大家好,我是 Jack。
OpenAI 又有新动作了,开源发布 Shap-E。
今天,我继续手把手教学。
算法原理、环境搭建、效果测试,一条龙服务,尽在下文!
一、Shap-E 效果
Shap-E 算法的功能,简单来讲就是根据一段文字描述,生成对应的 3D 模型,一起看几组效果。
输入文字:
A chair that looks like an avocado
(翻译:一把看起来像鳄梨的椅子。)
Shap-E 输出对应的 3D 模型:

输入文字:
A spaceship
(翻译:一艘太空船)
Shap-E 输出对应的 3D 模型:

输入文字:
An airplane that looks like a banana
(翻译:一架酷似香蕉的飞机)

更多生成效果:

目前 OpenAI 已经开源了 Shap-E 的代码。
二、算法原理
Shap-E 还是用到了潜空间扩散模型(Latent Diffusion)。
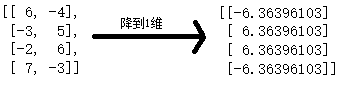
熟悉 Stable Diffusion 的小伙伴应该对于这个概念并不陌生,其实就是将一些高维信息,降维表示到一个特定的特征空间,然后再根据这些特征,做生成。
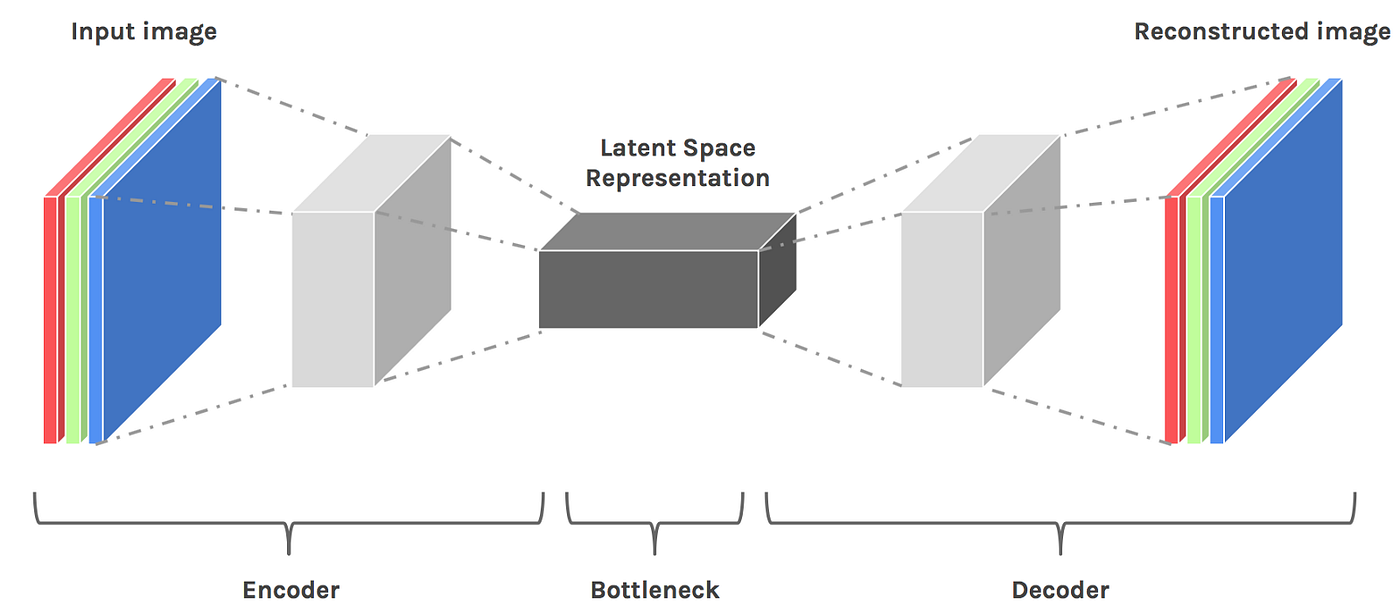
Shap-E 整体结构也是类似的 Encoder - Decoder 结构。
不过输入和输出变了,比如 Shap-E 的 Encoder 结构是这样的:
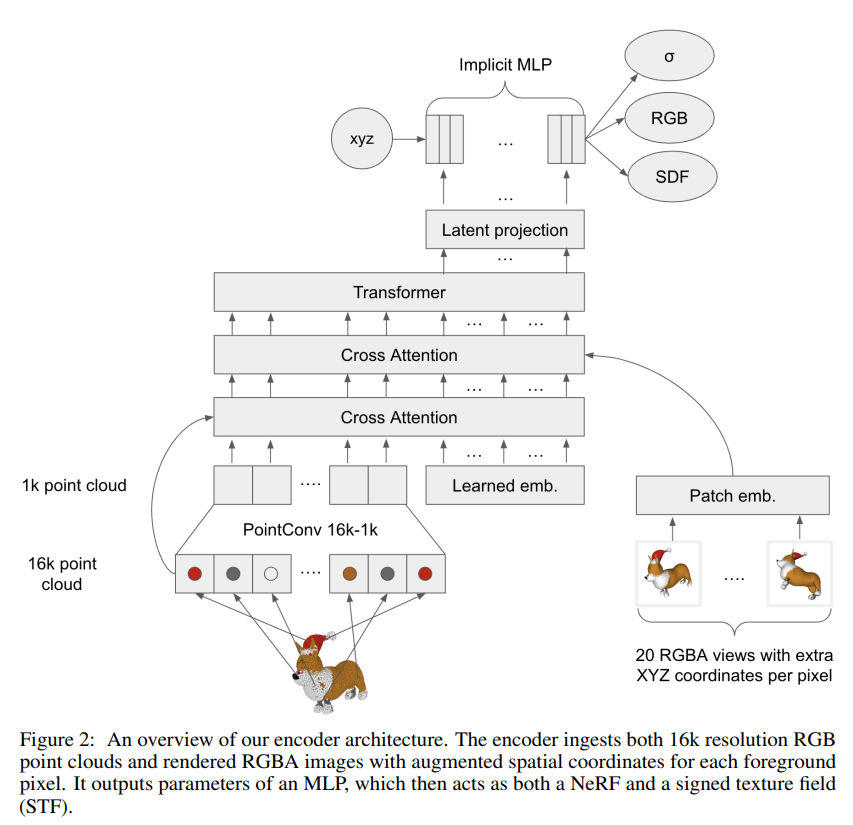
输入是点云模型,经过降维、交叉注意力层、Transformer等结构,最终获得一个 implicit MLP。
至于 Decoder 则采用 STF Rendering 进行渲染,同时加入了 CLIP 的 text embedding。
Shap-E 支持多模态,输入既可以是文字,也可以图片。
三、算法部署

