一、前言
本系列主要是记录阅读「高性能MySQL」期间笔记,记录在日常使用中忽略的知识、模糊的点,主要面对有一定MySQL使用经验的开发者。
本文是针对于MySQL一些基础定义的解释说明,会非常浅显通俗易懂。
二、MySQL的逻辑架构
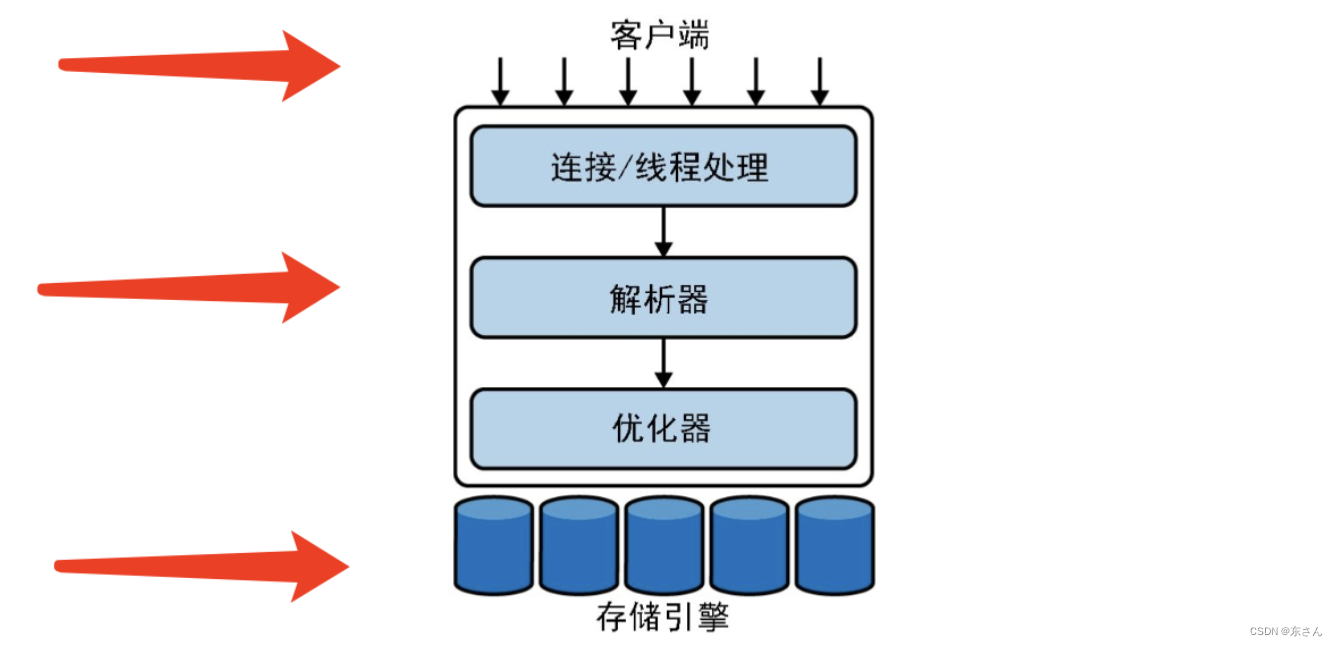
简单梳理MySQL的结构,大致分为三部分。
第一层客户端。包括连接处理、身份验证、确保安全性等。
第二层MySQL的核心功能,包括查询解析、分析、优化、以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能也都在这一层实现:存储过程、触发器、视图等。
第三层是存储引擎层。存储引擎负责MySQL中数据的存储和提取。
三、并发控制
两个级别的并发控制:服务器级别和存储引擎级别。
服务器级别的并发:同时执行的客户端连接数。
存储引擎并发:在MySQL服务器中使用不同类型的存储引擎时,多个连接可以同时访问和修改表数据的能力。每种存储引擎都有不同的并发访问约束和实现方式。例如,InnoDB 存储引擎支持行级锁定和 MVCC 特性来提供高度的并发性能,而 MyISAM 存储引擎则以表级锁定为特征,限制了同时访问同一张表的连接数量。
锁类型
并发的解决方案也是比较简单的,通过加锁处理,有两种锁共享锁(shared lock)和排他锁(exclusive lock),也叫读锁(read lock)和写锁(write lock)。
对同资源来说,读锁之间互不阻塞,互不干扰。写锁是排他的,一个写锁既会阻塞读锁也会阻塞其他的写锁,并防止其他客户端读取正在写入的资源。
当客户端想对表进行写操作(插入、删除、更新等)时,需要先获得一个写锁,这会阻塞其他客户端对该表的所有读写操作。只有没有人执行写操作时,其他读取的客户端才能获得读锁,读锁之间不会相互阻塞。
锁粒度
每种MySQL存储引擎都可以实现自己的锁策略和锁粒度。
锁粒度与并发量:锁粒度越小(锁得更精确)↓ 并发量越高↑
锁粒度与资源消耗量:锁粒度越小(锁得更精确)↓ 资源消耗量越大↑
理论上锁的足够精确,并发量能够达到极致,但这并不能很好的在实际生产中应用,大多都使用的是行级锁(row level lock)。除了行锁外,还有另外一种表锁(table lock)。
四、事务
ACID事务
谈到事务不得不提起ACID事务。ACID代表原子性(atomicity)、一致性(consistency)、隔离性(isolation)和持久性(durability)。
原子性(atomicity)
一个事务必须被视为一个不可分割的工作单元,整个事务中的所有操作要么全部提交成功,要么全部失败回滚。
一致性(consistency)
数据库总是从一个一致性状态转换到下一个一致性状态。一个分为多步骤的操作,即使最后步骤出现了错误,最后事务没有提交,该事务的数据修改也不会保存到数据库中。
隔离性(isolation)
通常来说,一个事务所做的修改在最终提交以前,对其他事务是不可见的,这就是隔离性带来的结果。
持久性(durability)
一旦提交,事务所做的修改就会被永久保存到数据库中。此时即使系统崩溃,数据也不会丢失。
隔离级别
READ UNCOMMITTED(未提交读)
在READ UNCOMMITTED级别,在事务中可以查看其他事务中还没有提交的修改。这个隔离级别会导致很多问题,从性能上来说,READ UNCOMMITTED不会比其他级别好太多,却缺乏其他级别的很多好处,除非有非常必要的理由,在实际应用中一般很少使用。
