从入门到精通:网络爬虫开发总结
- 专栏:Python网络爬虫
- 1.认识网络爬虫
- 2.网络爬虫——HTML页面组成
- 3.网络爬虫——Requests模块get请求与实战
- 4.网络爬虫—Post请求(实战演示)
- 5.网络爬虫——Xpath解析
- 6.网络爬虫——BeautifulSoup详讲与实战
- 7.网络爬虫—正则表达式详讲
- 8.网络爬虫—正则表达式RE实战
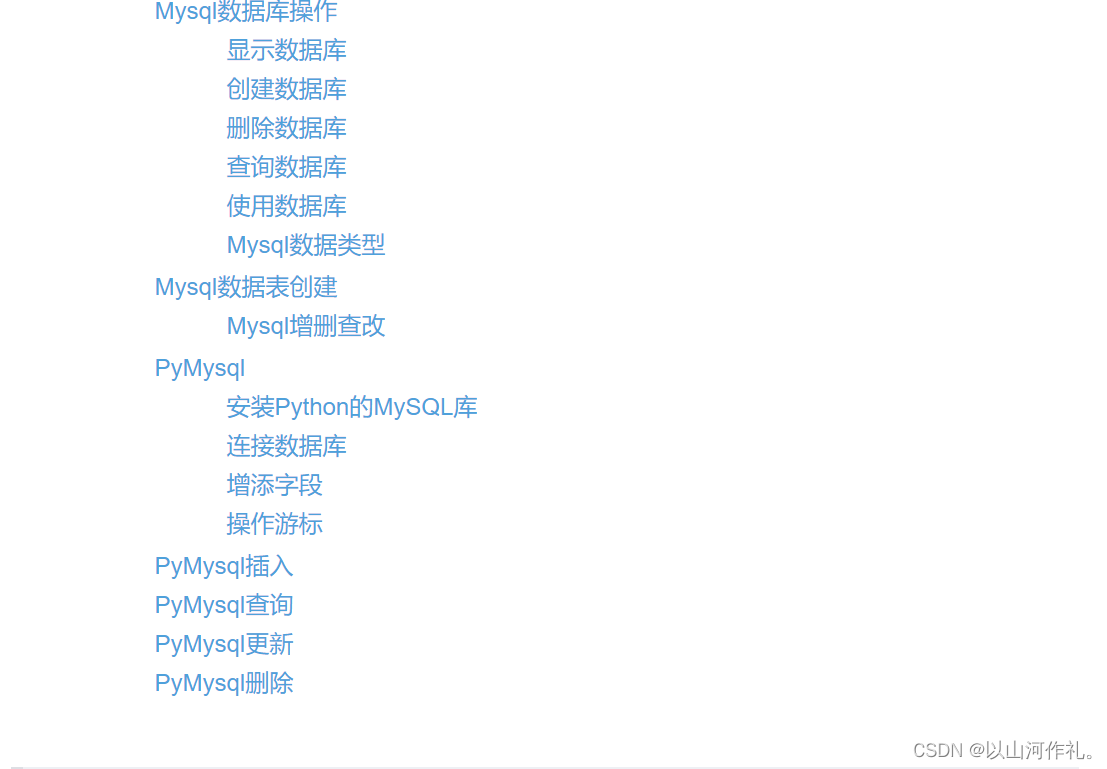
- 9.网络爬虫—MySQL基础
- 10.网络爬虫—MongoDB详讲与实战
- 11.网络爬虫—多线程详讲与实战
- 12.网络爬虫—线程队列详讲(实战演示)
- 13.网络爬虫—多进程详讲(实战演示)
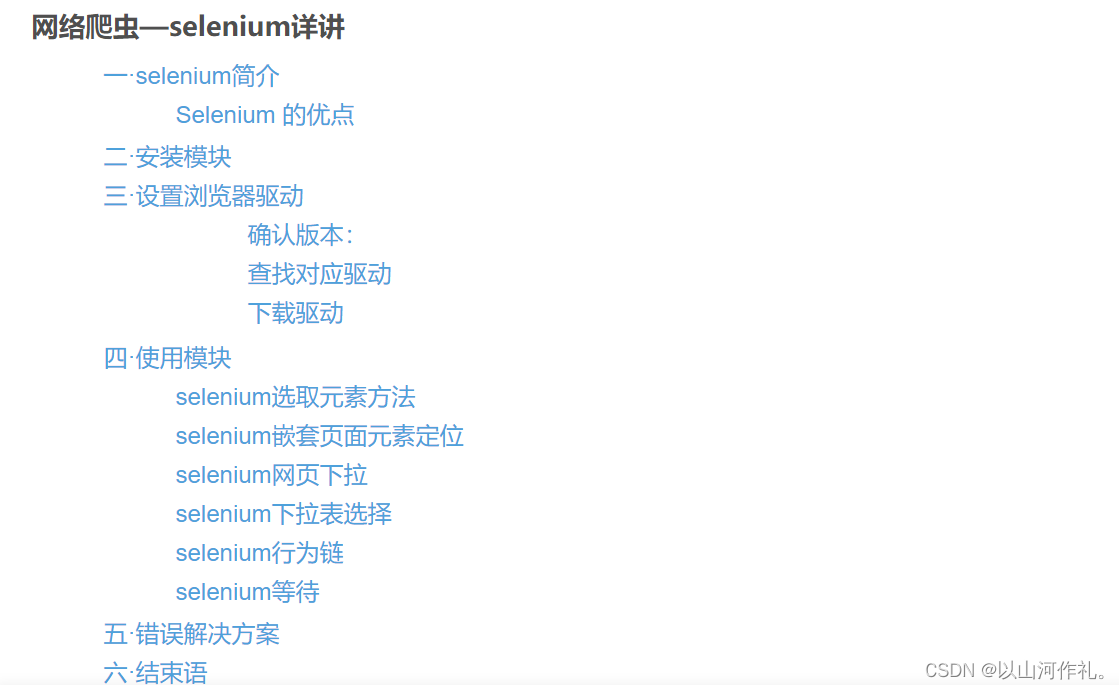
- 14.网络爬虫—selenium详讲
- 15.网络爬虫—selenium验证码破解
- 16.网络爬虫—字体反爬(实战演示)
- 17.网络爬虫—Scrapy入门与实战
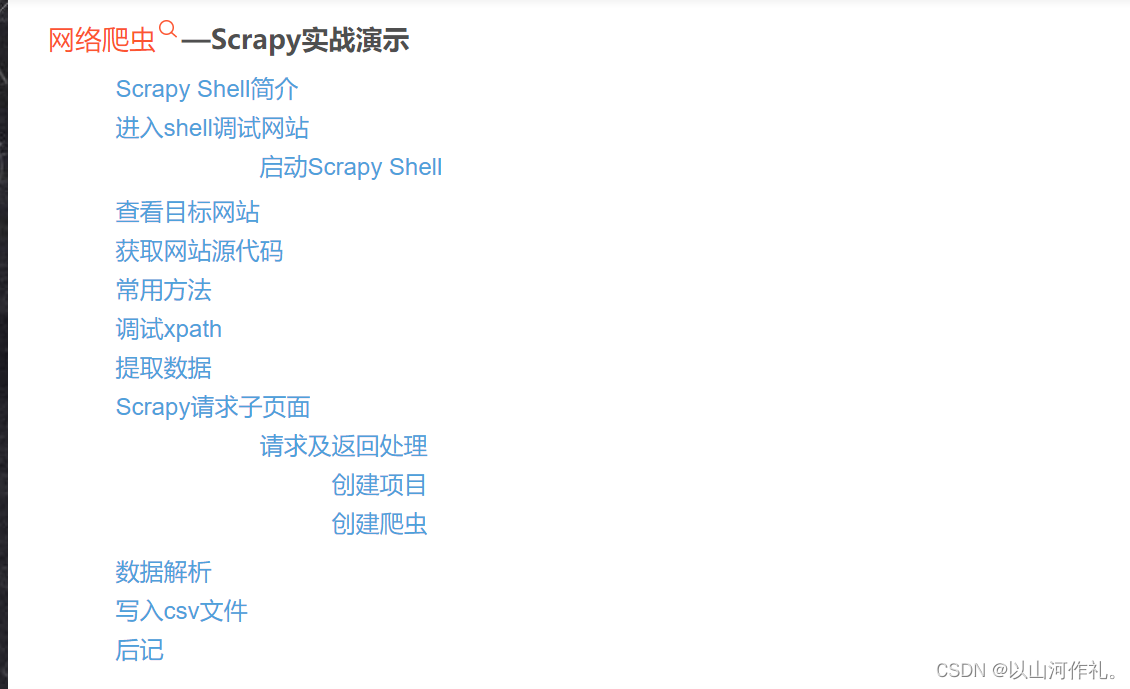
