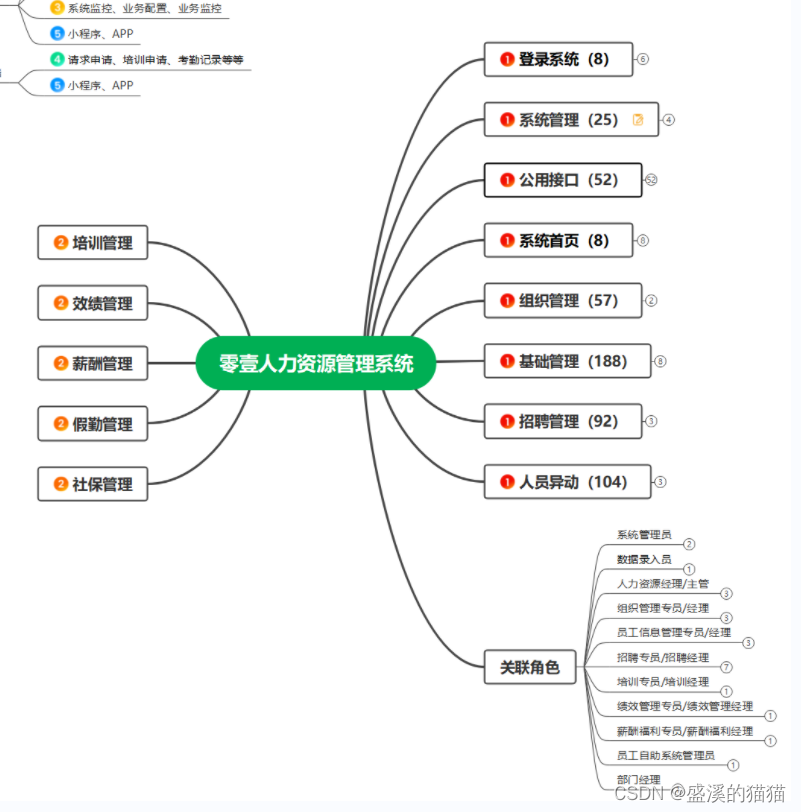
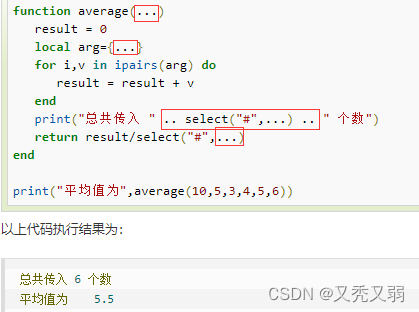
目录标题
- 设计模式
- stack的模拟实现
- 准备工作
- 各种函数的实现
- queue的模拟实现
- 准备工作
- queue的接口实现
- deque的介绍
- 为什么会有deque
- deque的原理
- deque的迭代器
- 为什么使用deque
设计模式
设计模式分为两个:迭代器模式和适配器模式
第一个:迭代器模式
迭代器模式就是在不暴露底层的细节的前提下,通过封装给用户提供统一的接口让用户访问容器里面的数据,我们使用的每个容器都可以通过创建迭代器变量的方式来访问容器里面的内容,并且访问的方式都是一样的,(*迭代器变量)可以得到并修改指定位置的数据,(迭代器++)可以让迭代器变量指向容器的下一个元素,通过上面的两个操作,不管是vector容器还是string容器还是后面要学的更加复杂的容器,我们都可以很简单的访问容器里面的内容,但是这些迭代器底层实现的原理是一样的吗?vector和string迭代器是通过创建一个指针变量来实现的,而list迭代器是创建一个类,通过这个类对list的数据进行封装来实现的,不同的容器的迭代器实现的方法也各不相同,但是作为使用者来说我们根本就不用了解这些迭代器的底层实现我们会用就行,并且迭代器的出现很大程度上降低了我们学习的成本,并且迭代器的出现还有助于维护数据的安全,如果我们认为的操作容器里面的数据的话,搞不好就将哪个重要的数据删除了,将另外一个地方的数据覆盖了,所以迭代器模式就对容器里面的数据进行了一下封装,我们要访问这些数据就只能通过迭代器的方式来进行访问,这样即降低了学习成本又保护了数据的安全,我们把这样的设计模式成为迭代器模式。
第二个:适配器模式
在之前的学习中我们知道stack对数据管理的方式是先入栈的数据后出栈,后入栈的数据先出栈,我们还知道queue对数据管理的方式是:先入队列的数据先出队列,后入队列的数据后出队列,这是两个容器对数据处理的方式,虽然这种处理数据的方式属于这些容器的,但是其他的容器也可以实现这样的功能,比如说vector和list都可以在容器的头部或者尾部插入或删除数据,如果我们只让vector或者list在容器的头部尾部插入删除数据的话,那是不是就相当于是stack了呢?