动动发财的小手,点个赞吧!
本文[1]
相关分析是探索两个或多个变量之间关系的最基本和最基础的方法之一。您可能已经在某个时候使用 R 执行过相关分析,它可能看起来像这样:
cor_results <- cor.test(my_data$x, my_data$y,
method = "pearson")
cor_results
输出看起来像:
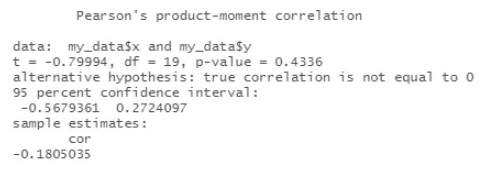
这是为您预先选择的两个变量运行简单关联的基本 R 方法。
但是,如果您真的不知道自己在寻找什么怎么办?如果您只是处于进行一些探索性数据分析的阶段,您可能不知道您对哪些变量感兴趣,或者您可能想在哪里寻找关联。在这种情况下可能有用的是能够选择一个感兴趣的变量,然后检查具有多个甚至数百个变量的数据集,以便为进一步分析找出一个好的起点。感谢 kassambara 开发的 rstatix 包,有一种快速且相对轻松的方法可以做到这一点。
获取数据
例如,我将使用来自世界银行的世界发展指标 (WDI) 数据集的数据——一个关于全球发展指标的开放访问数据存储库。我们可以从上面链接的网站访问 WDI,但也有一个 R 包
install.packages("WDI")
library(WDI)
可以使用 WDI() 函数从 WDI 导入特定的数据系列,但是因为我们对涵盖大量变量之间可能关系的探索性分析感兴趣,所以我将批量下载整个数据库……
bulk <- WDIbulk(timeout = 600)
假设我们有兴趣尝试找出哪些其他国家特征可能与贸易更多的国家相关,相对于其经济规模,我们也对 2020 年的数据感兴趣。
一旦我们确定了正确的变量(这里我将使用贸易占 GDP 的百分比),我们需要稍微清理一下数据。我们将创建一个我们可以过滤的年度系列列表,然后应用另一个过滤步骤以确保我们只使用具有大量观察值的变量用于分析(任意,n> 100在下面的示例中)。
# Create a filtered set with only annual variables
filtered <- bulk$Series %>% filter(Periodicity == "Annual")
# Create a list of variables to correlate against trade levels
bulk$Data %>%
filter(Indicator.Code %in% c(filtered$Series.Code)) %>%
filter(year == 2020) %>%
group_by(Indicator.Code) %>%
filter(!is.na(value)) %>%
count() %>%
arrange(n) %>%
filter(n>100) -> vars_list
分析
所以现在我们有一个变量列表要运行——大约 790 个——看看哪些可能与我们的贸易水平变量相关。这将永远需要手动运行,或者从 base R 循环运行 cor.test() 。这是 rstatix 中的 cor_test() 函数闪耀的地方——它运行得非常快,相关分析的输出被转储到一个小标题中格式(使执行额外的操作和分析变得容易),并且函数是管道友好的,这意味着我们可以将过滤、变异和执行步骤组合到一个管道框架中,我们还可以将变量输入分组以进行分组输出来自 rstatix(我们稍后会看一些例子)。
因此,要运行分析:
# Because WDI contains regional data as well, we'll create a list that only has country codes, and filter our input based on that list
countries <- bulk$Country %>% filter(!Region == "") %>% as_tibble()
bulk$Data %>%
filter(Indicator.Code %in% c(vars_list$Indicator.Code)) %>%
filter(year == 2020) %>%
filter(Country.Code %in% c(countries$Country.Code)) %>%
select(-Indicator.Name) %>%
pivot_wider(names_from = Indicator.Code,
values_from = value) %>%
cor_test(NE.TRD.GNFS.ZS,
method = "pearson",
use = "complete.obs") -> results
results
这会使用变量配对、相关系数 (r)、t 统计量、置信水平 (p) 以及低置信度和高置信度估计来填充整齐的小标题。对于上面运行的示例,它看起来像:
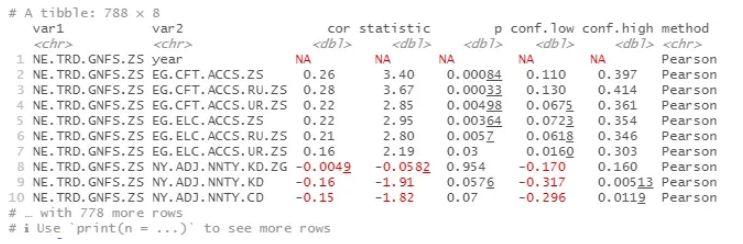
因为输出是一个 tibble,所以我们可以根据需要对其进行排序和分解。让我们用变量名称和描述创建一个键,将其连接到我们的输出数据中,仅过滤在 p > 0.05 水平上显着的变量对,并检查哪些变量具有最高的 r 值:
indicator_explanation <- bulk$Series %>% select(Series.Code, Indicator.Name, Short.definition) %>% as_tibble()
results %>%
left_join(indicator_explanation, c("var2" = "Series.Code")) %>%
arrange(desc(cor)) %>%
filter(p<0.05) %>%
View()
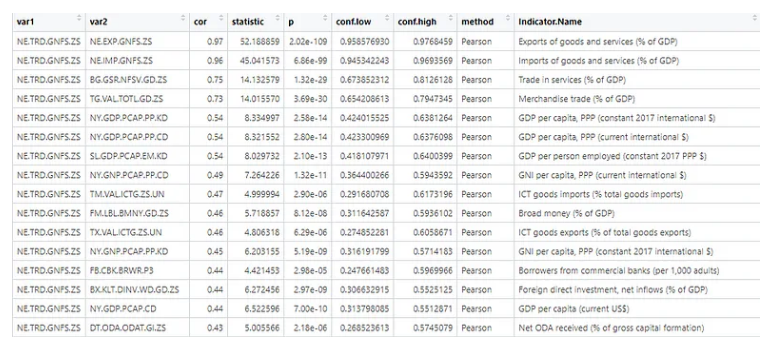
一些具有最高相关性的变量并不令人惊讶——例如,总体贸易在服务贸易和商品贸易的国家之间呈高水平正相关。其他情况可能更出乎意料——比如贸易水平与一个国家收到的官方发展援助(援助资金)数额之间的中等高度正相关 (r = 0.43)(上图中最下面一行)。
分组分析
那么,如果我们想更多地研究这种关系呢?例如——如果我们看看 2020 年以外的其他年份,这种关系是否仍然牢固?这是 cor_test() 的管道友好特性再次派上用场的地方。
让我们过滤我们的初始数据以仅包括我们感兴趣的两个指标,然后按年份对数据进行分组,然后再将其传输到 cor_test() 这一次:
bulk$Data %>%
filter(Indicator.Code %in% c("NE.TRD.GNFS.ZS", "DT.ODA.ODAT.GI.ZS")) %>%
filter(Country.Code %in% c(countries$Country.Code)) %>%
select(-Indicator.Name) %>%
filter(year<2021) %>%
pivot_wider(names_from = Indicator.Code,
values_from = value) %>%
group_by(year) %>%
cor_test(NE.TRD.GNFS.ZS, DT.ODA.ODAT.GI.ZS,
method = "pearson",
use = "complete.obs") -> results_time
这将为我们提供关于两个变量之间相关性的输出,每年都有观察结果(我将数据过滤到 2021 年之前的年份,因为 ODA 数据只运行到 2020 年)。而且由于相关数据以整齐的方式存储,我们可以轻松地运行额外的代码来可视化我们的结果:
results_time %>%
mutate(`Significant?` = if_else(p<0.05, "Yes", "No")) %>%
ggplot(aes(x = year, y = cor)) +
geom_hline(yintercept = 0,
linetype = "dashed") +
geom_line() +
ylab("cor (r)") +
geom_point(aes(color = `Significant?`)) +
theme_minimal()
在这里我们可以看到,从历史上看,这两个变量之间根本没有太大的关系(除了偶尔出现了弱负相关的几年),但在过去几年中,相关性趋于显着和正:
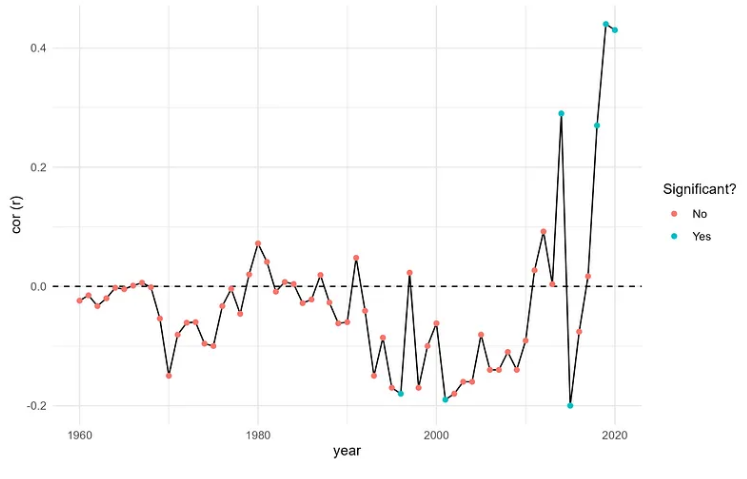
那么这是什么意思?关于贸易与援助之间关系的任何潜在问题——我们必须做更多的研究。相关性毕竟并不意味着因果关系,但这是一个很好的假设生成器——受援国是否越来越以贸易为导向?还是援助交付模式正在转向有利于贸易更多的国家?这些都是我们探索的新途径。这些类型的快速相关分析对于趋势分析或信号发现之类的事情来说可能是一个非常有用的工具——并且采用一种对 tidyverse 友好的方式来做它真的可以避免潜在的麻烦。
就我们快速轻松地进行一些有用的探索性分析的能力而言,我们可以看到 rstatix 是一个有用的配套包。然而,rstatix 中的 cor_test() 有一些缺点
-
例如,与“相关”包中的许多其他方法相比,您仅限于 Pearson (r)、Spearman (ρ) 和 Kendall (τ) 相关方法。然而,这些对于临时用户来说是最常见的,对于基本分析来说应该绰绰有余。 -
置信区间仅在 Pearson r 的输出中报告。这意味着如果 Spearman 的 rho 或 Kendall 的 tau 需要置信区间,则需要额外的代码。 -
例如,不报告样本大小和自由度,如果用户的目标是根据不同的分组段开发多个输出报告,这可能会很烦人。
但这些通常不适用于临时用户。此外,除了 cor_test() 之外,rstatix 还具有用于各种其他统计测试和过程的大量其他函数,下次您需要进行一些探索性统计分析时,这些绝对值得研究——因此请向开发人员大声疾呼一。
Reference
Source: https://towardsdatascience.com/exploratory-correlational-analysis-in-r-c99449b2e3f8
本文由 mdnice 多平台发布