项目地址:https://github.com/kpretty/hdd
我在21年的国庆写过一篇文章:《Docker 实战:部署hadoop集群》,当时也是刚接触docker,作为docker第一个练手项目对很多概念理解的不是很到位,因此那篇文章所使用的思路很简单粗暴,只是利用docker的centos镜像并把它看成一个物理机进行配置。这样的似乎显然是与云原生背道而驰的。时隔一年多随着对docker以及云原生的进一步理解同时这段时间也接触到很多优质的开源项目,因此才有个萌生重构这个项目的想法。
一、思路分析
我们知道hadoop有六个常用的服务分别是:namenode,secondarynamenode、datanode、resourcemanager、nodemanager、jobhistory。按照服务拆分的思想把每个服务都独立成一个镜像,这样的好处在于:
- 构建镜像时目的更加明确,解耦合
- 扩容更加方便,扩容就是增加一个容器
当构建好镜像后借助docker-compose进行编排,为了进一步简化部署流程需要提供一个客户端,完成docker-compose.yml文件的自动生成、启动、停止、删除等运维功能。下面将通过镜像构建和客户端分别阐述
1.1 镜像构建
面临的第一个问题就是构建几个镜像问题,需要为每一个服务都构建一个独立的镜像吗?显然是不需要的因为每个服务都可以有相同的配置文件,也就是镜像中的hadoop文件是一样的,服务于服务之间唯一的区别就是启动脚本不同,因此我们只需要构建一个镜像,通过内置好不同服务的启动脚本,在容器启动时通过覆盖其CMD即可实现启动不同的服务
1.2 客户端
客户端需要完成compose文件的自动构建,以及封装容器的启动脚本,同时计划多个hadoop集群管理,因此提出了stack的概念,每个stack就是一个hadoop集群,在本地存储形式为文件夹,每个stack有自己的docker-compose.yml和一些必要的配置文件,这样就完成了hadoop集群之间的隔离,对应集群的启动就是执行对应文件夹的compose文件,删除就是删除对应stack的文件夹即可。
二、思路实现
1.1 镜像构建
首先是基础镜像的选定,我们选用openjdk:8的镜像,为什么不选用centos,因此这个镜像太大了,openjdk使用的基础镜像是alpine,被誉为最小的linux镜像,因此使用openjdk原生就有了java环境同时可以尽可能的减小镜像体积。基础镜像选定后就开始考虑服务的封装
最难的服务就是namenode,因为它涉及到格式化,在首次启动的时候需要进行一次格式化。因此我们需要一个机制来判断每次容器启动时是否需要进行格式化,最简单的思路就是格式化完成后在指定目录创建一个flag文件,每次容器启动时判断这个文件是否存在,不存在则进行格式化同时创建文件,存在则启动namenode服务
提问:为什么不去检查namenode在本地存储的文件来判断是否进行了格式化?
下面是namenode的启动脚本
#!/bin/bash
FORMAT_FLAG=/formatted.hdp
# 判断是否已经初始化
if [ ! -f ${FORMAT_FLAG} ]; then
echo "开始格式化NameNode"
"${HADOOP_HOME}"/bin/hdfs namenode -format
touch ${FORMAT_FLAG}
fi
"${HADOOP_HOME}"/sbin/hadoop-daemons.sh start namenode
echo "NameNode已启动"
而其他服务的启动脚本就很简单了
datanode
#!/bin/bash
"${HADOOP_HOME}"/sbin/hadoop-daemons.sh start datanode
echo "DataNode已启动"
secondarynamenode
#!/bin/bash
"${HADOOP_HOME}"/sbin/hadoop-daemons.sh start secondarynamenode
echo "SecondaryNameNode已启动"
resourcemanager
#!/bin/bash
"${HADOOP_HOME}"/sbin/yarn-daemons.sh start resourcemanager
echo "ResourceManager已启动"
nodemanager
#!/bin/bash
"${HADOOP_HOME}"/sbin/yarn-daemons.sh start nodemanager
echo "NodeManager已启动"
jobhistory
#!/bin/bash
"${HADOOP_HOME}"/sbin/mr-jobhistory-daemon.sh start historyserver
echo "JobHistory已启动"
我们配置hadoop是有个必要步骤就是在hadoop-env.sh中写死JAVA_HOME,即使环境变量中也需要写一下,否则会启动失败同时还需要做一个免密
问:基于docker的方式需要配置集群的免密吗?