读取未提交的数据,也称为脏读(dirty read)
READ COMMITTED(提交读)
大多数数据库系统的默认隔离级别是READ COMMITTED(但MySQL不是)。READ COMMITTED满足前面提到的隔离性的简单定义:一个事务可以看到其他事务在它开始之后提交的修改,但在该事务提交之前,其所做的任何修改对其他事务都是不可见的。这个级别仍然允许不可重复读(nonrepeatable read),这意味着同一事务中两次执行相同语句,可能会看到不同的数据结果。
REPEATABLE READ(可重复读)
REPEATABLE READ解决了READ COMMITTED级别的不可重复读问题,保证了在同一个事务中多次读取相同行数据的结果是一样的。但是理论上,可重复读隔离级别还是无法解决另外一个幻读(phantom read)的问题。所谓幻读,指的是当某个事务在读取某个范围内的记录时,另外一个事务又在该范围内插入了新的记录,当之前的事务再次读取该范围的记录时,会产生幻行(phantom row)。InnoDB和XtraDB存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)解决了幻读的问题。本章稍后会对此做进一步讨论。
REPEATABLE READ是MySQL默认的事务隔离级别
SERIALIZABLE(可串行化)
SERIALIZABLE是最高的隔离级别。该级别通过强制事务按序执行,使不同事务之间不可能产生冲突,从而解决了前面说的幻读问题。简单来说,SERIALIZABLE会在读取的每一行数据上都加锁,所以可能导致大量的超时和锁争用的问题。实际应用中很少用到这个隔离级别,除非需要严格确保数据安全且可以接受并发性能下降的结果。
ps:脏读和幻读
脏读(Dirty Read)指一个事务读取到了另一个事务尚未提交的数据,也就是读取了尚未稳定下来的数据。
而幻读(Phantom Read)则是指在一个事务执行期间,某个查询操作返回了满足搜索条件的一组行,但是这些行却因为其他事务的插入或删除操作,使得同样的查询操作返回了不同的结果集,这就好像发生了幻觉一样。
本质区别,脏读描述的是读取到未提交的数据,而幻读描述的是在同一个事务中,前后两次读取同一结果集时返回的结果不同。
| 隔离级别 | 脏读 (Dirty Read) | 幻读 (Phantom Read) |
|---|---|---|
| READ UNCOMMITTED | 可能出现 | 可能出现 |
| READ COMMITTED | 不会出现 | 可能出现 |
| REPEATABLE READ | 不会出现 | 不会出现 |
| SERIALIZABLE | 不会出现 | 不会出现 |
五、死锁
死锁是指两个或多个事务相互持有和请求相同资源上的锁,产生了循环依赖。
六、隐式锁定和显式锁定
InnoDB使用两阶段锁定协议(two-phase locking protocol)。在事务执行期间,随时都可以获取锁,但锁只有在提交或回滚后才会释放,并且所有的锁会同时释放。前面描述的锁定机制都是隐式的。InnoDB会根据隔离级别自动处理锁。
两阶段锁定协议 后续补充
七、多版本并发控制
MVCC
虽说是行级锁,但是并不是简单的行锁,是一种给予MVCC机制的实现方式,MVCC是一个理论机制,不同的数据库进而进行实现。