- 18.网络爬虫—Scrapy实战演示
- 19.网络爬虫—照片管道
- 20.网络爬虫—Scrapy-Redis分布式爬虫
- 21.网络爬虫—js逆向详讲与实战
- 22.网络爬虫—APP数据抓取详讲
- 后记
🏘️🏘️个人简介:以山河作礼。
🎖️🎖️:Python领域新星创作者,CSDN实力新星认证,阿里云社区专家博主
- 从写第一篇爬虫文章距今已经过了65天,累计发布爬虫相关文章22篇,累计上榜11篇,质量分均分91,每一篇文章我都认认真真写下来。
📝📝第一篇文章《1.认识网络爬虫》获得
全站热榜第一,python领域热榜第一。
🧾 🧾第四篇文章《4.网络爬虫—Post请求(实战演示)》全站热榜第八。
🧾 🧾第八篇文章《8.网络爬虫—正则表达式RE实战》全站热榜第十二。
🧾 🧾第十篇文章《10.网络爬虫—MongoDB详讲与实战》全站热榜第八领域热榜第二
🧾 🧾第十三篇文章《13.网络爬虫—多进程详讲(实战演示)》全站热榜第十二。
🧾 🧾第十四篇文章《14.网络爬虫—selenium详讲》测试领域热榜第二十。
🧾 🧾第十六篇文章《16.网络爬虫—字体反爬(实战演示)》全站热榜第二十五。