答:需要也不需要,首先需要明白为什么要免密。通过对启动脚本的分析我们可以看出hadoop服务的启动是通过ssh来启动的,这也就是为什么之心start-dfs.sh相关服务器就会启动hdfs,这是因为这个脚本直接通过ssh登录到对方服务器后执行启动脚本。回到问题需要免密是即使启动自身的服务也是通过这种方式,因此需要配置自己到自己的免密服务;不需要是因为我们通过容器的方式启动,不需要使用群起脚本因此就不需要配置两个容器之间的免密。同时你也配置不出来,因为现有镜像在有容器,容器都没有启动在构建镜像时也无从配起。
因此需要一个初始化脚本,如下:
# 启动ssh服务
service ssh start
# 将JAVA_HOME写入hadoop-env.sh中
echo "export JAVA_HOME=$JAVA_HOME" >> "${HADOOP_HOME}"/etc/hadoop/hadoop-env.sh
因此将上述启动脚本进行整合,通过容器启动时的CMD来判断一下需要执行哪个服务的启动脚本,即run-server.sh
#!/bin/bash
# 初始化系统服务和做一些通用的处理
sh /init-server.sh
# 根据参数启动不同服务:nn,dn,2nn,rm,nm,jh
case $1 in
nn)
sh /start-namenode.sh
;;
dn)
sh /start-datanode.sh
;;
2nn)
sh /start-secondarynamenode.sh
;;
rm)
sh /start-resourcemanager.sh
;;
nm)
sh /start-nodemanager.sh
;;
jh)
sh /start-jobhistory.sh
;;
*)
echo "ERROR:未知参数"
exit 1
;;
esac
while :
do
# 死循环,让容器持续运行
sleep 1
done
# todo 后续计划将对应服务的日志发送到容器的stdout,使得docker logs可以看到日志[再议]
下面就是大一统的Dockerfile文件
FROM openjdk:8
MAINTAINER wjun
MAINTAINER wjunjobs@outlook.com
ARG version=3.3.4
# 配置自身到自身的免密
RUN apt update \
&& apt install -y openssh-server \
&& mkdir -p ~/.ssh \
&& ssh-keygen -b 2048 -t rsa -f ~/.ssh/id_rsa -q -N "" \
&& cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
WORKDIR /opt
COPY hadoop-${version}.tar.gz hadoop-${version}.tar.gz
COPY run-server.sh /run-server.sh
COPY start-namenode.sh /start-namenode.sh
COPY init-server.sh /init-server.sh
COPY start-datanode.sh /start-datanode.sh
COPY start-jobhistory.sh /start-jobhistory.sh
COPY start-nodemanager.sh /start-nodemanager.sh
COPY start-resourcemanager.sh /start-resourcemanager.sh
COPY start-secondarynamenode.sh /start-secondarynamenode.sh
RUN tar -zxf hadoop-${version}.tar.gz \
&& mv hadoop-${version} hadoop \
&& rm -rf hadoop-${version}.tar.gz
CMD ["sh","/run-server.sh"]
最终通过docker build即可构建,同时镜像已经上传到dockerhub和github上,不想构建镜像可以直接pull
# github
docker pull ghcr.io/kpretty/hadoop:latest
# dockerhub
docker pull kpretty/hadoop:latest
注:博主的电脑是arm架构,因此pull下来的镜像是arm的,电脑架构不一致时需要自行构建
2.2 客户端
首先需要考虑的问题就是语言的选择,看到github仓库发现是有两套语言实现的客户端(python和rust),使用python是因为想要快速实现一个先行版本,方便测试和提前发现想法上的漏洞,但python作为解释型语言对用户电脑环境要求及其严苛(需要安装python环境和所依赖的所有第三方包),显然这种方式对用户的使用体验是糟糕的(不要提python可以打包成二进制文件),因此需要使用编译型语言来开发客户端,而编译型语言目前最拿手的就是rust,当然这个项目也称为我rust的第一个练手项目,rust大佬请手下留情(rust刚学不久)
2.2.1 没有用的help
作为我的第一个开源项目肯定要有一个详细的help界面和炫酷的logo,代码很简单就不解释了
// ----------------------------------------------->
// 控制台颜色打印
const REST: &str = "\x1b[0m";
const RED: &str = "\x1b[31m";
const GREEN: &str = "\x1b[32m";
const YELLOW: &str = "\x1b[33m";
