【自然语言处理(NLP)】基于SQuAD的机器阅读理解

作者简介:在校大学生一枚,华为云享专家,阿里云专家博主,腾云先锋(TDP)成员,云曦智划项目总负责人,全国高等学校计算机教学与产业实践资源建设专家委员会(TIPCC)志愿者,以及编程爱好者,期待和大家一起学习,一起进步~
.
博客主页:ぃ灵彧が的学习日志
.
本文专栏:人工智能
.
专栏寄语:若你决定灿烂,山无遮,海无拦
.

文章目录
- 【自然语言处理(NLP)】基于SQuAD的机器阅读理解
- 前言
- (一)、任务描述
- (二)、环境配置
- 一、数据准备
- (一)、数据集简介
- (二)、数据处理
- (三)、处理测试数据的特征
- (四)、生成训练数据加载器
- 二、BERT模型配置
- 三、模型训练
- 四、模型预测与评估
- 总结
前言
(一)、任务描述
机器阅读理解(Maching Reading Comprehension,MRC)是一项基于文本的问答任务(Text-QA),也是非常重要和经典的自然语言处理任务之一。机器阅读理解旨在对自然语言文本进行语义理解和推理,并以此完成一些下游的任务。
(二)、环境配置
本示例基于飞桨开源框架2.0版本。
import paddle
import paddle.nn.functional as F
import re
import numpy as np
print(paddle.__version__)
# cpu/gpu环境选择,在 paddle.set_device() 输入对应运行设备。
# device = paddle.set_device('gpu')
输出结果如下图1所示:

一、数据准备
(一)、数据集简介
斯坦福问答数据集(SQuAD)是一个阅读理解数据集,由维基百科的一系列文章中提出的问题及答案组成,其中每个问题的答案要么对应阅读段落中的一段文本或片段,要么没有答案。
(二)、数据处理
机器阅读理解中的长度限制问题:由于机器阅读理解任务很多篇章都会超过预训练模型的最大长度限制,如BERT模型单条最大处理文本长度为512个字符,因此绝大多数情况下需要做截断或者更换模型结构等操作,本实践使用滑动窗口方式来解决长度问题。
def prepare_train_features(examples):
contexts = [examples[i]['context'] for i in range(len(examples))]
questions = [examples[i]['question'] for i in range(len(examples))]
tokenized_examples = tokenizer(
questions,
contexts,
stride=doc_stride,
max_seq_len=max_seq_length)
# Let's label those examples!
for i, tokenized_example in enumerate(tokenized_examples):
# We will label impossible answers with the index of the CLS token.
input_ids = tokenized_example["input_ids"]
cls_index = input_ids.index(tokenizer.cls_token_id)
# The offset mappings will give us a map from token to character position in the original context. This will
# help us compute the start_positions and end_positions.
offsets = tokenized_example['offset_mapping']
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_example['token_type_ids']
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = tokenized_example['overflow_to_sample']
answers = examples[sample_index]['answers']
answer_starts = examples[sample_index]['answer_starts']
# Start/end character index of the answer in the text.
start_char = answer_starts[0]
end_char = start_char + len(answers[0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# Minus one more to reach actual text
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and
offsets[token_end_index][1] >= end_char):
tokenized_examples[i]["start_positions"] = cls_index
tokenized_examples[i]["end_positions"] = cls_index
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[
token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples[i]["start_positions"] = token_start_index - 1
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples[i]["end_positions"] = token_end_index + 1
