参考:
https://github.com/facebookresearch/ImageBind
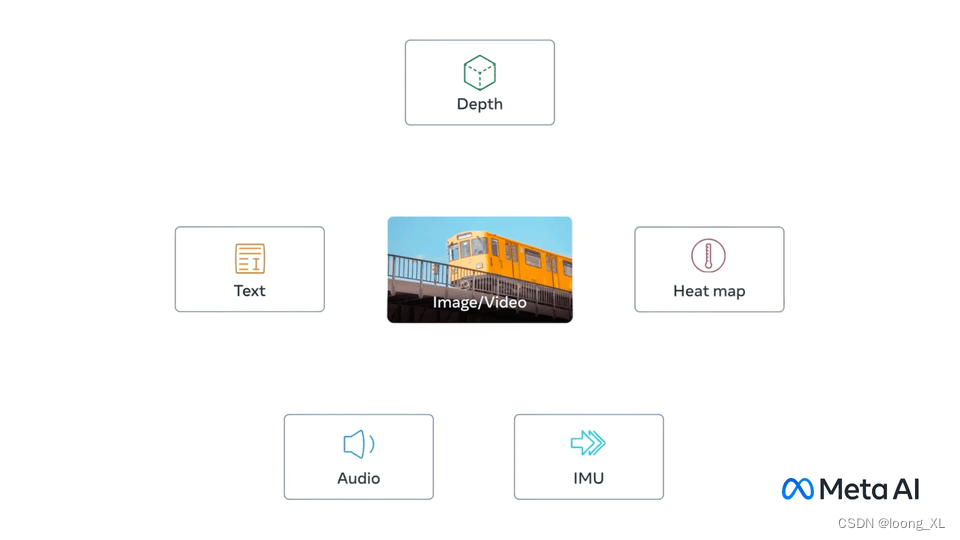
ImageBind learns a joint embedding across six different modalities - images, text, audio, depth, thermal, and IMU data
ImageBind 多个模态共享同一个空间Embedding,这样可以通过一个模态检索相似其他模态,相比CLIP文本图像两个模态,向外扩展了很多

代码测试
1、这边windows上测试的,由于audio相关库没装好,所以只测试了文本与图形相关模态的相似度召回计算;使用尽量还是linux机器
import data
import torch
from models import imagebind_model
from models.imagebind_model import ModalityType
text_list=["A dog.", "A car", "A bird"]
image_paths=[".assets/dog_image.jpg", ".assets/car_image.jpg", ".assets/bird_image.jpg"]
audio_paths=[".assets/dog_audio.wav", ".assets/car_audio.wav", ".assets/bird_audio.wav"]