如果我们只让vector或者list在头部删除数据在尾部插入数据的话,那这是不是就相当于queue了呢?所以在实现一个容器或者功能的时候,我们可以用现有东西进行一些简单的修改或者封装从而实现你想要的东西,那么这就是适配器模式:用已有的东西通过封装转换出来你想要的东西,那么我们这里的stack和queue就可以通过适配器模式来实现。
stack的模拟实现
准备工作
因为栈要存储各种各样的数据,所以我们这里得创建出来一个类模板,模板的第一个参数就表明容器中容纳的数据类型,因为stack即可以用vector来实现也可以使用list来实现,所以在模板还得有第二个参数,这个参数表明stack的底层是用什么样的容器实现的,因为stack是尾插尾删,所以使用vector容器作为底层有很大的好处,所以在模板参数里面可以添加一个缺省参数,如果用户不指定容器类型的话默认是以vector作为底层,那么这里的代码就如下:
#include<iostream>
#include<vector>
using namespace std;
template<class T,class continer=vector<int>>
class stack
{
public:
private:
continer con;
};
各种函数的实现
首先来实现一下stack的push函数因为stack在插入数据的时候只能在尾部插入数据,所以在stack的push函数里面就可以直接调用容器con的push_back函数来尾插数据,那么该函数的实现如下:
void push(T& val)
{
con.push_back(val);
}
stack中删除数据也只能删除尾部数组,所以实现pop函数的时候就可以直接调用容器con的pop_back函数来删除数据,那这里的代码就如下:
void pop()
{
con.pop_back();
}
同样的道理stack中的size函数empty函数top函数都可以分别调用容器的size函数,empty函数,back函数来实现,那么这里的代码就如下:
size_t size()
{
return con.size();
}
bool empty()
{
return con.empty();
}
const T& top()
{
return con.back();