const BLUE: &str = "\x1b[34m";
#[allow(dead_code)]
pub enum Color {
RED,
GREEN,
YELLOW,
BLUE,
}
#[allow(dead_code)]
fn print_color(color_type: &Color, message: &str) {
match color_type {
Color::RED => println!("{}{}{}", RED, message, REST),
Color::GREEN => println!("{}{}{}", GREEN, message, REST),
Color::YELLOW => println!("{}{}{}", YELLOW, message, REST),
Color::BLUE => println!("{}{}{}", BLUE, message, REST),
}
}
#[allow(dead_code)]
pub(crate) fn print_red(message: String) {
print!("{}{}{}", RED, message, REST)
}
#[allow(dead_code)]
fn print_green(message: String) {
print!("{}{}{}", GREEN, message, REST)
}
#[allow(dead_code)]
pub(crate) fn print_yellow(message: String) {
print!("{}{}{}", YELLOW, message, REST)
}
#[allow(dead_code)]
fn print_blue(message: String) {
print!("{}{}{}", BLUE, message, REST)
}
// <-----------------------------------------------
// ----------------------------------------------->
// 产品相关信息
pub fn print_logo() {
let logo_up: String = format!("{}{}{}{}",
" ___ ___ ___ \n",
" /\\__\\ /\\ \\ /\\ \\\n",
" /:/ / /::\\ \\ /::\\ \\\n",
" /:/__/ /:/\\:\\ \\ /:/\\:\\ \\ \n"
);
let logo_mid: String = format!("{}{}{}{}",
" /::\\ \\ ___ /:/ \\:\\__\\ /:/ \\:\\__\\\n",
" /:/\\:\\ /\\__\\ /:/__/ \\:|__| /:/__/ \\:|__|\n",
" \\/__\\:\\/:/ / \\:\\ \\ /:/ / \\:\\ \\ /:/ /\n",
" \\::/ / \\:\\ /:/ / \\:\\ /:/ / \n");
let logo_down: String = format!("{}{}{}",
" /:/ / \\:\\/:/ / \\:\\/:/ /\n",
" /:/ / \\::/__/ \\::/__/\n",
" \\/__/ ~~ ~~\n");
print_red(logo_up);
print_yellow(logo_mid);
print_green(logo_down);
}
pub fn print_desc() {
let hdd_desc = "HDD CLI is a developer tool used to manage local development stacks\n\n\
This tool automates creation of stacks with many infrastructure components which\n\
would otherwise be a time consuming manual task. It also wraps docker compose\n\
commands to manage the lifecycle of stacks.\n\n";
println!("{}", hdd_desc);
}
pub fn print_start() {
let hdd_start = "To get started run: hdd init\n\n\
Usage:\n hdd [command]\n\n\
Available Commands:\n \
help 帮助命令\n \
info 查看stack详细信息[未完成]\n \
init 初始化一个stack\n \
list 查看所有stack\n \
logs 查看某个stack日志信息[未完成]\n \
ls 查看所有stack\n \
remove 移除stack\n \
start 启动stack\n \
stop 停止stack\n \
status 查看stack状态\n \
version 打印版本信息\n";
println!("{}", hdd_start);
}
pub fn print_common() {
print_logo();
print_desc();
print_start();
}
// <-----------------------------------------------
测试结果如下:
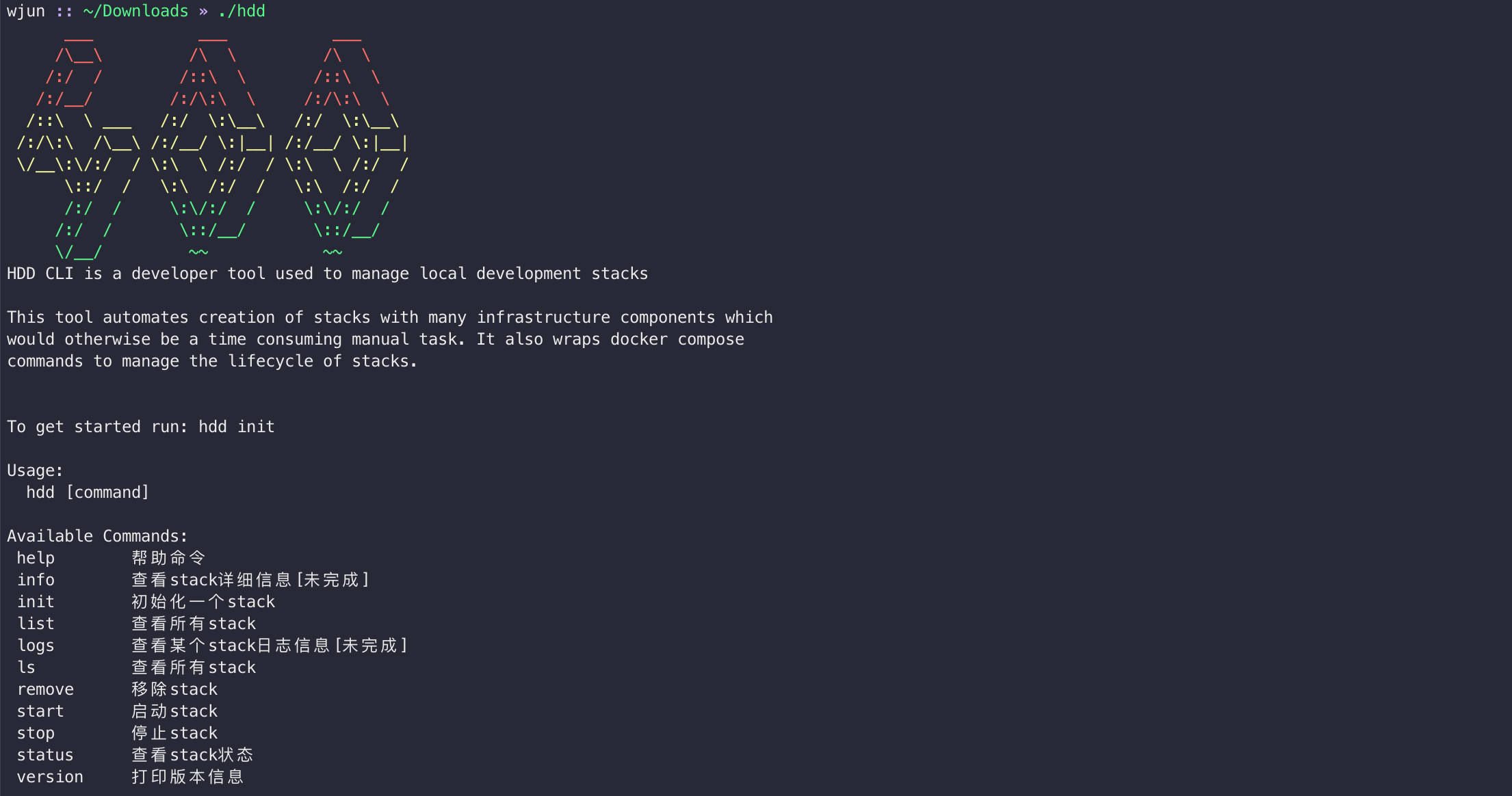
很炫酷我很喜欢
2.2.2 最难的init