🧾 🧾第十九篇文章《19.网络爬虫—照片管道》全站综合热榜第十二。
🧾 🧾第二十篇文章《20.网络爬虫—Scrapy-Redis分布式爬虫》全站综合热榜第二十五名,大数据领域第六名。
🧾 🧾第二十一篇文章《21.网络爬虫—js逆向详讲与实战》,全站综合热榜第二十二。
🧾 🧾第二十二篇文章《22.网络爬虫—APP数据抓取详讲》,全站综合热榜第二十七
-
🌌学习是一种持续不断的过程,无论在什么领域,都需要不断地努力和探索。在这段爬虫学习历程中,我不仅获得了丰富的知识和技能,也结交了很多志同道合的朋友和粉丝,他们对我的学习和进步都提供了极大的支持和鼓励,支持我继续写下去。
-
🌌总的来说,这段时间的学习和写作让我认识到了自己的不足和缺陷,也让我更加坚定了继续学习和进步的决心。我相信,在未来的学习和工作中,这段经历将成为我前行的动力和支撑。在这里,我将过去写过的爬虫文章总结一下,不仅是在爬虫学习这里留下一个里程碑,也是为了能够总结一下阶段性学习成果。
专栏:Python网络爬虫
专栏:Python网络爬虫
本专栏文章属于免费阅读,累计发表文章22篇,文章累计阅读量8万+,收藏量2千+,喜欢的朋友可以来学习学习。
1.认识网络爬虫
1.认识网络爬虫