}
因为stack容器的特殊访问逻辑,所以stack不支持迭代器,那么这里我们也就不需要实现,到这里容器stack我们就已经实现完成了,完整的代码如下:
#include<iostream>
#include<vector>
using namespace std;
namespace ycf
{
template<class T, class continer = vector<int>>
class stack
{
public:
void push(const T& val)
{
con.push_back(val);
}
void pop()
{
con.pop_back();
}
size_t size()
{
return con.size();
}
bool empty()
{
return con.empty();
}
const T& top()
{
return con.back();
}
private:
continer con;
};
}
使用下面的代码来进行一下测试:
void test1()
{
ycf::stack<int> s1;
s1.push(1);
s1.push(2);
s1.push(3);
s1.push(4);
while (!s1.empty())
{
cout << s1.top() << " ";
s1.pop();
}
cout << endl;
ycf::stack<int, list<int>> s2;
s2.push(4);
s2.push(3);
s2.push(2);
s2.push(1);
while (!s2.empty())
{
cout << s2.top() << " ";
s2.pop();
}
}
代码的运行结果如下:
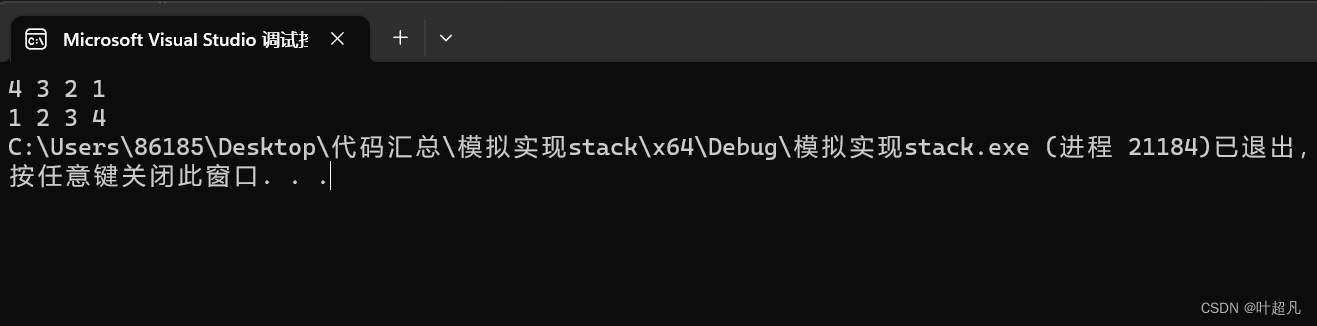
这里数据的打印没有任何问题,所以我们上面模拟实现的stack也就没有毛病,接下来我们再来看看queue的模拟实现。
queue的模拟实现
准备工作
同样的道理queue也要容纳各种数据,也可以由各种容器作为底层来容纳数据,所以queue也得创建一个模板,并且模板里面也得有两个参数,因为queue是在容器的头部删除数据,在容器的尾部插入数据,所以给第二个参数的缺省值最好是list,那么这里的代码就如下:
template<class T,class continer=list<T>>
class queue
{
public:
private:
continer con;
};
queue的接口实现
因为queue插入数据是在容器的尾部插入数据,所以在实现queue的push函数时可以通过调用con的push_back函数来实现,那这里的代码如下:
void push(const T& val)
{
con.push_back(val);
}
queue的pop函数是在容器的头部删除数据所以这里可以调用容器的pop_front函数来实现,那么这里的代码如下:
void pop()
{
con.pop_front();
}
同样的道理empty,size,front,back函数都是调用内部容器的empty,size,front,back函数来进行实现,那么这里的代码就如下:
size_t size()
{
return con.size();
}
bool empty()
{
return con.empty();
}
const T& front()
{
return con.front();
}
const T& back()
{
return con.back();
}
因为queue有着特殊的访问顺序,所以在queue中没有对应的迭代器,这里也就没有实现,那么queue的全部实现如下:
namespace ycf
{
template<class T,class continer=list<T>>
class queue
{
public:
void push(const T& val)
{
con.push_back(val);
}
void pop()
{
con.pop_front();
}
size_t size()
{
return con.size();
}
bool empty()
{
return con.empty();
}
const T& front()
{
return con.front();
}
const T& back()
{
return con.back();
}
private:
continer con;
};
}
这里可以用下面的代码来进行一下测试,首先使用默认容器list和push函数来插入一些数据,然后再使用pop函数和front函数和back函数来删除数据和查看头尾数据,那么测试代码如下:
void test3()
{
ycf::queue<int> q;
q.push(1);
q.push(2);
q.push(3);
q.push(4);
while (!q.empty())
{
cout << "队列的头部数据为:" << q.front() << endl;
cout << "队列的尾部数据为:" << q.back() << endl;
cout << "删除队列中的一个数据" << endl;
q.pop();
}
cout << "此时队列中没有任何数据" << endl;
}
代码的运行结果如下:

可以看到这里运行的结果没有什么问题,那这是不是就说明我们写的代码没有任何问题呢?我们上面的代码进行修改,让vector作为队列的底层容器然后再运行一下上面的代码看看结果如何:

我们可以看到这里并没有运行成功,报错告诉我们pop_front不是vector的内部成员函数,对哦vector中似乎确实没有pop_front函数但是有erase函数,那我们这里要想让queue删除头部数据的话,是不是得调用容器的erase函数呢?答案是没必要,vector之所以没有pop_front函数是因为对vector进行头部删除的代价实在是太大了,所以官方并不想提供这个函数,而这里的报错其实是从另外一个方面提醒使用者不要使用vector这个容器作为底层,因为效率太低了所以就直接报错,从而起到了一个提醒的作用,所以这里我们就不要再做修改就使用pop_front函数来作为pop函数的底层,那么以上就是queue函数的底层实现。
deque的介绍
为什么会有deque
我们上面实现的容器一般都采用list或者vector作为默认容器,可是大家查看官网的介绍时就会发现,他们的stack和queue采用的却是deque作为默认容器,比如说下面的图片:


那这个queue究竟是什么呢?为什么会采用这个容器作为stack和queue的默认容器呢?未来了解这两个问题首先我们得思考一下list和vector各有什么优点和缺点,
vector的优点:
因为vector底层为连续的空间,所以对于vector来说最大的优点就是支持下标随机访问,并且不容易产生内存碎片空间利用率更高,因为底层是连续的空间所以cpu高速缓存的命中率也很高,那么这就是vector的优点。
