大家好,3y啊。好些天没更新了,并没有偷懒,只不过一直在安装环境,差点都想放弃了。
上一次比较大的更新是做了austin的预览地址,把企业微信的应用和机器人消息各种的消息类型和功能给完善了。上一篇文章也提到了,austin常规的功能已经更新得差不多了,剩下的就是各种细节的完善。
不知道大家还记不记得我当时规划austin时,所画出的架构图:

现在就剩下austin-datahouse这个模块没有实现了,也有挺多同学在看代码的时候问过我这个模块在哪…其实就是还没实现,先规划,牛逼先吹出去(互联网人必备技能)
消息推送平台🔥推送下发【邮件】【短信】【微信服务号】【微信小程序】【企业微信】【钉钉】等消息类型。
- https://gitee.com/zhongfucheng/austin/
- https://github.com/ZhongFuCheng3y/austin
至于这个模块吧,我预想它的功能就是把austin相关的实时数据写到数据仓库里。一方面是做数据备份,另一方面是大多数的报表很多都得依赖数据仓库去做。实际上,生产环境也会把相关的数据写到数仓中。
而在公司里,要把数据写到数据仓库,这事对开发来说一般很简单。因为有数仓这个东西,那大多数都会有相关的基础建设了。对于开发而言,可能就是把日志数据写到Kafka,在相关的后台配置下这个topic,就能将这个topic的数据同步到数据仓库里咯。如果是数据库的话,那应该大数据平台有同步数据的功能,对普通开发来说也就配置下表名就能同步到数据仓库里咯。
反正使用起来很简单就是了。不过,我其实不知道具体是怎么做的。
但是不要紧啊,反正开源项目对于时间这块还是很充裕得啊:没有deadline,没有产品在隔壁催我写,没有相关的技术要跟我对接。那我不懂可以学,于是也花了几天看了下数仓这块内容。
在看数仓的同时,我之前在公司经常会听到数据湖这个词。我刚毕业的时候是没听过的,但这几年好像这个概念就火起来了。跟大数据那边聊点事的时候,经常会听到:数据入湖。
那既然看都看了,顺便了解数据湖是个什么东西吧?对着浏览器一轮检索之后,我发现这个词还是挺抽象的,一直没找到让我耳目一新的答案,这个数据湖也不知道怎么就火起来了。我浏览了一遍之后,我大概可以总结出什么是数据湖,跟数据仓库有啥区别:
1、数据仓库是存储结构化的数据,而数据湖是什么数据都能存(非结构化的数据也能存)。结构化数据可以理解为我们的二维表、JSON数据,非结构化的数据可以理解为图像文件之类的。
数据仓库在写入的时候,就要定义好schema了,而数据湖在写入的时候不需要定schema,可以等用到的时候再查出来。强调这点,说明数据湖对数据的schema约束更加灵活。
2、数据仓库和数据湖并不是替代关系。数据是先进数据湖,将数据加工(ETL)之后,一部分数据会到数据仓库中。
3、我们知道现有的数据仓库一般基于Hadoop体系的HDFS分布式文件系统去搭建的,而数据湖也得存储数据的嘛,一般也是依赖HDFS。
4、开源的数据湖技术比较出名的有hudi、iceberg、Delta Lake
看完上面的描述,是不是觉得有点空泛。看似学到了很多,但是实际还是不知道数据湖有啥牛逼之处。嗯,我也是这么想的。总体下来,感觉数据湖就相当于数据仓库的ODS,围绕着这些数据定义了对应的meta信息,做元数据的管理。
说到ODS这个词了,就简单聊下数据仓库的分层结构吧。这个行业通用的,一般分为以下:
1、ODS(Operate Data Store),原始数据层,未经过任何加工的。
2、DIM(Dictionary Data Layer),维度数据层,比如存储地域、用户客户端这些维度的数据。
3、DWD(Data Warehouse Detail),数据明细层,把原始数据经过简单的加工(去除脏数据,空数据之后就得到明细数据)。
4、DWS(Data Warehouse Service),数据维度汇总层,比如将数据明细根据用户维度做汇总得到的汇总之后的数据。
5、ADS(Application Data Store),数据应用层,这部分数据能给到后端以接口的方式给到前端做可视化使用了。
至于为什么要分层,跟当初我们理解DAO/Service/Controller的思想差不多,大概就是复用和便于后续修改变动。
扯了那么多吧,聊会ausitn项目吧,我是打算怎么做的呢?因为我的实时计算austin-stream模块是采用Flink去做的,我打算austin-datahouse也是采用flink去做。
这几年在大数据领域湖仓一体、流批一体这些概念都非常火,而对于austin来说,第一版迭代还不用走得这么急。我目前的想法是利用flink的tableapi去对接Hive,通过Superset、Metabase、DataEase 其中一个开源的大数据可视化工具把Hive的数据给读取出来,那第一版就差不多完成了。
现状