⛱️在本章我们认识了什么是网络爬虫,了解了网络爬虫的合法性与http协议,学会了请求与响应。这篇文章是我爬虫的起点,也有很多人给我鼓励与支持,很感谢大家!!
2.网络爬虫——HTML页面组成
2.网络爬虫——HTML页面组成

⛱️在学习爬虫前,我们还需要了解HTML页面,学习它的组成部分以及各部分的意思和使用方法,代码我放在最后,需要自取。学习html,是为了后面爬虫做铺垫,因为我们需要解析页面数据,知己知彼方便百战百胜!
3.网络爬虫——Requests模块get请求与实战
3.网络爬虫——Requests模块get请求与实战

⛱️前两章我们介绍了爬虫和HTML的组成,方便我们后续爬虫学习,今天就教大家怎么去爬取一个网站的源代码(后面学习中就能从源码中找到我们想要的数据)。
4.网络爬虫—Post请求(实战演示)
4.网络爬虫—Post请求(实战演示)

- Python中的POST请求是HTTP协议中的一种请求方法,用于向服务器提交数据。与GET请求不同,POST请求将数据封装在请求体中,而不是在URL中传递。通常情况下,POST请求用于向服务器提交表单数据、上传文件等操作。
- GET请求也是HTTP协议中的一种请求方法,用于向服务器请求数据。与POST请求不同,GET请求将数据以查询字符串的形式附加在URL后面,而不是封装在请求体中。通常情况下,GET请求用于向服务器请求某个资源,比如获取网页、图片、视频等。
5.网络爬虫——Xpath解析
5.网络爬虫——Xpath解析

- XPath是一种用于在XML文档中定位节点的语言,它可以用于从XML文档中提取数据,以及在XML文档中进行搜索和过滤操作。它是W3C标准的一部分,被广泛应用于XML文档的处理和分析。
- XPath使用路径表达式来描述节点的位置,这些路径表达式类似于文件系统中的路径。路径表达式由一个或多个步骤(step)组成,每个步骤描述了一个节点或一组节点。步骤可以使用关系运算符(如/和//)来连接,以便描述更复杂的节点位置。
6.网络爬虫——BeautifulSoup详讲与实战
6.网络爬虫——BeautifulSoup详讲与实战

- Beautiful Soup 简称 BS4(其中 4
表示版本号)BeautifulSoup是一个Python库,用于从HTML和XML文件中提取数据。它提供了一些简单的方式来遍历文档树和搜索文档树中的特定元素。 - BeautifulSoup可以解析HTML和XML文档,并将其转换为Python对象,使得我们可以使用Python的操作来进行数据提取和处理。它还可以处理不完整或有误的标记,并使得标记更加容易阅读。
BeautifulSoup是一个流行的Web爬虫工具,被广泛应用于数据抓取、数据清洗和数据分析等领域。
7.网络爬虫—正则表达式详讲
7.网络爬虫—正则表达式详讲

⛱️Python 正则表达式是一种用于匹配、搜索、替换文本中模式的工具。它使用特定的语法来描述一些规则,这些规则可以用于匹配文本中的某些模式。通过使用正则表达式,可以快速地搜索和处理大量的文本数据,从而节省时间和精力。
8.网络爬虫—正则表达式RE实战
8.网络爬虫—正则表达式RE实战

⛱️正则表达式(Regular Expression)是一种用于匹配字符串的工具,它可以根据特定的规则来匹配字符串。正则表达式通常由一组字符和字符集合组成,其中字符集合定义了匹配的字符类型和位置。
9.网络爬虫—MySQL基础
9.网络爬虫—MySQL基础
- 网络爬虫是一个数据获取技术,可以通过自动化程序从互联网上收集有用的信息。MySQL是一种关系型数据库管理系统,也是许多Web应用程序的首选数据库。
- 在使用网络爬虫时,将数据存储到数据库中是很常见的做法。MySQL是一种流行的选择,因为它易于安装和使用,并且在处理大量数据时具有良好的性能。
10.网络爬虫—MongoDB详讲与实战
10.网络爬虫—MongoDB详讲与实战