return tokenized_examples
(三)、处理测试数据的特征
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
# NOTE: Almost the same functionality as HuggingFace's prepare_train_features function. The main difference is
# that HugggingFace uses ArrowTable as basic data structure, while we use list of dictionary instead.
contexts = [examples[i]['context'] for i in range(len(examples))]
questions = [examples[i]['question'] for i in range(len(examples))]
tokenized_examples = tokenizer(
questions,
contexts,
stride=doc_stride,
max_seq_len=max_seq_length)
# For validation, there is no need to compute start and end positions
for i, tokenized_example in enumerate(tokenized_examples):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_example['token_type_ids']
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = tokenized_example['overflow_to_sample']
tokenized_examples[i]["example_id"] = examples[sample_index]['id']
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples[i]["offset_mapping"] = [
(o if sequence_ids[k] == 1 else None)
for k, o in enumerate(tokenized_example["offset_mapping"])
]
return tokenized_examples
(四)、生成训练数据加载器
if train_file:
train_ds = load_dataset(task_name, data_files=train_file)
else:
train_ds = load_dataset(task_name, splits='train')
train_ds.map(prepare_train_features, batched=True)
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
train_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"start_positions": Stack(dtype="int64"),
"end_positions": Stack(dtype="int64")
}): fn(samples)
train_data_loader = DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
num_training_steps = max_steps if max_steps > 0 else len(
train_data_loader) * num_train_epochs
num_train_epochs = math.ceil(num_training_steps /
len(train_data_loader))
lr_scheduler = LinearDecayWithWarmup(
learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
criterion = CrossEntropyLossForSQuAD()
global_step = 0
tic_train = time.time()
for epoch in range(num_train_epochs):
for step, batch in enumerate(train_data_loader):
global_step += 1
input_ids, token_type_ids, start_positions, end_positions = batch
logits = model(
input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % logging_steps == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s"
% (global_step, epoch + 1, step + 1, loss,
logging_steps / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % save_steps == 0 or global_step == num_training_steps:
if rank == 0:
output_dir_ = os.path.join(output_dir,
"model_%d" % global_step)
if not os.path.exists(output_dir_):
os.makedirs(output_dir_)
# need better way to get inner model of DataParallel
model_to_save = model._layers if isinstance(
model, paddle.DataParallel) else model
model_to_save.save_pretrained(output_dir_)
tokenizer.save_pretrained(output_dir_)
print('Saving checkpoint to:', output_dir_)
if global_step == num_training_steps:
break
二、BERT模型配置
本实践使用BERT预训练模型进行微调,该模型对应PaddleNLP中的BertForQuestionAnswering模型,与BERT关联的Tokenizer为BertTokenizer,此处我们使用BERT模型进行微调,并且对所有英文字母都进行小写处理,调用model_class.from_pretrained(model_name_or_path)时,若本地没有下载预训练的参数,会首先下载参数:
model_type='bert'
model_name_or_path='bert-base-chinese'
task_name = task_name.lower()
model_type = model_type.lower()
model_class, tokenizer_class = MODEL_CLASSES[model_type]
tokenizer = tokenizer_class.from_pretrained(model_name_or_path)
三、模型训练
@paddle.no_grad()
def evaluate(model, data_loader):
model.eval()
all_start_logits = []
all_end_logits = []
tic_eval = time.time()
for batch in data_loader:
input_ids, token_type_ids = batch
start_logits_tensor, end_logits_tensor = model(input_ids,
token_type_ids)
for idx in range(start_logits_tensor.shape[0]):
if len(all_start_logits) % 1000 == 0 and len(all_start_logits):
print("Processing example: %d" % len(all_start_logits))
print('time per 1000:', time.time() - tic_eval)
tic_eval = time.time()
all_start_logits.append(start_logits_tensor.numpy()[idx])
all_end_logits.append(end_logits_tensor.numpy()[idx])
all_predictions, _, _ = compute_prediction(
