monster);
//这里关闭sqlSession
if (sqlSession != null) {
sqlSession.close();
}
//重新获取sqlSession
sqlSession = MyBatisUtils.getSqlSession();
//重新获取了monsterMapper
monsterMapper = sqlSession.getMapper(MonsterMapper.class);
//再次查询id=3的monster
System.out.println("--虽然前面关闭了sqlSession,因为配置二级缓存, " +
"当你再次查询相同的id时, 依然不会再发出sql, 而是从二级缓存获取数据----");
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println("monster2=" + monster2);
Monster monster3 = monsterMapper.getMonsterById(3);
System.out.println("monster3=" + monster3);
if (sqlSession != null) {
sqlSession.close();
}
}语句发送的顺序:
第一步 先去二级缓存寻找去寻找对比有就返回-->
第二步在去一级缓存去寻找对比有就返回--->
第3步再去发送sql语句去找需要的数据
语句返回的顺序:
第二步的好处:可以及时更新缓存 然后防止缓存数据出错
第一步数据库返回需要的数据-->
第二步保存或者跟新在一级缓存里面的数据-->
第三步有一级缓存发送给用户也就是是输出-->
第四步 关闭程序或者关闭sqlSession会话后 或者 执行sqlSession.clearCache() 之前判断是否开启了二级缓存是的话就把数据保存在二级缓存如果没有开启的话就直接清除
//分析缓存执行顺序
//二级缓存->一级缓存->DB
//因为二级缓存(数据)是在一级缓存关闭之后才有的
@Test
public void cacheSeqTest2() {
System.out.println("查询第1次");
//DB , 会发出 SQL, cache hit ratio 0.0
Monster monster1 = monsterMapper.getMonsterById(3);
System.out.println(monster1);
//这里我们没有关闭sqlSession
System.out.println("查询第2次");
//从一级缓存获取id=3 , cache hit ratio 0.0, 不会发出SQL
Monster monster2 = monsterMapper.getMonsterById(3);
System.out.println(monster2);
System.out.println("查询第3次");
//还是从一级缓存获取id=3, cache hit ratio 0.0, 不会发出SQL
Monster monster3 = monsterMapper.getMonsterById(3);
System.out.println(monster3);
if (sqlSession != null) {
sqlSession.commit();
sqlSession.close();
}
System.out.println("操作成功");
}注意事项和使用陷阱
理解二级缓存策略的参数
<cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>
上面的配置意思如下:
创建了 FIFO 的策略,每隔 30 秒刷新一次,最多存放 360 个对象而且返回的对象被认为是只读的。
eviction:缓存的回收策略
flushInterval:时间间隔,单位是毫秒,
size:引用数目,内存大就多配置点,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是 1024
readOnly:true,只读
四大策略
√ LRU – 最近最少使用的:移除最长时间不被使用的对象,它是默认
√ FIFO – 先进先出:按对象进入缓存的顺序来移除它们。
√ SOFT – 软引用:移除基于垃圾回收器状态和软引用规则的对象。
√ WEAK – 弱引用:更积极地移除基于垃圾收集器状态和弱引用规则的对象。
如何禁用二级缓存
<settings>
<setting name="logImpl" value="STDOUT_LOGGING"/>
<!--
<!--全局性地开启或关闭所有映射器配置文件中已配置的任何缓存, 默认就是 true-->
<!--关闭二级缓存-->
<setting name="cacheEnabled" value="false"/>
</settings>MonsterMapper.xml
<cache eviction="FIFO" flushInterval="30000" size="360" readOnly="true"/>或者更加细粒度的, 在配置方法上指定

设置 useCache=false 可以禁用当前 select 语句的二级缓存,即每次查询都会发出 sql 去查询,
默认情况是 true,即该 sql 使用二级缓存
注意:一般我们不需要去修改,使用默认的即可
mybatis 刷新二级缓存的设置
<update id="updateMonster" parameterType="Monster" flushCache="true">
UPDATE mybatis_monster SET NAME=#{name},age=#{age} WHERE id=#{id}
</update>
insert、update、delete 操作数据后需要刷新缓存,如果不执行刷新缓存会出现脏读默认为 true,默认情况下为 true 即刷新缓存,一般不用修改。
注意
在 XxxMapper.xml 中启用 EhCache , 当然原来 MyBatis 自带的缓存配置就注销了
EhCache 缓存-细节说明
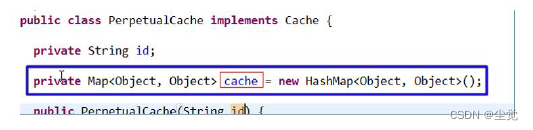
1. MyBatis 提供了一个接口 Cache 如图,找到 org.apache.ibatis.cache.Cache ,关联源码包就可以看到 Cache 接口
2. 只要实现了该 Cache 接口,就可以作为二级缓存产品和 MyBatis 整合使用,Ehcache 就是实现了该接口.
