【数据结构】结构最复杂实现最简单的双向带头循环链表
- 一、前言
- 二、目标
- 三、实现
- 1、初始化工作
- 2、尾插
- 2.1、图解思路
- 2.2、代码实现
- 3、尾删
- 3.1、图解思路
- 3.2、代码实现
- 4、打印链表
- 5、头插
- 5.1、图解思路
- 5.2、代码实现
- 6、头删
- 6.1、图解思路
- 6.2、代码实现
- 7、查找
- 8、随机插入
- 8.1、图解思路
- 8.2、代码实现
- 9、随机删除
- 9.1、图解思路
- 9.2、代码实现
- 10、链表的销毁
一、前言
有人可能会疑惑为什么突然就从结构最简单的单向无头非循环链表转到结构最复杂度双向带头循环链表,这好像跨度有点大啊。
但这两个链表是两个很好的极端,单向无头非循环链表虽然结构最简单:

但也正因为其结构最简单给它带来了很多局限性,比如对于每个节点我们只能找到它的后继而不能找到它的前驱,尾插的时候总是需要从头遍历找到尾节,总是要特殊处理头指针的改变等等……
所以单向无头非循环链表实现起来应该是最难的。
而双向带头循环链表虽然结构最复杂:

但也正是因为它复杂度结构使得它在使用的时候有更多的选择,比如对于每个节点,我们不仅能找到它的后继,也能找到它的前驱,或者是找尾很方便。
所以双向带头循环链表的实现应该是最简单的。
所以只要搞清楚了这两个链表,那我们再看其他结构的链表的时候也就游刃有余了。
二、目标
双向带头循环链表所需要实现的功能大致如下:
// 初始化链表
void InitList(ListNode* head);
// 创建一个新节点,返回节点指针
ListNode* create_newnode(data_type x);
// 双向循环链表的尾插
void double_circle_list_push_back(ListNode* head, data_type x);
// 双向循环链表的尾删
void double_circle_list_pop_back(ListNode *head);
// 双向循环链表的打印
void print_double_circle_list(ListNode* head);
// 双向循环链表的头插
void double_circle_list_push_front(ListNode* head, data_type x);
// 双向循环链表的头删
void double_circle_list_pop_front(ListNode* head);
// 双向循环链表的查找,返回查找到的节点的指针,若找不到则返回NULL
ListNode* find_Node(ListNode* head, data_type x);
// 双向循环链表的随机插入,在目标节点的后面插入新节点
void double_circle_list_insert(ListNode* target, data_type x);
// 双向循环链表的随机删除,从链表中删除目标节点
void double_circle_list_remove(ListNode* target);
// 双向循环链表的销毁
void destroy_double_circle_list(ListNode* head);
其实这跟单链表的功能也大差不差,只是实现的思路不一样而已。
那接下来就让我们一个一个的实现吧。
三、实现
1、初始化工作
同样的我们还是先把节点类型定义了和数据域的数据类型重定义了:
// 将数据类型重定义
typedef int data_type;
// 创建节点类型
typedef struct double_circle_list_node {