data_loader.dataset.data, data_loader.dataset.new_data,
(all_start_logits, all_end_logits), False, n_best_size,
max_answer_length)
# Can also write all_nbest_json and scores_diff_json files if needed
with open('prediction.json', "w", encoding='utf-8') as writer:
writer.write(
json.dumps(
all_predictions, ensure_ascii=False, indent=4) + "\n")
squad_evaluate(
examples=data_loader.dataset.data,
preds=all_predictions,
is_whitespace_splited=False)
model.train()
四、模型预测与评估
class CrossEntropyLossForSQuAD(paddle.nn.Layer):
def __init__(self):
super(CrossEntropyLossForSQuAD, self).__init__()
def forward(self, y, label):
start_logits, end_logits = y
start_position, end_position = label
start_position = paddle.unsqueeze(start_position, axis=-1)
end_position = paddle.unsqueeze(end_position, axis=-1)
start_loss = paddle.nn.functional.cross_entropy(
input=start_logits, label=start_position)
end_loss = paddle.nn.functional.cross_entropy(
input=end_logits, label=end_position)
loss = (start_loss + end_loss) / 2
return loss
def run():
task_name='dureader_robust'
train_file=None
predict_file=None
model_type='bert'
model_name_or_path='bert-base-chinese'
output_dir='models'
max_seq_length=128
batch_size=8
learning_rate=5e-5
weight_decay=0.0
adam_epsilon=1e-8
ax_grad_norm=1.0
num_train_epochs=3
max_steps=-1
warmup_proportion=0.0
logging_steps=200
save_steps=200
seed=42
device='gpu'
doc_stride =128
n_best_size =20
max_query_length=64
max_answer_length=30
do_lower_case=True
verbose=True
do_train=True
do_predict=True
paddle.set_device(device)
if paddle.distributed.get_world_size() > 1:
paddle.distributed.init_parallel_env()
rank = paddle.distributed.get_rank()
task_name='dureader_robust'
model_type='bert'
model_name_or_path='bert-base-chinese'
task_name = task_name.lower()
model_type = model_type.lower()
model_class, tokenizer_class = MODEL_CLASSES[model_type]
tokenizer = tokenizer_class.from_pretrained(model_name_or_path)
set_seed(1024)
if rank == 0:
if os.path.exists(model_name_or_path):
print("init checkpoint from %s" % model_name_or_path)
model = model_class.from_pretrained(model_name_or_path)
if paddle.distributed.get_world_size() > 1:
model = paddle.DataParallel(model)
def prepare_train_features(examples):
contexts = [examples[i]['context'] for i in range(len(examples))]
questions = [examples[i]['question'] for i in range(len(examples))]
tokenized_examples = tokenizer(
questions,
contexts,
stride=doc_stride,
max_seq_len=max_seq_length)
# Let's label those examples!
for i, tokenized_example in enumerate(tokenized_examples):
# We will label impossible answers with the index of the CLS token.
input_ids = tokenized_example["input_ids"]
cls_index = input_ids.index(tokenizer.cls_token_id)
# The offset mappings will give us a map from token to character position in the original context. This will
# help us compute the start_positions and end_positions.
offsets = tokenized_example['offset_mapping']
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_example['token_type_ids']
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = tokenized_example['overflow_to_sample']
answers = examples[sample_index]['answers']
answer_starts = examples[sample_index]['answer_starts']
# Start/end character index of the answer in the text.
start_char = answer_starts[0]
end_char = start_char + len(answers[0])
# Start token index of the current span in the text.
token_start_index = 0
while sequence_ids[token_start_index] != 1:
token_start_index += 1
# End token index of the current span in the text.
token_end_index = len(input_ids) - 1
while sequence_ids[token_end_index] != 1:
token_end_index -= 1
# Minus one more to reach actual text
token_end_index -= 1
# Detect if the answer is out of the span (in which case this feature is labeled with the CLS index).
if not (offsets[token_start_index][0] <= start_char and
offsets[token_end_index][1] >= end_char):
tokenized_examples[i]["start_positions"] = cls_index
tokenized_examples[i]["end_positions"] = cls_index
else:
# Otherwise move the token_start_index and token_end_index to the two ends of the answer.
# Note: we could go after the last offset if the answer is the last word (edge case).
while token_start_index < len(offsets) and offsets[
token_start_index][0] <= start_char:
token_start_index += 1
tokenized_examples[i]["start_positions"] = token_start_index - 1
while offsets[token_end_index][1] >= end_char:
token_end_index -= 1
tokenized_examples[i]["end_positions"] = token_end_index + 1
return tokenized_examples
if do_train:
if train_file:
train_ds = load_dataset(task_name, data_files=train_file)
else:
train_ds = load_dataset(task_name, splits='train')
train_ds.map(prepare_train_features, batched=True)
train_batch_sampler = paddle.io.DistributedBatchSampler(
train_ds, batch_size=batch_size, shuffle=True)
train_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
"start_positions": Stack(dtype="int64"),
"end_positions": Stack(dtype="int64")
}): fn(samples)
train_data_loader = DataLoader(
dataset=train_ds,
batch_sampler=train_batch_sampler,
collate_fn=train_batchify_fn,
return_list=True)
num_training_steps = max_steps if max_steps > 0 else len(
train_data_loader) * num_train_epochs
num_train_epochs = math.ceil(num_training_steps /
len(train_data_loader))
lr_scheduler = LinearDecayWithWarmup(
learning_rate, num_training_steps, warmup_proportion)
# Generate parameter names needed to perform weight decay.
# All bias and LayerNorm parameters are excluded.
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
epsilon=adam_epsilon,
parameters=model.parameters(),
weight_decay=weight_decay,
apply_decay_param_fun=lambda x: x in decay_params)
criterion = CrossEntropyLossForSQuAD()
global_step = 0
tic_train = time.time()
for epoch in range(num_train_epochs):
for step, batch in enumerate(train_data_loader):
global_step += 1
input_ids, token_type_ids, start_positions, end_positions = batch
logits = model(
input_ids=input_ids, token_type_ids=token_type_ids)
loss = criterion(logits, (start_positions, end_positions))
if global_step % logging_steps == 0:
print(
"global step %d, epoch: %d, batch: %d, loss: %f, speed: %.2f step/s"
% (global_step, epoch + 1, step + 1, loss,
logging_steps / (time.time() - tic_train)))
tic_train = time.time()
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
if global_step % save_steps == 0 or global_step == num_training_steps:
if rank == 0:
output_dir_ = os.path.join(output_dir,
"model_%d" % global_step)
if not os.path.exists(output_dir_):
os.makedirs(output_dir_)
# need better way to get inner model of DataParallel
model_to_save = model._layers if isinstance(
model, paddle.DataParallel) else model
model_to_save.save_pretrained(output_dir_)
tokenizer.save_pretrained(output_dir_)
print('Saving checkpoint to:', output_dir_)
if global_step == num_training_steps:
break
def prepare_validation_features(examples):
# Tokenize our examples with truncation and maybe padding, but keep the overflows using a stride. This results
# in one example possible giving several features when a context is long, each of those features having a
# context that overlaps a bit the context of the previous feature.
# NOTE: Almost the same functionality as HuggingFace's prepare_train_features function. The main difference is
# that HugggingFace uses ArrowTable as basic data structure, while we use list of dictionary instead.
contexts = [examples[i]['context'] for i in range(len(examples))]
questions = [examples[i]['question'] for i in range(len(examples))]
tokenized_examples = tokenizer(
questions,
contexts,
stride=doc_stride,
max_seq_len=max_seq_length)
# For validation, there is no need to compute start and end positions
for i, tokenized_example in enumerate(tokenized_examples):
# Grab the sequence corresponding to that example (to know what is the context and what is the question).
sequence_ids = tokenized_example['token_type_ids']
# One example can give several spans, this is the index of the example containing this span of text.
sample_index = tokenized_example['overflow_to_sample']
tokenized_examples[i]["example_id"] = examples[sample_index]['id']