⛱️MongoDB是一种开源的文档型数据库管理系统,采用分布式文件存储方式,可以存储非结构化的数据,如文档和键值对等。
它的特点是高性能、高可扩展性、高可用性和易于使用,可以支持复杂的查询和数据分析,同时还提供了数据复制、故障转移和自动分片等功能,可以应用于多种场景,如Web应用、大数据、物联网等。
MongoDB使用BSON(Binary JSON)格式来存储数据,支持多种编程语言的驱动程序,如Java、Python、Ruby、PHP等。
11.网络爬虫—多线程详讲与实战
11.网络爬虫—多线程详讲与实战

-
程序是一系列指令或代码的集合,用于指导计算机执行特定的任务或操作。
程序可以是计算机程序、应用程序、脚本程序等,可以用不同的编程语言编写。程序通过计算机的处理和执行,实现了人类所需要的各种功能和应用。
线程是进程中的一个执行单元,是计算机执行程序时的最小单位。
一个进程可以包含多个线程,每个线程都有自己的执行路径、堆栈和局部变量等。
不同的线程可以同时执行不同的任务,共享进程的资源,提高计算机的效率和性能。
线程可以被操作系统调度和管理,也可以通过同步机制来协调各自的执行。
线程的优点是可以充分利用多核处理器的并行性,提高程序的响应速度和并发处理能力。
12.网络爬虫—线程队列详讲(实战演示)
12.网络爬虫—线程队列详讲(实战演示)

上一章节我们讲解了多线程,我们来大致回顾一下,如有疑问,可以阅读之前文章《网络爬虫—多线程详讲与实战》帮助理解。
- Python 线程是轻量级执行单元,它允许程序同时运行多个线程,每个线程执行不同的任务。
Python 的线程有两种实现方式:
使用 threading 模块或使用 _thread 模块。
使用 threading 模块创建线程:
- 导入 threading 模块
- 定义一个函数作为线程的执行体
- 创建一个线程对象,将函数作为参数传入
- 调用 start() 方法启动线程
13.网络爬虫—多进程详讲(实战演示)
13.网络爬虫—多进程详讲(实战演示)

⛱️进程是指计算机中正在执行的程序实例,它是操作系统进行资源分配和调度的基本单位。
进程可以包含多个线程,每个线程负责执行不同的任务。
进程之间相互独立,拥有独立的内存空间和资源,通过进程间通信来实现数据共享和协作。
进程可以在计算机系统中运行多个,操作系统根据优先级和资源需求来调度进程的执行,以保证系统的稳定性和性能。
14.网络爬虫—selenium详讲
14.网络爬虫—selenium详讲
Selenium是一个自动化测试工具,用于测试Web应用程序。它可以模拟用户在Web浏览器中的操作,如点击链接、填写表单、提交表单等。
- Selenium的主要特点是灵活性和可扩展性,它可以与其他工具和框架集成,如
JUnit、TestNG、Maven、Ant等。 - Selenium的核心组件包括
Selenium IDE、Selenium WebDriver和Selenium Grid。 - Selenium IDE是一个浏览器插件,用于录制和回放测试脚本`;
- Selenium WebDriver是一个自动化测试框架,
用于编写和执行测试脚本 - Selenium Grid是一个分布式测试框架,
用于在多台计算机上并行执行测试脚本。 - Selenium在Web应用程序测试领域具有广泛的应用和影响力。
15.网络爬虫—selenium验证码破解
15.网络爬虫—selenium验证码破解

- 网络爬虫是一种自动化程序,用于从Web页面中提取数据。然而,有些网站为了防止爬虫程序抓取数据,会加入一些验证码,使得程序无法自动化地完成数据采集任务。为了解决这个问题,我们可以使用selenium来破解验证码。
- Selenium是一个开源的自动化测试工具,它可以模拟用户在浏览器中的操作,包括点击、输入等。使用selenium可以模拟用户手动输入验证码,从而实现验证码的破解。
16.网络爬虫—字体反爬(实战演示)
16.网络爬虫—字体反爬(实战演示)

⛱️ Python字体反爬原理是指爬虫在爬取网站数据时,遇到了基于字体反爬的防护措施。这种反爬措施是通过将网站的文字转换成特定的字体文件,然后在页面上引用该字体文件来显示文字,使得爬虫无法直接获取文字内容。
17.网络爬虫—Scrapy入门与实战
17.网络爬虫—Scrapy入门与实战