首先解释一下stack,stack相当于一个hadoop项目或者工作空间,用于隔离每个hadoop集群,在本地存储相当于一个文件夹。而init一个stack就是在本地创建一个文件夹,存储自动生成的docekr-compose.yml文件和必要的配置文件。因此init一定会有stack name参数指定stack名称。同时需要指定每个服务的个数,这里约定参数
- -nn:指定namenode个数
- -dn:指定datanode个数
- -2nn:指定secondarynamenode个数
- -rm:指定resourcemanager个数
- -nm:指定nodemanager个数
- -jh:指定jobhistory个数
因此init一个比较好的参数就是
./hdd init dev -nn 1 -dn 3 -rm 1 -nm 3 -2nn 1 -jh 1
注:hdd是客户端构建的二进制文件
init第一步需要进行参数校验,去除stack name后续的参数首先一定是偶数个,同时当前版本暂时没有实现组件的HA,因此就要求nn、rm、2nn、jh的值必须是1,同时nn和rm必须存在一个(可以两个都有但不能都没有),最后就是如果nn没有那么dn就不应该有,rm和nm逻辑同样如此。
因此参数校验的代码如下:
fn check_args(args: Vec<String>) -> HashMap<String, u32> {
if args.len() % 2 != 0 {
// 参数不对齐
println!("参数不对齐,请检查参数:{:?}", args);
process::exit(1);
}
let mut param: HashMap<String, u32> = HashMap::new();
let mut index = 0;
loop {
if index >= args.len() {
break;
}
let key = &args[index];
let value: u32 = args[index + 1].parse().expect("节点个数存在非正整数");
param.insert(key.to_owned(), value);
index += 2;
}
// step-1 nn和rm至少要有一个
if !param.contains_key("-nn") && !param.contains_key("-rm") {
print_red("namenode或resourcemanager需要至少存在一个 ".to_string());
process::exit(1);
}
// step-2 有worker节点但没有master节点
if (!param.contains_key("-nn") && *param.get("-dn").unwrap() > 0) || (!param.contains_key("-rm") && *param.get("-nm").unwrap() > 0) {
print_red("worker节点缺少master节点管理 ".to_string());
process::exit(1);
}
// step-3 检查高可用
if (param.contains_key("-nn") && *param.get("-nn").unwrap() > 1) ||
(!param.contains_key("-rm") && *param.get("-rm").unwrap() > 1) ||
(!param.contains_key("-jh") && *param.get("-jh").unwrap() > 1) ||
(!param.contains_key("-2nn") && *param.get("-2nn").unwrap() > 1) {
print_red("当前版本暂不支持HA,请确保namenode|resourcemanager|jobhistory|secondarynamenode个数为1".to_string());
process::exit(1);
}
// ...
param
}
当参数校验通过后,需要检查stack_name是否存在,本质就是文件夹是否已经存在,存在报错不存在创建即可,代码如下(简单不解释)
fn stack_exist(stack: &String) -> PathBuf {
let path = get_hdd_path();
// 校验项目根目录是否存在
if !path.exists() {
// notice: create_dir_all 会产生所有权的移交,注意使用借用
println!("初始化项目空间:{:?}", path);
std::fs::create_dir_all(&path).unwrap();
}
// 拼接stack路径
let stack_path = path.join(Path::new(stack));
if stack_path.exists() {
// 文件夹存在,则无法执行init操作,停止程序
println!("stack:{}已经存在", stack);
process::exit(1);
} else {
// 不存在则创建
println!("创建stack:{},本地路径:{:?}", stack, stack_path);
std::fs::create_dir_all(&stack_path).unwrap();
// 拷贝文件夹
for dir in vec!["init", "env"] {
// let src = get_project_root().unwrap().join(Path::new(dir));
let src = match get_project_root() {