自从我决定开始写austin-data-house数据仓库模块,已经过了两周有多了。这两周多我都在被部署安装环境折磨,中途有很多次就想放弃了。
我初学编程,到现在工作了几年,我还是没变,一如既往地讨厌安装环境。
花了这么长时间调试安装部署环境,实现的功能其实很简单:消费Kafka的消息,写入hive。(我在写全链路追踪功能实时引擎用的是flink,为了技术架构统一,我还是希望通过flink来实现。)
flink从1.9开始支持hive。到目前为止,flink稳定的版本在1.16.0,flink支持hive也就这两年的事。
austin所依赖的组件有很多(正常线上环境都会有这些组件,只是不用我们自己搭建而已)。各种组件的环境问题被我一一征服了,但有很大程度上的功劳是在docker-compose上。
说到数据仓库,第一时间肯定是想到hive。虽然我没装过hadoop/hive/hdfs大数据相关的组件,但稍微想想这都是复杂的。那安装hive自然就会想到有没有docker镜像,一键安装可多爽啊。
之前接入的flink也是跑在docker上的,把hive也找个镜像,两者融合融合不就行了嘛?
想法很好,我就开干了。
基础知识
flink和hive融合,实际上是借助hive catalog来打通hive。hive catalog对接着hive metastore(hive存储元数据的地方)。
当我们使用flink创建出的元数据,会经由hive catalog 最终持久化到hive metastore,同时我们会利用hive catalog提供的接口对hive进行写入和读取。
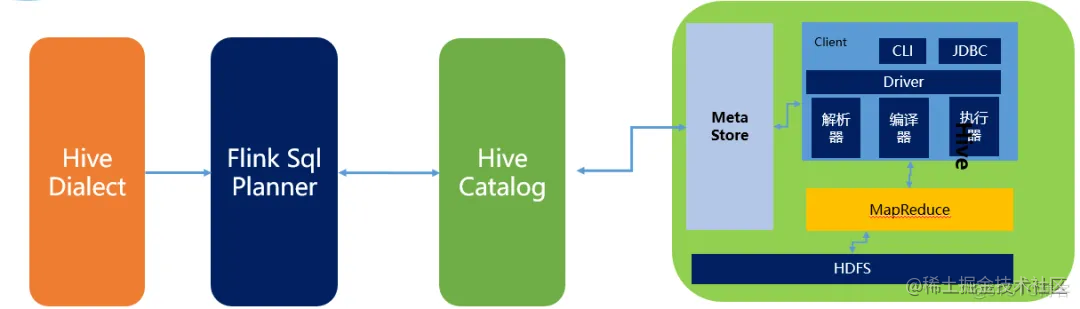
安装hive环境
那时候简单搜了下,还真被我找到了hive的镜像,没想到这么幸运,还是支持docker-compose的,一键安装,美滋滋。
https://github.com/big-data-europe/docker-hive
我就简单复述下过程吧,比较简单:
1、把仓库拉到自己的服务器上
git clone git@github.com:big-data-europe/docker-hive.git
2、进入到项目的文件夹里
cd docker-hive
3、启动项目
docker-compose up -d
一顿下载之后,可以发现就启动成功了,通过docker ps 命令就看到运行几个镜像了。
没错,这就安装好hive了,是不是非常简单。具体启动了什么,我们可以简单看下docker-compose.yml文件的内容。
最后,我们可以连上hive的客户端,感受下快速安装好hive的成功感。
# 进入bash
docker-compose exec hive-server bash
# 使用beeline客户端连接
/opt/hive/bin/beeline -u jdbc:hive2://localhost:10000
深陷迷雾
hive安装好了之后,我就马不停蹄地想知道怎么跟flink进行融合了。我就搜了几篇博客看个大概,后来发现大多数博客的内容其实就是翻译了flink官网的内容。
不过,翻博客的过程中让我大致了解了一点:如果我要使用flink连接hive,那我要手动把flink连接hive的jar包导入到flink/lib目录下。
说实话,这还是比较麻烦的。我还以为只需要在我的工程里导入相关的依赖就好了,没想到还得自己手动把jar包下来下来,然后传入到flink的安装目录下。
我吭哧吭哧地做了,但把我写好的工程jar包传上去提交给jobmanager不是缺这就是少那依赖。我相信我能搞掂,反正就是版本依赖的问题嘛,我在行的。
后面又发现在flink工程项目里用maven引入hadoop依赖是不够的,flink新版本里默认打的镜像是没有hadoop的,要手动在flink环境目录下引入hadoop。这个也是麻烦的,但只要我在镜像里下载些环境,也不是不能干。
1、安装vim
apt-get update
apt-get install vim
2、安装hadoop
2.1、下载hadoop
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
2.2、解压hadoop
tar -zxf hadoop-2.7.4.tar.gz
2.3、配置环境变量
vim /etc/profile
export HADOOP_HOME=/opt/hadoop-2.7.4
export PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
source /etc/profile
2.4、在flink的docker容器里还得把.bashrc也得改了才生效
过于乐观的我,搞了10天左右吧,终于顶不住了,下定决心:我一定要统一版本,不能修修补补了,该什么版本就走什么版本,推倒从来吧。我就按着flink官网来走,一步一步走下来不可能错的吧!