MVCC的实现方式是为每个数据行(记录)维护一个或多个版本。每个事务读取数据时,将能够看到与其事务启动时间相关的那些版本,而写操作将创建新的版本。这样就可以在多个事务同时读取和修改数据时,保证每个事务读取到的都是自己所需要的版本,从而避免了锁定竞争和阻塞等情况的发生。
InnoDB的实现
InnoDB是通过给每个事务分配一个唯一的编号(即事务ID)来实现MVCC的。这个编号在事务第一次读取数据时就会被分配。当事务修改一条记录时,它会先在Undo日志中写入一条记录,描述如何撤销该修改操作,并且指明回滚该操作的位置。
当不同的用户想读取聚簇主键索引记录时,InnoDB会检查该记录的事务ID和用户所处的读取视图对比,如果该记录不应该在当前状态下可见(即被尚未提交的事务更改过),那么就会查找并应用Undo日志直到找到符合条件的事务ID,或者删除所有与该行有关的Undo记录,然后向用户表明该行不存在。这个过程会一直循环,直至找到满足条件的Undo记录或者没有记录为止,从而保证每个用户都能看到符合自己事务读取时的最新版本的数据。
![![[Pasted image 20230509101151.png]]](https://img-blog.csdnimg.cn/960dc7bdb9fe4fa8ba2fe0dc727adcab.png)
八、InnoDB
提起MySQL不得不说InnoDB。InnoDB是MySQL的默认事务型存储引擎,也是最重要、使用最广泛的引擎。
InnoDB是MySQL默认的通用存储引擎。默认情况下,InnoDB将数据存储在一系列的数据文件中,这些文件统被称为表空间(tablespace)。表空间本质上是一个由InnoDB自己管理的黑盒。
InnoDB使用MVCC来实现高并发性,并实现了所有4个SQL标准隔离级别。InnoDB默认为REPEATABLE READ隔离级别,并且通过间隙锁(next-key locking)策略来防止在这个隔离级别上的幻读:InnoDB不只锁定在查询中涉及的行,还会对索引结构中的间隙进行锁定,以防止幻行被插入。
InnoDB表是基于聚簇索引构建的,聚簇索引提供了非常快速的主键查找。但是,因为二级索引(secondary index,非主键索引)需要包含主键列,如果主键较大,则其他索引也会很大。如果表中的索引较多,主键应当尽量小。
InnoDB内部做了很多优化。其中包括从磁盘预取数据的可预测性预读、能够自动在内存中构建哈希索引以进行快速查找的自适应哈希索引(adaptive hash index),以及用于加速插入操作的插入缓冲区(insert buffer)。我们将在本书第4章讨论这些内容。
九、小结
MySQL拥有分层的架构,上层是服务器级别的服务和查询执行层,下层则是存储引擎。虽然有很多不同作用的插件API,但存储引擎API是最重要的。MySQL通过API来与存储引擎交互需要处理的数据行,理解了这一点,就掌握了MySQL服务器架构的基本原理。
在过去的几个主要版本中,MySQL主要的改进核心在于InnoDB的演进。表元数据、用户认证、身份鉴权这些内部统计信息的管理也已经调整为使用InnoDB表来实现,而在几年前,使用的都是MyISAM引擎。Oracle官方在InnoDB引擎上加大了投入,这使得MySQL有了一些重大改进,例如原子DDL,更完善的online DDL,更强大的崩溃恢复能力,以及更安全的部署操作。
InnoDB是MySQL的默认存储引擎,它几乎能覆盖每一种使用场景。后面的章节我们将重点介绍InnoDB存储引擎,包括它的特性、性能及限制。从现在开始,我们将很少提到InnoDB以外的其他存储引擎了。