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Load data
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text_list, device),
ModalityType.VISION: data.load_and_transform_vision_data(image_paths, device),
# ModalityType.AUDIO: data.load_and_transform_audio_data(audio_paths, device),
}
with torch.no_grad():
embeddings = model(inputs)
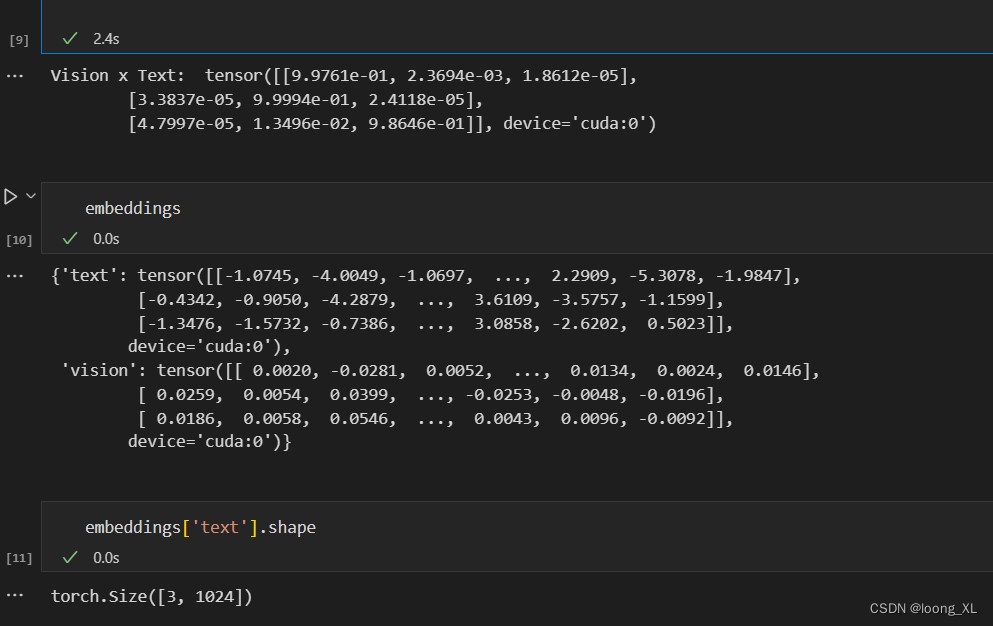
print(
"Vision x Text: ",
torch.softmax(embeddings[ModalityType.VISION] @ embeddings[ModalityType.TEXT].T, dim=-1),
)
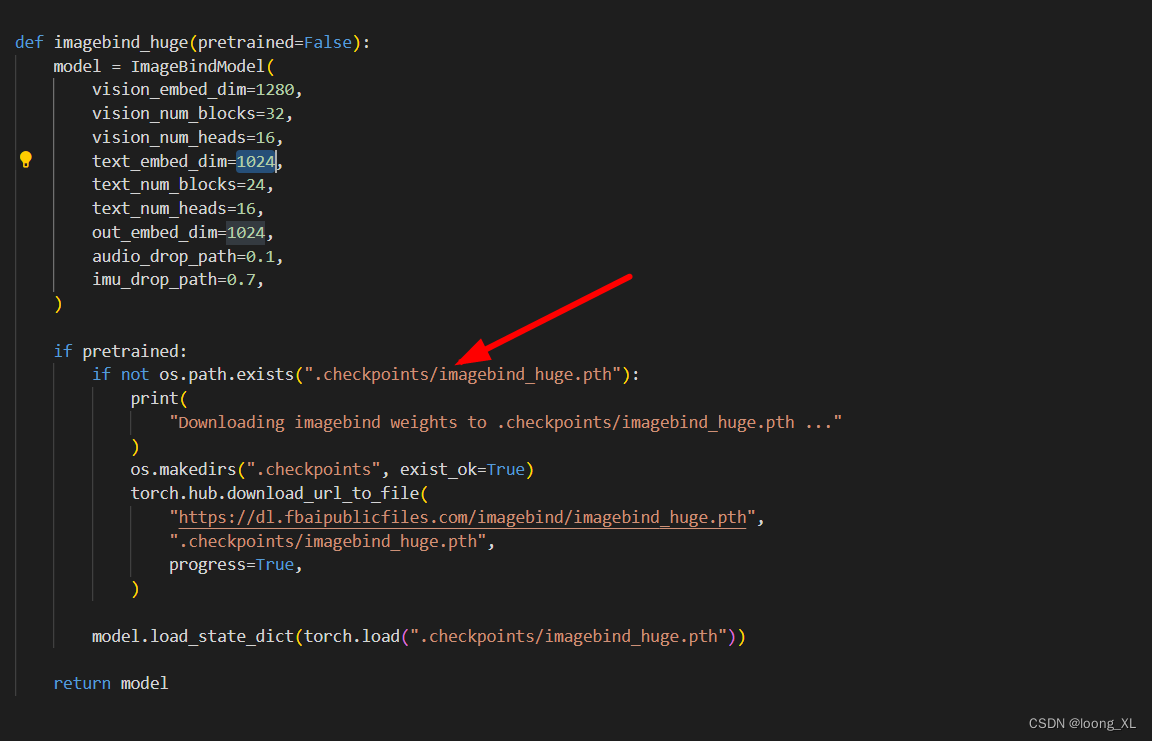
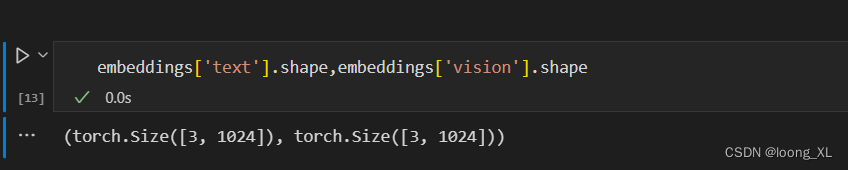
2、ImageBind 模型编码的Embedding向量维度都是1024
3、预训练好的模型默认放到.checkpoints/imagebind_huge.pth下