flink最新的版本是v1.17-SNAPSHOT,那我就挑上一个稳定的版本就行了!顺便一看,我之前写全链路追踪austin接入flink的时候,代码的还是14.3版本。但管不了这么多了,就用1.16.0版本吧。
首先,我发现我的flink镜像拉取的是最新的版本image: flink:latest。那我得找1.16.0版本的docker-compose来部署,版本就得统一,后面的事才好搞。这个好找,在官网很快就找到了:image: flink:1.16.0-scala_2.12
新的镜像搞下来了以后,我又吭哧地把相关的jar都手动地导入到flink容器里。另外,我发现官网写的pom依赖,压根就下载不下来的,这不对劲啊。
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.12</artifactId>
<version>1.16.0</version>
<scope>provided</scope>
</dependency>
我开始以为是我的maven仓库配置问题,找遍了仓库在那个artifactId下,最大的也就只有1.14.x的版本。去找了下flink的issue,发现有人跟我一样的问题。
https://github.com/apache/flink/pull/21553
继续尝试提交我自己写好的flink.jar。毫无意外地,又报错了,有些是之前的报错,我很快地就能解决掉。
我一想,意识到是哪里没做好了:hive的版本,hadoop的版本,flink的版本这三者也要约束。那我转头一看,发现之前我从镜像里拉下来hive版本是2.3.2,里面装的hadoop版本是2.7.4。于是,我又统一了这三者的版本。信心很足,感觉一定能成。
再次提交,还是有问题,疯狂Google但就是一直找不到解决方案。能查出来的资料,网上的全都是“原始”安装部署的,就没有通过flink docker镜像跟hive融合的,而且也不是跨机器的(给出来的案例都是在同一台机器上,我是hive部署一台机器上,flink部署在另一台机器上)。
花了几天调试还是解决不掉,怎么搞呢?放弃又不甘心。咋整?继续推倒重来呗。
在使用flink容器调试的过程中我已经发现了:
1、拉下来的docker镜像里的内容,跟官网所描述的jar包是有出入的,有的是要我手动去下载的。但当时我觉得既然版本已经限定了,那应该问题也不大。
2、hadoop环境变量在flink docker 容器下很难调试。每次重新推倒从来的时候,我都得手动配置一次,步骤也繁琐。即便我挂载了相关的jar包和整个目录
3、flink容器内重启和启动集群环境不可控,老是出现奇奇怪怪的问题。
那这一次,我就不用docker-compose部署flink了,直接在centos安装部署flink,继续整。
随着我每一次推倒重来,我就觉得我离成功越来越近越来越近。从环境变量报错缺失CALSS_PATH的问题,已经到了sql的语法的问题,从sql语法的问题到找不到远程地址namenode can't found的问题,从远程地址的问题,到HDFS调用不通的问题。最后,终于调试成功了。
下面就记录我能调试成功的安装过程,各种坑错误异常就不记录了(篇幅问题),这里也吐槽够了。
安装flink环境
1、下载flink压缩包
wget https://dlcdn.apache.org/flink/flink-1.16.0/flink-1.16.0-bin-scala_2.12.tgz
2、解压flink
tar -zxf flink-1.16.0-bin-scala_2.12.tgz
3、修改该目录下的conf下的flink-conf.yaml文件中rest.bind-address配置,不然远程访问不到8081端口,将其改为0.0.0.0
rest.bind-address: 0.0.0.0
4、将flink官网提到连接hive所需要的jar包下载到flink的lib目录下(一共4个)
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-sql-connector-hive-2.3.9_2.12/1.16.0/flink-sql-connector-hive-2.3.9_2.12-1.16.0.jar
wget https://repo.maven.apache.org/maven2/org/apache/hive/hive-exec/2.3.4/hive-exec-2.3.4.jar
wget https://repo.maven.apache.org/maven2/org/apache/flink/flink-connector-hive_2.12/1.16.0/flink-connector-hive_2.12-1.16.0.jar
wget https://repo.maven.apache.org/maven2/org/antlr/antlr-runtime/3.5.2/antlr-runtime-3.5.2.jar
5、按照官网指示把flink-table-planner_2.12-1.16.0.jar和flink-table-planner-loader-1.16.0.jar 这俩个jar包移动其目录;
mv $FLINK_HOME/opt/flink-table-planner_2.12-1.16.0.jar $FLINK_HOME/lib/flink-table-planner_2.12-1.16.0.jar
mv $FLINK_HOME/lib/flink-table-planner-loader-1.16.0.jar $FLINK_HOME/opt/flink-table-planner-loader-1.16.0.jar
6、把后续kafka所需要的依赖也下载到lib目录下