Ok(path) => path.join(Path::new(dir)),
Err(_) => Path::new(dir).to_path_buf(),
};
let dest = stack_path.join(Path::new(dir));
copy_dir(&src, &dest)
}
}
stack_path
}
下面就是最关键的构建docekr-compose.yml文件了,这里使用第三方库
[dependencies]
serde = { version = "1", features = ["derive"] }
serde_yaml = "0.9.13"
首先定义相关的实体类,在rust中就是结构体struct
#[derive(Debug, Serialize, Deserialize)]
pub struct Server {
pub version: String,
pub services: HashMap<String, InnerServer>,
}
#[derive(Debug, Serialize, Deserialize)]
pub struct InnerServer {
pub env_file: Vec<String>,
pub image: String,
pub hostname: String,
pub container_name: String,
pub volumes: Vec<String>,
pub ports: Vec<String>,
pub command: Vec<String>,
}
下面就是通过参数来获取每个服务的个数,或者说结构体InnerServer的个数,最终将结构体Server序列化到stack对应的文件夹中即可,代码如下:
// 构建docker-compose文件
fn build_compose(stack: &PathBuf, param: HashMap<String, u32>) {
use crate::entity::{Server, InnerServer};
// 固定参数
let image = "kpretty/hadoop".to_string();
let volume_path = stack.join(Path::new("init"));
let volumes = vec![
format!("{}:{}", volume_path.join("core-site.xml").into_os_string().into_string().unwrap(), "/opt/hadoop/etc/hadoop/core-site.xml"),
format!("{}:{}", volume_path.join("hdfs-site.xml").into_os_string().into_string().unwrap(), "/opt/hadoop/etc/hadoop/hdfs-site.xml"),
format!("{}:{}", volume_path.join("yarn-site.xml").into_os_string().into_string().unwrap(), "/opt/hadoop/etc/hadoop/yarn-site.xml"),
format!("{}:{}", volume_path.join("mapred-site.xml").into_os_string().into_string().unwrap(), "/opt/hadoop/etc/hadoop/mapred-site.xml"),
format!("{}:{}", volume_path.join("capacity-scheduler.xml").into_os_string().into_string().unwrap(), "/opt/hadoop/etc/hadoop/capacity-scheduler.xml"),
];
let env_path = stack.join("env");
let env_hdfs = vec![env_path.join("hdd-hdfs.env").into_os_string().into_string().unwrap()];
let env_yarn = vec![env_path.join("hdd-yarn.env").into_os_string().into_string().unwrap()];
let mut env_file = env_hdfs.to_owned();
env_file.append(&mut env_yarn.to_owned());
let base_command = vec!["sh".to_string(), "/run-server.sh".to_string()];
// end
let mut services: HashMap<String, InnerServer> = HashMap::new();
// namenode
match param.get("-nn") {
None => {}
Some(_) => {
let mut command = base_command.to_owned();
command.push("nn".to_string());
let nn = InnerServer {
env_file: env_hdfs.to_owned(),
image: image.to_owned(),
hostname: "namenode".to_string(),
container_name: "namenode".to_string(),
volumes: volumes.to_owned(),
ports: vec!["9870:9870".to_string()],
