目录
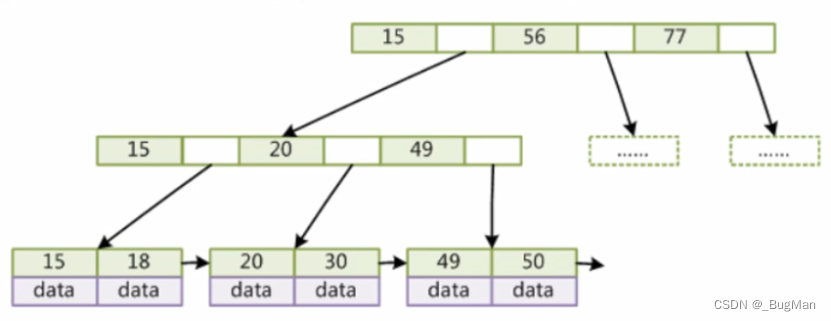
B+树结构
测试数据
索引失效的情况
没有用到索引
违反左前缀原则
范围查询断索引
like需要分情况
结果数据超过半数
B+树结构
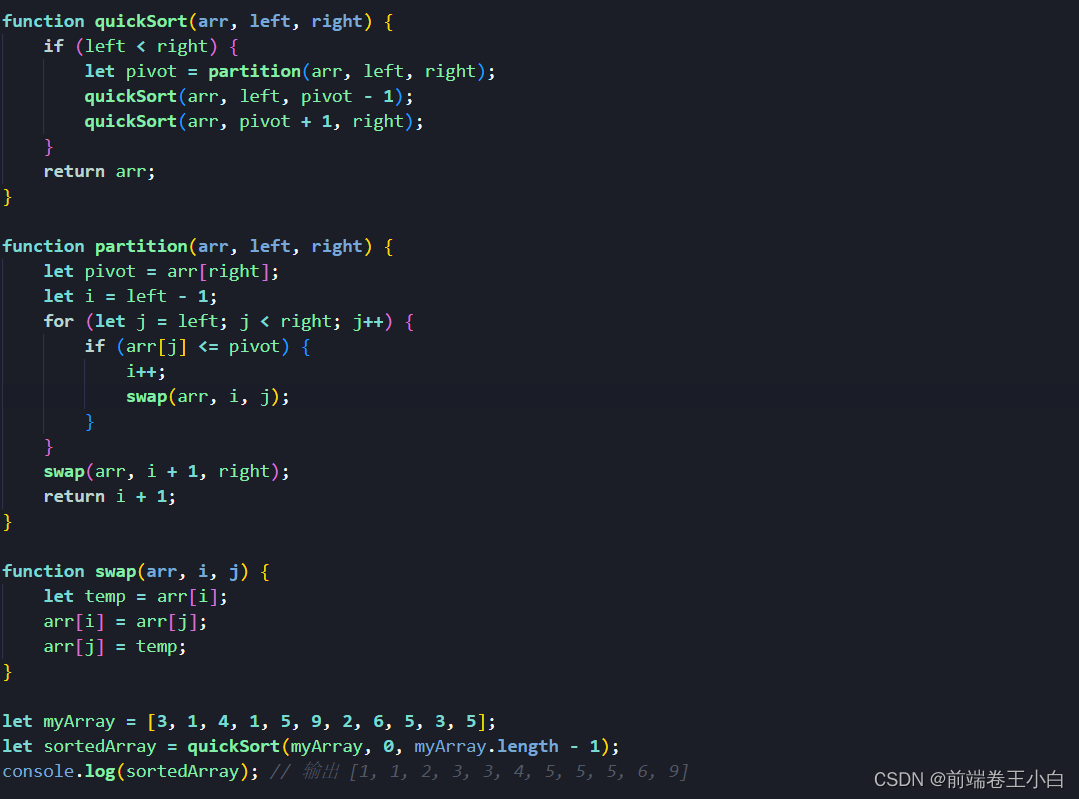
索引失效的根本原因其实就是违反了B+树的结构特性,查找的时候没办法在B+树上继续走下去,所以首先我们来回顾一下B+树的数据结构。
如果对B树、B+树不熟悉的可以看一下博主之前的文章,详细介绍了这两种数据结构:数据结构(8)树形结构——B树、B+树(含完整建树过程)_b+树构造过程__BugMan的博客-CSDN博客
B+树是一棵N叉树,遵循每个节点遵循左<根<右,然后叶节点上是一条分支上的所有数据,且为了方便范围查询,叶子节点用指针连接。
测试数据
以下是本文中用到的测试表结构和数据。
表结构:
create table school_timetable
(
id bigint primary key,
tid bigint,
cid bigint
)engine = innodb
default charset = utf8;表数据:
insert into school_timetable value(1,1,1);
insert into school_timetable value(2,2,2);
insert into school_timetable value(3,3,3);
insert into school_timetable value(4,4,4);索引失效的情况
索引失效的情况可以归类为以下几类:
- 没有用到索引
- 违反左前缀原则
- 范围查询断索引
- like需要分情况
- 结果数据超过半数
没有用到索引
没有用到索引当然索引就不会生效,比如以下条件字段上没有建立任何索引,查找的时候只能老实的全表扫描,从头到尾去找匹配的数。反应在SQL的执行计划上就是type为ALL:

违反左前缀原则
左前缀原则,指在使用复合索引时,只有当查询条件涵盖复合索引的最左边连续一段时,索引才能被充分利用。
注意:只有在MySQL 8版本以前,违反左前缀原则才会造成索引失效,因为在MySQL 8版本以后创建复合索引的时候会在复合索引的每个字段上再单独创建一个索引,这样即使违反了左前缀原则,仍然有单字段索引能走。