3. MyBatis 默认情况(即一级缓存)是使用的 PerpetualCache 类实现 Cache 接口的,是核心类.
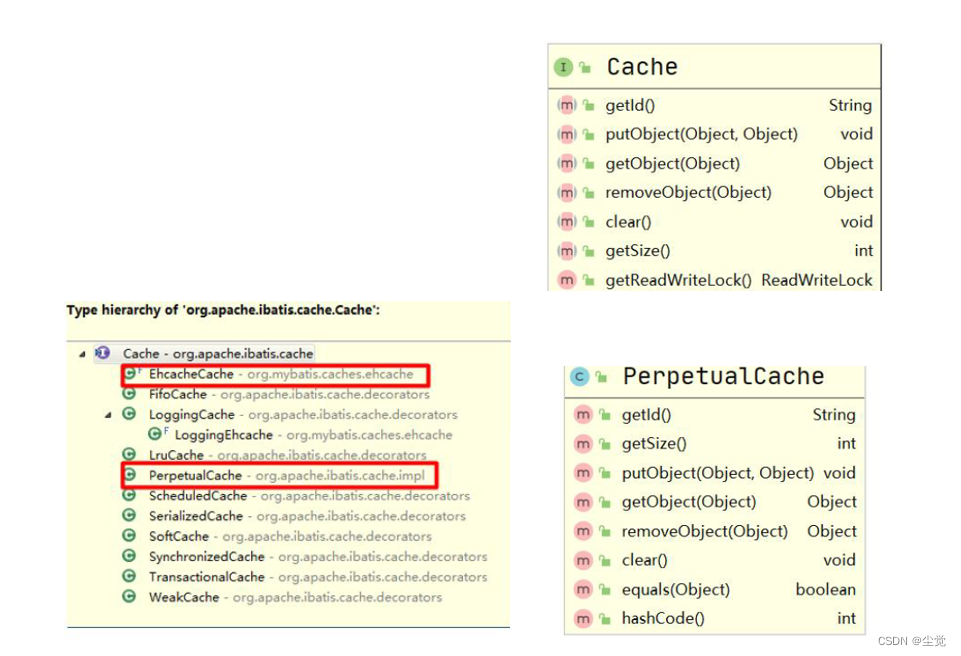
4. 当我们使用了 Ehcahce 后,就是 EhcacheCache 类实现 Cache 接口的,是核心类.
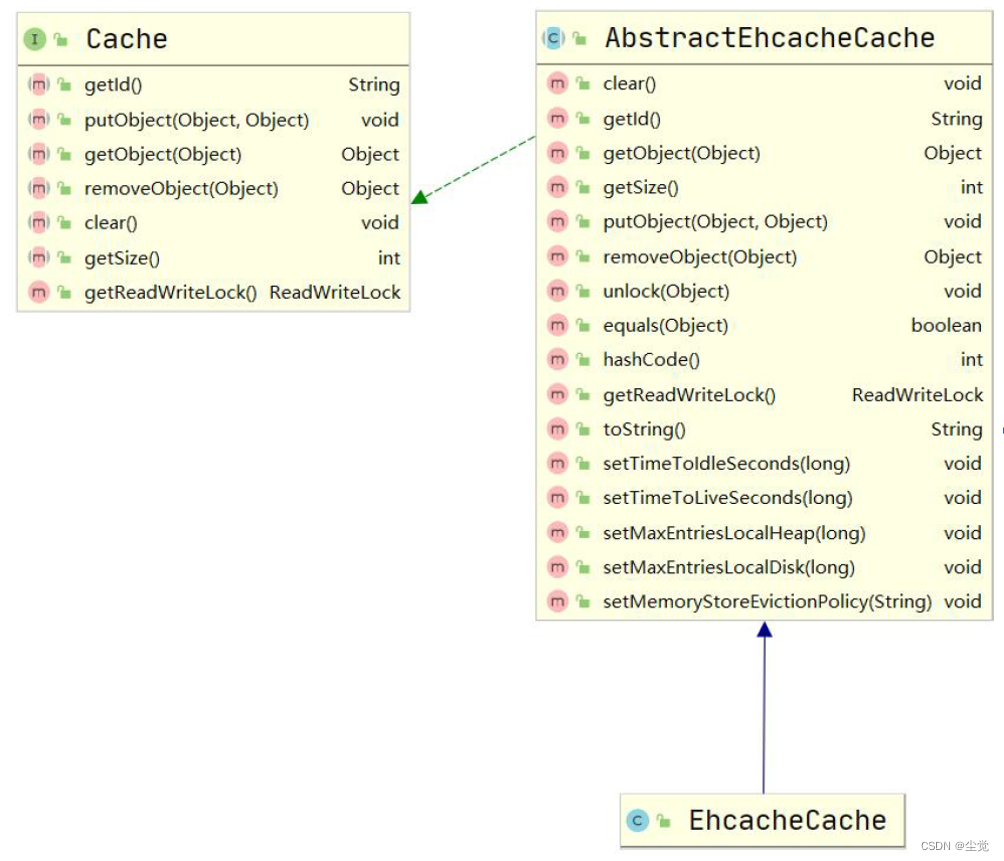
5. 我们看一下源码,发现缓存的本质就是 Map<Object,Object>
到这一步了对二级缓存也就没有多少疑惑了。