data_type val;
struct double_circle_list_node* prev;
struct double_circle_list_node* next;
} ListNode ;
接下来我们就可以对已有的链表头节点进行初始化了,循环链表必须保证在任何情况下都成环,所以我们初始化时,应该把头节点的next和prev都指向它自己:
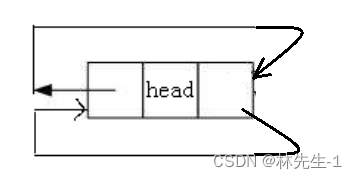
代码如下:
// 初始化链表
void InitList(ListNode* head) {
assert(head);
head->prev = head;
head->next = head;
}
而又因为我们后面在写个各个插入节点的函数的时候需要动态开辟一个新的节点,所以我们就行一个函数用来创建一个新节点,返回节点指针:
// 创建一个新节点,返回节点指针
ListNode* create_newnode(data_type x) {
ListNode* newNode = (ListNode*)malloc(sizeof(ListNode));
if (NULL == newNode) {
perror("malloc fail\n");
exit(-1);
}
newNode->val = x;
return newNode;
}
这样我们的初始化工作就都完成了。
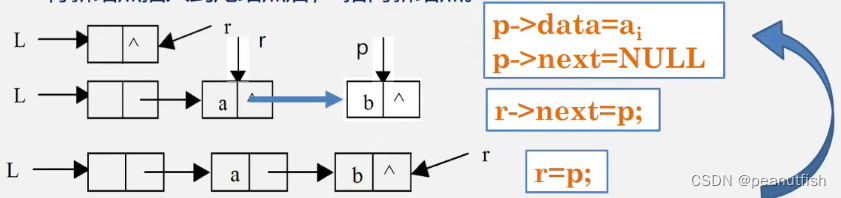
2、尾插
2.1、图解思路
比起单链表,双向循环链表找起尾来简直不要太简单,因为头节点的prev始终都指向链表的最后一个节点,所以尾节点tail即为head->prev:
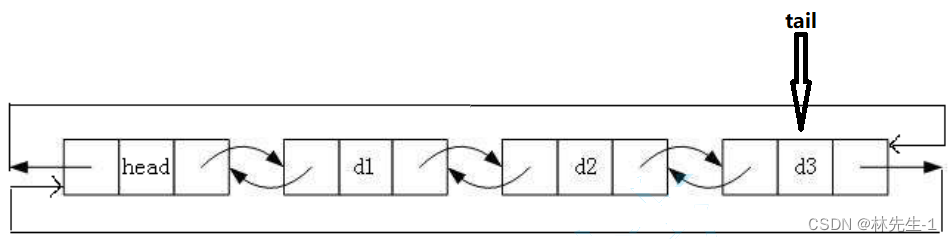
所以我们创建好新的节点后就可以直接将各个指针指向相应的地方了:

分别是:
newNode->prev = tail;
tail->next = newNode;
newNode->next = head;
head->prev = newNode;
当然这四个指针的更改顺序随便打乱也是毫无影响的。
而我们是否需要额外考虑链表中只有一个头节点的情况呢?
其实是不用的,因为如果链表中只有一个头结点,那么按照上面的逻辑,tail指向的也还是头节点:
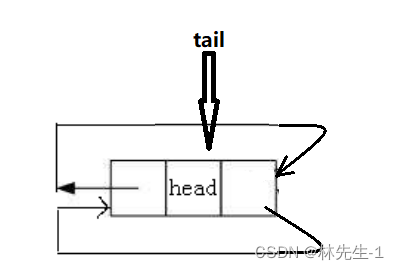
这时候我们再执行上面一样的逻辑,也还是能达到效果的:
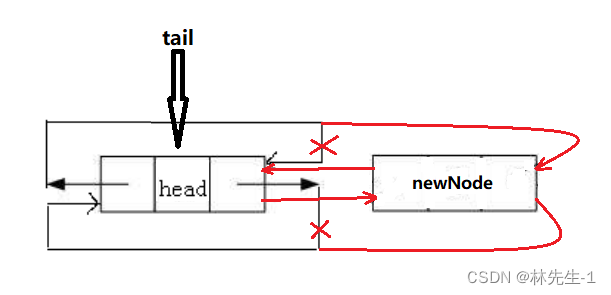
2.2、代码实现
// 双向循环链表的尾插
void double_circle_list_push_back(ListNode* head, data_type x) {
assert(head);
// 先创建新节点
ListNode* newNode = create_newnode(x);
ListNode* tail = head->prev;
// 插入
newNode->prev = tail;
tail->next = newNode;
newNode->next = head;
head->prev = newNode;
}
3、尾删
3.1、图解思路
因为是双向链表,所以我们就可以直接找到tail的前一个节点,所以我们的尾删当然也很简单啦:
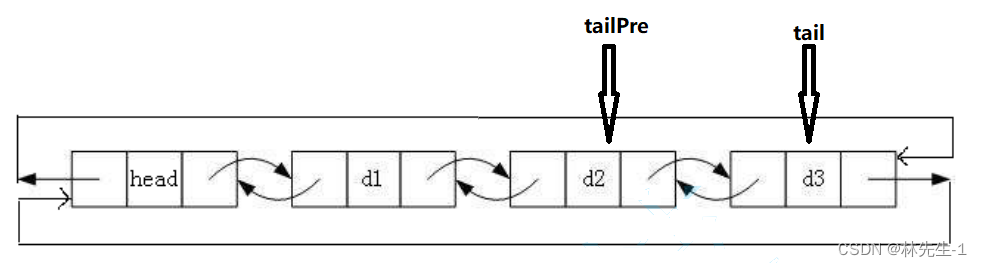
如图,我们可以想让两个指针tail和tailPre分别指向尾节点和尾节点的前一个节点,然后我们可以先释放表tail再修改相应的指针或先修改相应的指针再释放都行,这两个操作的先后顺序不影响结果:
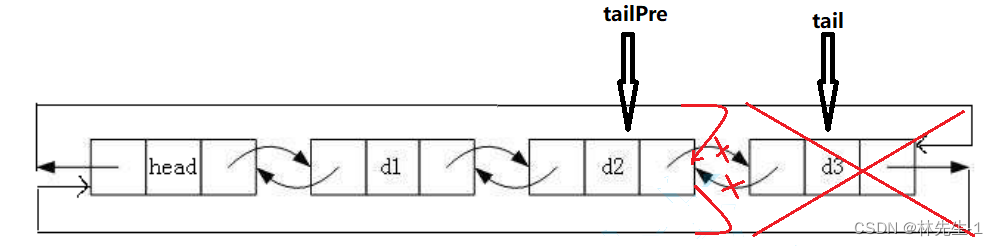
当然我们这里也并不需要考虑链表中只剩一个有小姐点的情况,对于双向循环链表来说这些都是一步到位的。
当然了,我们传入的head是不能为空的,并且也要保证链表中至少有一个有效节点,不能只有一个头节点head,因为不能把head也给删。
3.2、代码实现
// 双向循环链表的尾删
void double_circle_list_pop_back(ListNode *head) {
assert(head);
assert(head->next != head);
ListNode* tail = head->prev;
ListNode* tailpre = tail->prev;
free(tail);
tailpre->next = head;
head->prev = tailpre;
}
4、打印链表
打印其实是和单向链表是一样的,我们从前往后遍历链表中的节点然后又打印出节点信息即可,只不过头节点是不用打印的,所以我们可以直接从head的next开始打印。
而因为循环链表是没有空节点的,所以我们循环结束的条件就不是为空了,但我们可以判断时候回到了头节点head,因为头节点是不用打印的:
// 双向循环链表的打印
void print_double_circle_list(ListNode* head) {
assert(head);
if (head->next == head) {
printf("NULL\n");
return;
}
ListNode* cur = head->next;
printf("[head]∞");
while (cur != head) {
printf("[%d]∞", cur->val);
cur = cur->next;
}
printf("\n");
}
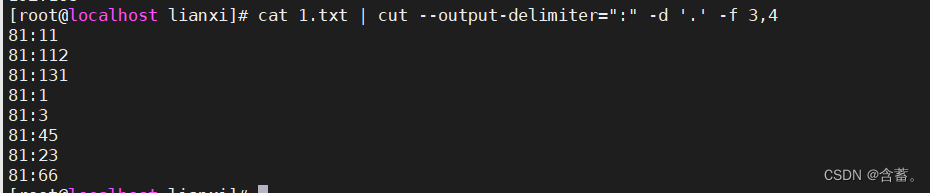
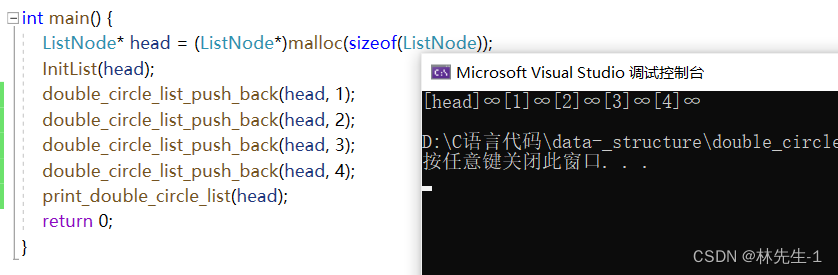
打印效果如下:
5、头插
5.1、图解思路
头插的操作几乎和单链表的相同,只不过多出了个prev指针需要我们处理而已:
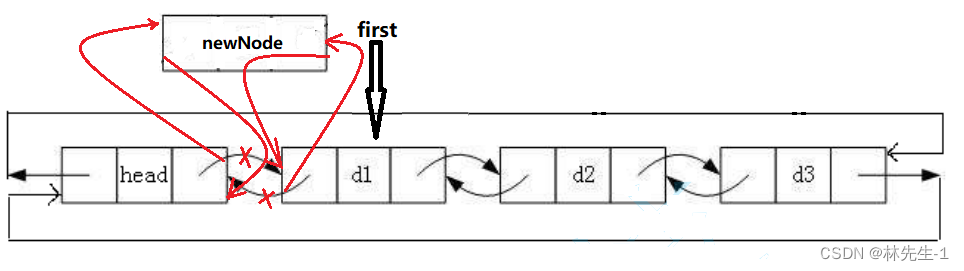
如上如,我们可以先用一个first指针指向第一个节点,然后各个指针的修改顺序就可以随意打乱也不会影响结果了。
当然,只有一个头节点的情况也是不需要特殊考虑的,直接用相同的操作即可。
5.2、代码实现
// 双向循环链表的头插
void double_circle_list_push_front(ListNode* head, data_type x) {
assert(head);
ListNode* newNode = create_newnode(x);
ListNode* first = head->next;
newNode->next = first;
first->prev = newNode;
head->next = newNode;
newNode->prev = head;
}
6、头删
6.1、图解思路
头删其实也是和单链表只差了一个prev指针:
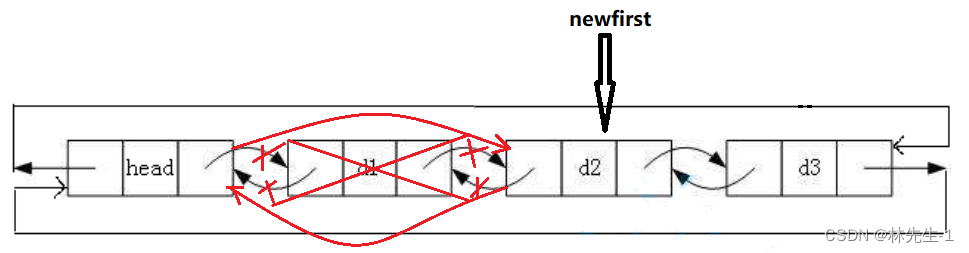
我们可以先将新的第一个节点(第二个节点)用一个newfirst指针先存起来,然后在修改相应的指针指向。
6.2、代码实现
// 双向循环链表的头删
void double_circle_list_pop_front(ListNode* head) {
assert(head );
assert(head->next != head);