command,
};
services.insert("namenode".to_string(), nn);
}
}
// datanode
match param.get("-dn") {
None => {}
Some(value) => {
let mut command = base_command.to_owned();
command.push("dn".to_string());
for i in 0..*value {
let name = format!("{}-{}", "datanode", i).to_string();
let dn = InnerServer {
env_file: env_hdfs.to_owned(),
image: image.to_owned(),
hostname: name.to_owned(),
container_name: name.to_owned(),
volumes: volumes.to_owned(),
ports: vec![],
command: command.to_owned(),
};
services.insert(name, dn);
}
}
}
// secondarynamenode
match param.get("-2nn") {
None => {}
Some(_) => {
let mut command = base_command.to_owned();
command.push("2nn".to_string());
let snn = InnerServer {
env_file: env_file.to_owned(),
image: image.to_owned(),
hostname: "secondarynamenode".to_string(),
container_name: "secondarynamenode".to_string(),
volumes: volumes.to_owned(),
ports: vec![],
command,
};
services.insert("secondarynamenode".to_string(), snn);
}
}
// resourcemanager
match param.get("-rm") {
None => {}
Some(_) => {
let mut command = base_command.to_owned();
command.push("rm".to_string());
let rm = InnerServer {
env_file: env_yarn.to_owned(),
image: image.to_owned(),
hostname: "resourcemanager".to_string(),
container_name: "resourcemanager".to_string(),
volumes: volumes.to_owned(),
ports: vec!["8088:8088".to_string()],
command,
};
services.insert("resourcemanager".to_string(), rm);
}
}
// nodemanager
match param.get("-nm") {
None => {}
Some(value) => {
let mut command = base_command.to_owned();
command.push("nm".to_string());
for i in 0..*value {
let name = format!("{}-{}", "nodemanager", i).to_string();
let nm = InnerServer {
env_file: env_yarn.to_owned(),
image: image.to_owned(),
hostname: name.to_owned(),
container_name: name.to_owned(),
volumes: volumes.to_owned(),
ports: vec![],
command: command.to_owned(),
};
services.insert(name.to_owned(), nm);
}
}
}
// jobhistory
match param.get("-jh") {
None => {}
Some(_) => {
let mut command = base_command.to_owned();
command.push("jh".to_string());
let jh = InnerServer {
env_file: env_file.to_owned(),
image: image.to_owned(),
hostname: "jobhistory".to_string(),
container_name: "jobhistory".to_string(),
volumes: volumes.to_owned(),
ports: vec![],
command,
};
services.insert("jobhistory".to_string(), jh);
}
}
let server = Server {
version: "3.0".to_string(),
services,
};
let result = serde_yaml::to_string(&server).unwrap();
let mut file = File::create(stack.join("docker-compose.yml")).unwrap();