wget https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka/1.16.0/flink-connector-kafka-1.16.0.jar
wget https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/3.3.1/kafka-clients-3.3.1.jar
安装hadoop环境
由于hive的镜像已经锁死了hadoop的版本为2.7.4,所以我这边flink所以来的hadoop也是下载2.7.4版本
1、下载hadoop压缩包
wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.4/hadoop-2.7.4.tar.gz
2、解压hadoop
tar -zxf hadoop-2.7.4.tar.gz
安装jdk11
由于高版本的flink需要jdk 11,所以这边安装下该版本的jdk:
yum install java-11-openjdk.x86_64
yum install java-11-openjdk-devel.x86_64
配置jdk、hadoop的环境变量
这一步为了能让flink在启动的时候,加载到jdk和hadoop的环境。
1、编辑/etc/profile文件
vim /etc/profile
2、文件内容最底下增加以下配置:
JAVA_HOME=/usr/lib/jvm/java-11-openjdk-11.0.17.0.8-2.el7_9.x86_64
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export JAVA_HOME JRE_HOME CLASS_PATH PATH
export HADOOP_HOME=/root/hadoop-2.7.4
export PATH=$HADOOP_HOME/bin:$PATH
export HADOOP_CLASSPATH=`hadoop classpath`
3、让配置文件生效
source /etc/profile
austin数据仓库工程代码
直接上austin仓库地址,文章篇幅就不贴代码了,该写的注释我都写了。
http://gitee.com/zhongfucheng/austin
这个工程代码量非常少,一共就4个核心文件pom.xml/hive-site.xml/AustinHiveBootStrap.java,要使用的时候注意该两处地方即可:
1、com.java3y.austin.datahouse.constants.DataHouseConstant#KAFKA_IP_PORT将这里改成自己的kafka的ip和port
2、hive-site.xml文件全局替换掉hive_ip为自己的hive地址,一共两处
部署工程代码到Flink
我们把jar包上传到服务器,然后使用命令提交jar包给flink执行。也可以打开flink的管理后台,在页面上提交jar包并启动。我这里就选择使用命令的方式来提交,主要因为在外网透出flink的端口,很容器被攻击(我已经重装系统几次了。。)
(flink命令在$FLINK_HOME/bin下)
./start-cluster.sh
./flink run austin-data-house-0.0.1-SNAPSHOT.jar
启动Kafka生产者写入测试数据
启动消费者的命令(将ip和port改为自己服务器所部署的Kafka信息):
$KAFKA_HOME/bin/kafka-console-producer.sh --topic austinTraceLog --broker-list ip:port
输入测试数据:
{"state":"1","businessId":"2","ids":[1,2,3],"logTimestamp":"123123"}
即将成功
到这一步,离胜利就非常近了,但还是有通信的问题:flink无法识别namenode/namenode与datanode之间的通信问题等等。于是我们需要做以下措施:
1、hive在部署的时候,增加datanode/namenode的通信端口,部署hive使用这个docker-compose文件的内容:
version: "3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop2.7.4-java8
volumes:
- namenode:/hadoop/dfs/name
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop-hive.env
ports:
- "50070:50070"
- "9000:9000"
- "8020:8020"
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop2.7.4-java8
volumes:
- datanode:/hadoop/dfs/data
env_file:
- ./hadoop-hive.env
environment:
SERVICE_PRECONDITION: "namenode:50070"
ports:
- "50075:50075"
- "50010:50010"
- "50020:50020"
hive-server:
image: bde2020/hive:2.3.2-postgresql-metastore
env_file:
- ./hadoop-hive.env
environment:
HIVE_CORE_CONF_javax_jdo_option_ConnectionURL: "jdbc:postgresql://hive-metastore/metastore"