- Scrapy是一个用于爬取网站数据和提取结构化数据的Python应用程序框架。Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。
- Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
18.网络爬虫—Scrapy实战演示
18.网络爬虫—Scrapy实战演示
- Scrapy是一个开源的Python框架,用于快速、高效地爬取网站数据。Scrapy提供了一组功能强大的工具和组件,使开发人员可以轻松地从网站上提取所需的数据。
- Scrapy Shell是一个命令行工具,可以让开发人员交互式地调试和探索网站。使用Scrapy
Shell,开发人员可以轻松地测试Web爬虫并查看网站上的数据。
19.网络爬虫—照片管道
19.网络爬虫—照片管道

- Scrapy是一个用于爬取网站数据和提取结构化数据的Python应用程序框架。Scrapy的设计是用于Web爬虫,也可以用于提取数据和自动化测试。
- Scrapy提供了一个内置的HTTP请求处理器,可以通过编写自定义的中间件来扩展其功能。Scrapy使用Twisted事件驱动框架,可以同时处理数千个并发请求。
20.网络爬虫—Scrapy-Redis分布式爬虫
20.网络爬虫—Scrapy-Redis分布式爬虫

⛱️Redis是一款高性能的内存数据结构存储系统,支持多种数据结构,如字符串、哈希、列表、集合等,同时还提供了丰富的操作命令和过期时间设置等功能。在分布式爬虫中,Redis可以用作任务队列和数据存储等方面的支持。
21.网络爬虫—js逆向详讲与实战
21.网络爬虫—js逆向详讲与实战

- 在这个大数据时代,我们眼睛所看到的百分之九十的数据都是通过页面呈现出现的,不论是PC端、网页端还是移动端,数据渲染还是基于html/h5+javascript进行的,而大多数的数据都是通过请求后台接口动态渲染的。而想成功的请求成功互联网上的开放/公开接口,必须知道它的URL、Headers、Params、Body等数据是如何生成的。
22.网络爬虫—APP数据抓取详讲
22.网络爬虫—APP数据抓取详讲

- Fiddler是一款免费的Web调试代理工具,也是目前最常用的“HTTP”抓包工具之一,它可以截取HTTP/HTTPS流量并且允许你查看、分析和修改这个流量。Fiddler在Web开发和测试中非常有用,因为它可以帮助你检查Web应用程序的性能、调试网络问题和安全漏洞。它还提供了一个可扩展的架构,使得它可以通过插件支持其他功能。Fiddler可用于Windows
、macOS 和Linux等多种操作系统。
后记
在这里,我想分享一段话:
一位读者写给史铁生的《想念史铁生》中:“我非常喜欢的一个东西,是一个人十三四岁的夏天,在路上捡到一支真枪。因为无知,天不怕地不怕,他扣下扳机,没有人死,也没有人受伤。他认为自己开了空枪。后来他三十岁或者更老,走在路上听到背后有隐隐约约的风声。他停下来转过身去,子弹正中眉心。
我们在人生旅途中所做的错误决定和爱错的人会像一把枪一样插进我们心中,伴随着我们走过时间长河。这些错误决定和人们的过失,会在多年之后才被我们发现,而我们也会意识到这些错误已经杀死了当时的自己。无论我们如何选择,都会留下遗憾,就像是一个永无止境的选择题。或许在未来,我们会面对年少的自己,用手中的枪击杀此时此刻的自己。
然而,人生中并非所有的选择都会带来后悔,有些选择会给我们带来无尽的欢乐和收获。因此,在做出决定前,我们需要深思熟虑,考虑到自己和他人的利益,以免留下不可挽回的遗憾。即使我们曾犯下错误,也要勇敢地面对它们,并从中吸取教训,不断成长和进步。毕竟,一个人的成长历程就像一艘船在海上航行,需要经历风雨和波涛才能到达彼岸,我们需要勇往直前,不断前行!!