左前缀原则其实从B+树的数据机构的特性能很好想明白,在复合索引的时候,索引在树上面的位置一定是按照范围索引的顺序来排序的,先按照复合索引里面的第一个字段来排序,当第一个字段相等时按照第二个字段来排序,以此类推:
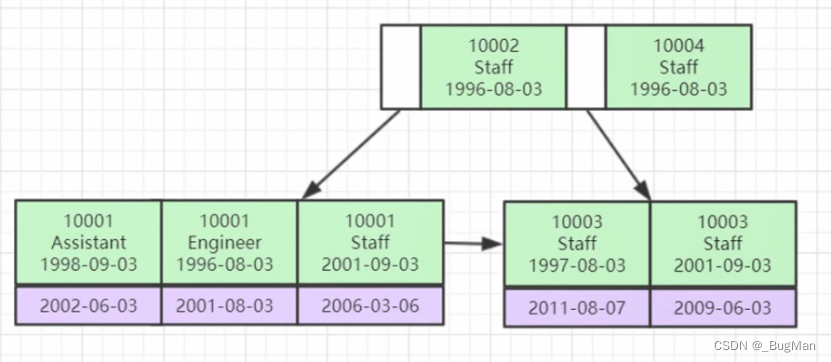
以上面的复合索引为例子,假设我们的查询条件是:
number=10001 and birthday = 2001-09-03
明显可以看到先通过number=10001定位后,直接用birthday的话是没办法利用到左大右小的性质继续走下去的,后续的查找只能是去扫描剩下的全部,反应在SQL执行计划里就是从断开的地方开始type跌落为range。
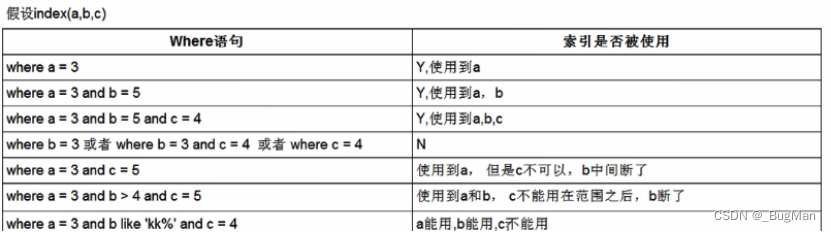
以下是各种违法左前缀原则的情况总结:
范围查询断索引
范围查询断索引,意思是在查询条件中间如果出现了范围查询,从范围查询处开始,后续的索引字段会失效,反应在SQL执行计划上就是type为range,以下用我们的测试数据为例:
index(tid,cid)

范围查询断索引的原因结合B+树的结构特性能很容易想明白,用了范围查询后框出来的是一个范围而不是一个具体的节点,自然走到这里就走不下去了,后续的条件必须去和范围里的每个节点进行比对、匹配。
like需要分情况
在使用like的时候会不会造成索引失效,分以下两种情况:
- 不以%开头
- 以%开头
如果开头没用通配符%开头,那么就是个范围查询,SQL执行计划的type是range,如果用了通配符%开头,那么也直接会跌落到SQL的执行计划的type为ALL。这个思考一下就能想明白,用了通配符就必须去每条数据挨着比对才行,根本就走不了B+树。
如果非要使用%的话,可以使用覆盖索引,这样的话能强行将type从全表扫描拉回到index,这是唯一的优化办法,至于其中关于覆盖索引的原理,将会在后续关于SQL索引优化的相关文章中进行讨论。
结果数据超过半数
当查询的结果数量超过总数量的一半时,MySQL 通常会放弃使用索引而执行全表扫描,这是因为对于大多数查询优化器来说,全表扫描比使用索引然后回溯一半以上的数据更快。
当查询的结果数量超过总数量的一半时,这意味着通过索引进行过滤的效果相对较差。在这种情况下,如果使用索引来定位一半以上的数据,并回溯它们以匹配查询条件,可能会导致更多的磁盘 I/O 和 CPU 开销,从而降低查询性能。
因此,为了提高查询性能,MySQL 通常会选择执行全表扫描,以避免索引回溯的开销。