SERVICE_PRECONDITION: "hive-metastore:9083"
ports:
- "10000:10000"
hive-metastore:
image: bde2020/hive:2.3.2-postgresql-metastore
env_file:
- ./hadoop-hive.env
command: /opt/hive/bin/hive --service metastore
environment:
SERVICE_PRECONDITION: "namenode:50070 datanode:50075 hive-metastore-postgresql:5432"
ports:
- "9083:9083"
hive-metastore-postgresql:
image: bde2020/hive-metastore-postgresql:2.3.0
ports:
- "5432:5432"
presto-coordinator:
image: shawnzhu/prestodb:0.181
ports:
- "8080:8080"
volumes:
namenode:
datanode:
2、在部署flink服务器上增加hosts,有以下(ip为部署hive的地址):
127.0.0.1 namenode
127.0.0.1 datanode
127.0.0.1 b2a0f0310722
其中 b2a0f0310722是datanode的主机名,该主机名会随着hive的docker而变更,我们可以登录namenode的后台地址找到其主机名。而方法则是在部署hive的地址输入:
http://localhost:50070/dfshealth.html#tab-datanode

3、把工程下的hive-site.xml文件拷贝到$FLINK_HOME/conf下
4、hadoop的配置文件hdfs-site.xml增加以下内容(我的目录在/root/hadoop-2.7.4/etc/hadoop)
<property>
<name>dfs.client.use.datanode.hostname</name>
<value>true</value>
<description>only cofig in clients</description>
</property>
5、启动flink-sql的客户端:
./sql-client.sh
6、在sql客户端下执行以下脚本命令,注:hive-conf-dir要放在$FLINK_HOME/conf下
CREATE CATALOG my_hive WITH (
'type' = 'hive',
'hive-conf-dir' = '/root/flink-1.16.0/conf'
);
use catalog my_hive;
create database austin;
7、重启flink集群
./stop-cluster.sh
./start-cluster.sh
8、重新提交执行flink任务
./flink run austin-data-house-0.0.1-SNAPSHOT.jar
数据可视化
到上面为止,我们已经把数据写入到hive表了,我们是不可能每一次都在命令行窗口里查询hive的数据。一般在公司里都会有可视化平台供我们开发/数仓/数据分析师/运营 去查询hive的数据。
我简单看了几个开源的可视化平台:Superset/Metabase/DataEase。最后选择了Metabase,无他,看着顺眼一些。
部署Metabase很简单,也是使用docker进行安装部署,就两行命令(后续我会将其加入到docker-compose里面)。
docker pull metabase/metabase:latest
docker run -d -p 5001:3000 --name metabase metabase/metabase
完了之后,我们就可以打开5001端口到Metabase的后台了。
我们可以在Metabase的后台添加presto进而连接hive去查询记录。

这个presto服务我们在搭建hive的时候已经一起启动了,所以这里直接使用就好了。
到这一步,我们就可以通过在页面上写sql把消息推送过程中埋点的明细数据查询出来
最后
这数据仓库整个安装环境和调试过程确实折腾人,多次推倒重来(甚至不惜重装系统重来)。还好最后输入Kafka一条消息,在hive表里能看到一条记录,能看到结果之后,折腾或许是值得的。
如果想学Java项目的,强烈推荐我的开源项目消息推送平台Austin(8K stars) ,可以用作毕业设计,可以用作校招,可以看看生产环境是怎么推送消息的。开源项目消息推送平台austin仓库地址:
消息推送平台🔥推送下发【邮件】【短信】【微信服务号】【微信小程序】【企业微信】【钉钉】等消息类型。
- https://gitee.com/zhongfucheng/austin/
- https://github.com/ZhongFuCheng3y/austin
参考资料:
- https://nightlies.apache.org/flink/flink-docs-release-1.16/docs/connectors/table/hive/overview/
- https://blog.51cto.com/u_15105906/5849229
- https://blog.csdn.net/qq_38403590/article/details/126172610


![数学(三) -- LC[1010][1015] 可被 K 整除的最小整数](https://img-blog.csdnimg.cn/1ce920fffbd14c91a1464e6200acc5d3.png#pic_center)