# Set to None the offset_mapping that are not part of the context so it's easy to determine if a token
# position is part of the context or not.
tokenized_examples[i]["offset_mapping"] = [
(o if sequence_ids[k] == 1 else None)
for k, o in enumerate(tokenized_example["offset_mapping"])
]
return tokenized_examples
if do_predict and rank == 0:
if predict_file:
dev_ds = load_dataset(task_name, data_files=predict_file)
else:
dev_ds = load_dataset(task_name, splits='dev')
dev_ds.map(prepare_validation_features, batched=True)
dev_batch_sampler = paddle.io.BatchSampler(
dev_ds, batch_size=batch_size, shuffle=False)
dev_batchify_fn = lambda samples, fn=Dict({
"input_ids": Pad(axis=0, pad_val=tokenizer.pad_token_id),
"token_type_ids": Pad(axis=0, pad_val=tokenizer.pad_token_type_id)
}): fn(samples)
dev_data_loader = DataLoader(
dataset=dev_ds,
batch_sampler=dev_batch_sampler,
collate_fn=dev_batchify_fn,
return_list=True)
evaluate(model, dev_data_loader)
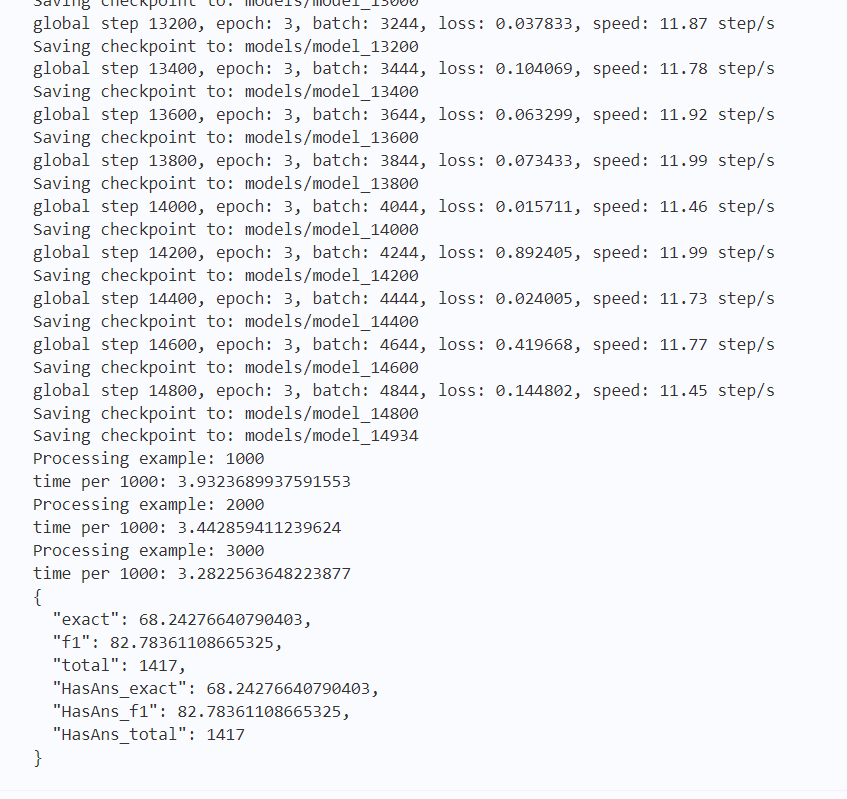
部分输出结果如下图2所示:
总结
本系列文章内容为根据清华社出版的《自然语言处理实践》所作的相关笔记和感悟,其中代码均为基于百度飞桨开发,若有任何侵权和不妥之处,请私信于我,定积极配合处理,看到必回!!!
最后,引用本次活动的一句话,来作为文章的结语~( ̄▽ ̄~)~:
【学习的最大理由是想摆脱平庸,早一天就多一份人生的精彩;迟一天就多一天平庸的困扰。】
ps:更多精彩内容还请进入本文专栏:人工智能,进行查看,欢迎大家支持与指教啊~( ̄▽ ̄~)~





![[附源码]SSM计算机毕业设计疫情期间物资分派管理系统JAVA](https://img-blog.csdnimg.cn/b59213a991bd4a61bc184cf10496afb8.png)

![[附源码]Python计算机毕业设计Django个人博客系统](https://img-blog.csdnimg.cn/6bb236949fd74c6d80fb701312c2a757.png)