项目地址:
https://github.com/openai/shap-e
算法部署并不复杂,Shap-E 只依赖于 CLIP。
可以单独创建一个名为 shape 的虚拟环境。
conda create -n shape python=3
conda activate shape
然后安装好 CLIP 的一些依赖。
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
pip install ftfy regex tqdm
进入 Shap-E 项目的根目录,直接 pip 安装即可。
pip install -e .
pip 会根据 setup.py 进行安装。
我网速不太给力,本地搭建环境,大概花费了 1 个小时。

shap_e/examples/sample_text_to_3d.ipynb 是 text 生成 3D 模型的代码。
shap_e/examples/sample_image_to_3d.ipynb 是图片生成 3D 模型的代码。
在 A10 机器上,生成一次 3D 模型,大概需要花费 25 秒。
四、最后
当然,因为数据集等方面的原因,有些 3D 模型生成的效果还是挺差的。
比如我测试了A dog,得到了这么一个东西:

我输入A cat,得到了:

通过图片,生成 3D 模型,对于图片的要求很高,必须是白色背景的图片,效果才可以,或者干脆是透明背景。
在 Huggingface 也有人搭建了这个服务,非官方项目,但使用的是官方代码:
https://huggingface.co/spaces/hysts/Shap-E
我发出来之后,估计就有不少人排队了,可以错峰试玩。
测试了一番,我的感受是这样的:
如果你是这个方向的研究生,那这篇论文值得看,算法也值得跑一跑,一些思想可以参考,说不定下一篇 best paper 就是你的了。
但如果你是个吃瓜群众,那就别浪费时间跑了,效果还不到直接可用的程度,没有图片生成那种惊艳的效果,不能直接用来做一些素材的生产。
好了,今天就聊这么多吧,我是 Jack,我们下期见~