ListNode* newfirst = head->next->next; // 新的第一个节点
free(head->next);
head->next = newfirst;
newfirst->prev = head;
}
7、查找
查找那就和单向链表一模一样了,就像打印链表一样从前往后遍历节点,找到只相同的节点直接返回即可:
// 双向循环链表的查找,根据数据域的值查找,返回查找到的节点的指针,若找不到则返回NULL
ListNode* find_Node(ListNode* head, data_type x) {
assert(head && head->next != head);
ListNode* cur = head->next;
while (cur != head) {
if (cur->val == x) {
return cur;
}
cur = cur->next;
}
return NULL;
}
8、随机插入
8.1、图解思路
通过传入目标节点的指针,实现在目标节点的后面插入一个新节点。
这个函数需要配合着上面的查找函数一起使用,先用查找函数找到目标节点,再将目标节点传入插入函数就可以实现随机插入了。
置于插入的思路就不用多说了,基本和尾插头插是一个逻辑。
8.2、代码实现
// 双向循环链表的随机插入,在目标节点的后面插入新节点
void double_circle_list_insert(ListNode* target, data_type x) {
assert(target);
ListNode* newNode = create_newnode(x);
ListNode* next = target->next;
target->next = newNode;
newNode->prev = target;
newNode->next = next;
next->prev = newNode;
}
9、随机删除
9.1、图解思路
通过传入的目标节点,将目标节点从链表中删除。
获取单链表还需要从前往后遍历找到目标节点的前一个节点,但双向链表就不用。
我们直接执行target->prev->next = target->next和target->next->prev = target->prev,然后将在释放掉target即可:
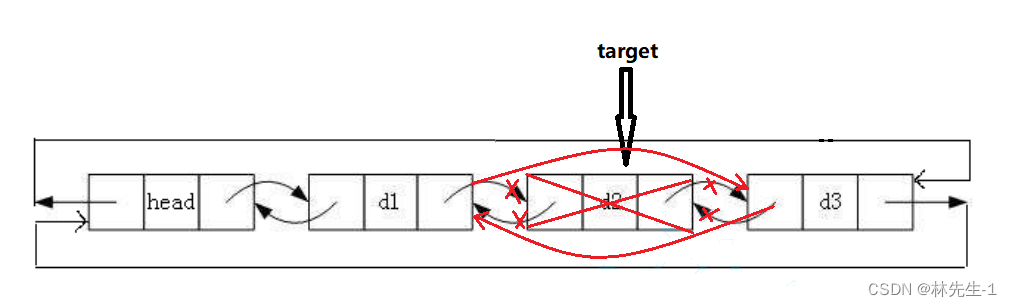
当然了,直接这样操作的话可能会有的朋友会晕,如果觉得晕的话可以多定义两个指针,这样就容易理解一点。
9.2、代码实现
// 双向循环链表的随机删除,从链表中删除目标节点
void double_circle_list_remove(ListNode* target) {
assert(target);
target->prev->next = target->next;
target->next->prev = target->prev;
free(target);
}
10、链表的销毁
销毁也是和单链表的一样的:
// 双向循环链表的销毁
void destroy_double_circle_list(ListNode* head) {
assert(head && head->next != head);
ListNode* cur = head->next;
ListNode* next = cur->next;
while (cur != head) {
next = cur->next;
free(cur);
cur = next;
}
}
这里并没有传入二级指针来达到在函数内销毁头节点,但我们在使用时需要记得最后要连头节点head也销毁了。