file.write_all((&result).as_ref()).unwrap();
}
这样init语义就完成了,将上面的代码封装一下就ok啦
pub fn init(mut args: Vec<String>) {
// 第一个参数为stack名
let stack = args.remove(0);
// 修改:应该先校验参数,参数没问题再去创建相对应的文件夹
// step-1 校验参数
let args = check_args(args);
// step-2 检查stack是否存在
let stack_path = stack_exist(&stack);
// step-3 生成docker-compose文件
build_compose(&stack_path, args)
}
2.2.3 其他比较简单的命令
start:逻辑就是根据stack name找到对应文件夹下面的docker-compose.yml然后通过docker-compose -f xxx up -d来启动即可,代码如下
pub fn start(args: Vec<String>) {
// 校验参数
let stack = check_args_for_stack(args);
let stack_file_path = stack.join("docker-compose.yml").into_os_string().into_string().unwrap();
let output = Command::new("docker-compose")
.args(["-f", &stack_file_path[..], "up", "-d"])
.output()
.unwrap();
handle_output(output);
}
至于stop、rm、list原理都差不多就不详细说明了,可以去github上看具体的实现
最终封装一个所有的命令就完成啦
mod entity;
mod helper;
mod cmd;
use std::env;
use helper::*;
use crate::cmd::{init, list, remove, start, status, stop};
fn main() {
// 获取命令行参数
let mut args: Vec<String> = env::args().collect();
// ./hdd init dev -nn 1 -dn 3 -rm 1 -nm 3 -2nn 1 -jh 1
// ["./hdd", "init", "dev", "-nn", "1", "-dn", "3", "-rm", "1", "-nm", "3", "-2nn", "1", "-jh", "1"]
// 第一个参数为脚本名 不要
args.remove(0);
if args.len() <= 0 {
print_common();
return;
}
// ["init", "dev", "-nn", "1", "-dn", "3", "-rm", "1", "-nm", "3", "-2nn", "1", "-jh", "1"]
// 获取 action
let action: String = args.remove(0);
match action.trim() {
"init" => init(args),
"list" | "ls" => list(),
"start" => start(args),
"status" => status(args),
"stop" => stop(args),
"remove" | "rm" => remove(args),
"version" => println!("{} by {}", env!("CARGO_PKG_VERSION"), env!("CARGO_PKG_LICENSE")),
"help" => {
print_start();
}
_ => {
println!("未知操作 {}", action);
print_common();
}
}
}
2.3 交叉编译
仓库的release提供了三个版本的二进制客户端文件分别是:mac的arm、win的x86和linux的x86,rust交叉编译只需要在项目根目录创建文件夹.cargo,创建文件config
[target.x86_64-unknown-linux-musl]
linker = "x86_64-linux-musl-gcc"
[target.x86_64-pc-windows-gnu]
linker = "x86_64-w64-mingw32-gcc"
ar = "x86_64-w64-mingw32-gcc-ar"
2.3.1 win
安装windows-gun
rustup target add x86_64-pc-windows-gnu
安装mingw-w64
brew install mingw-w64
编译
cargo build --release --target x86_64-pc-windows-gnu
2.3.2 linux
安装musl工具链
rustup target add x86_64-unknown-linux-musl
安装musl-cross
brew install filosottile/musl-cross/musl-cross
编译
cargo build --release --target x86_64-unknown-linux-musl





![[附源码]Python计算机毕业设计Django飞越青少儿兴趣培训机构管理系统](https://img-blog.csdnimg.cn/6b43c1bac1774a47834b0ee6de9e6365.png)