vector的缺点
vector的底层是一段连续的空间这给该容器带来了很多的好处,但是有利就会有弊,当我们往这个容器的头部或者中部插入或者删除数据时效率就会非常的低,因为数据是连续的所以每次插入删除数据都会导致后面的数据不停的往前或者往后进行挪动,如果数据十分多的话这就会导致该容器的使用效率非常的低,并且vector容器在扩容的时候很大程度上都会采取异地扩容的方式,异地扩容就会涉及到数据的拷贝,那么这就又会导致效率降低,那么这就是vector的缺点。
list的优点
list在任意位置插入删除数据的效率都非常的高不会出现数据挪动的现象,并且list并不是采用一段连续的空间来存储数据,而是采用节点动态开辟的方式,所以list在存储数据的时候并不会出现扩容而导致的数据迁移的问题。
list的缺点
list采用节点动态开辟的方式来存储数据,但是这种方式容易造成内存碎片,空间利用率低的问题,并且list存储数据的位置并不集中,这也就导致了cpu高速缓存命中率低的问题,最后list不支持随机访问某个元素,访问元素的时间复杂度为o(N),那么这就是list的缺点。
看到这里想必大家应该能够知道vector和list的优缺点,那这里就有个问题?有没有一个容器既能够拥有list的优点又能够拥有vector的优点呢?对吧!即可以下标随机访问又可以在头部插入删除数据的时候不用挪动后面的数据,而且空间利用率高,cpu高速缓存的命中率也高,但是是有的这个容器就是deque,那这个容器是如何实现的呢?我们接着往下看。
deque的原理
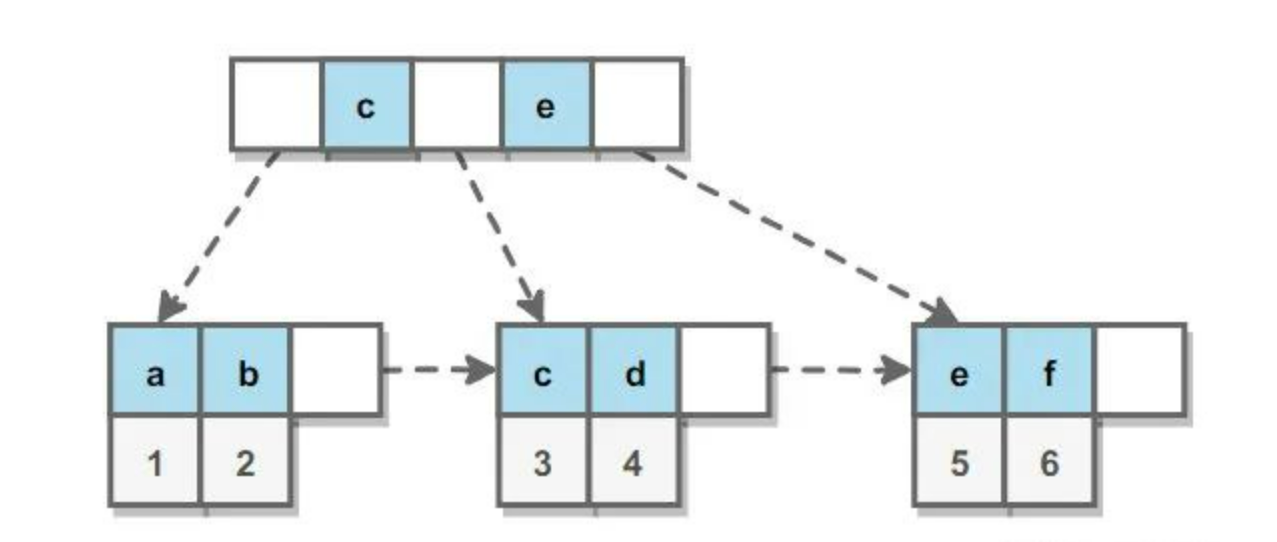
deque容器是由多个buffer数组和一个中控数组构成比如说下面的图片
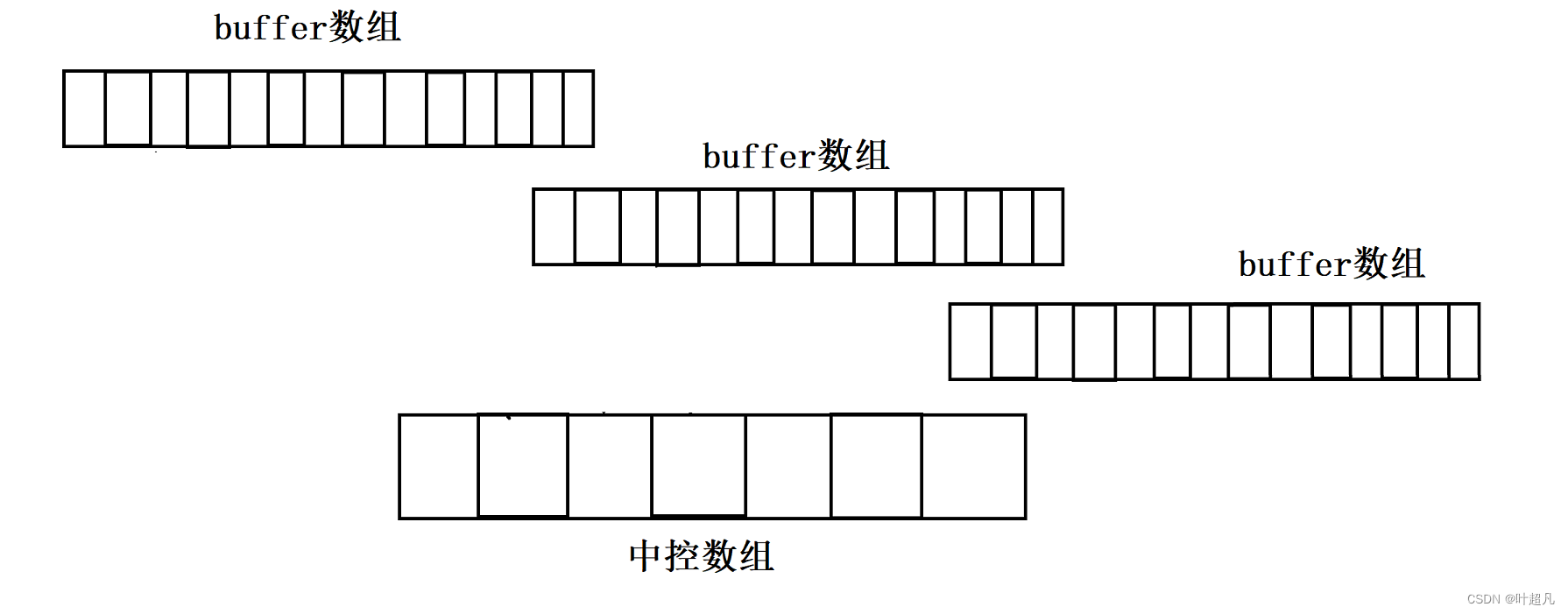
buffer数组里面存储用户提供的数据,而中控数组里面存储buffer的地址,这样计算机就能够通过中控数组里面的地址找到对应的buffer数组从而找到想要的数据,比如说下面的图片:
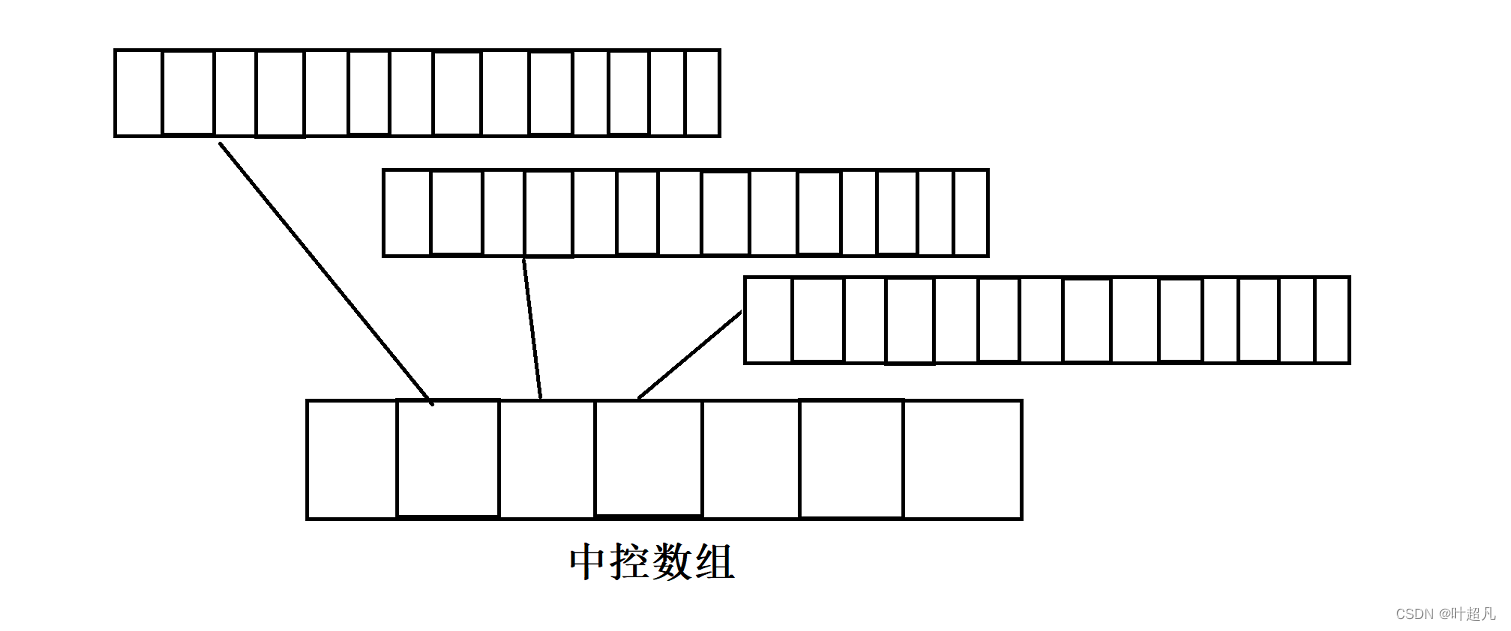
当deque里面只有一个元素时,deque就只会申请一个buffer数组,并在中控数组的中间部分申请一个元素,让该元素存储buffer数组的地址,比如说下面的图片:
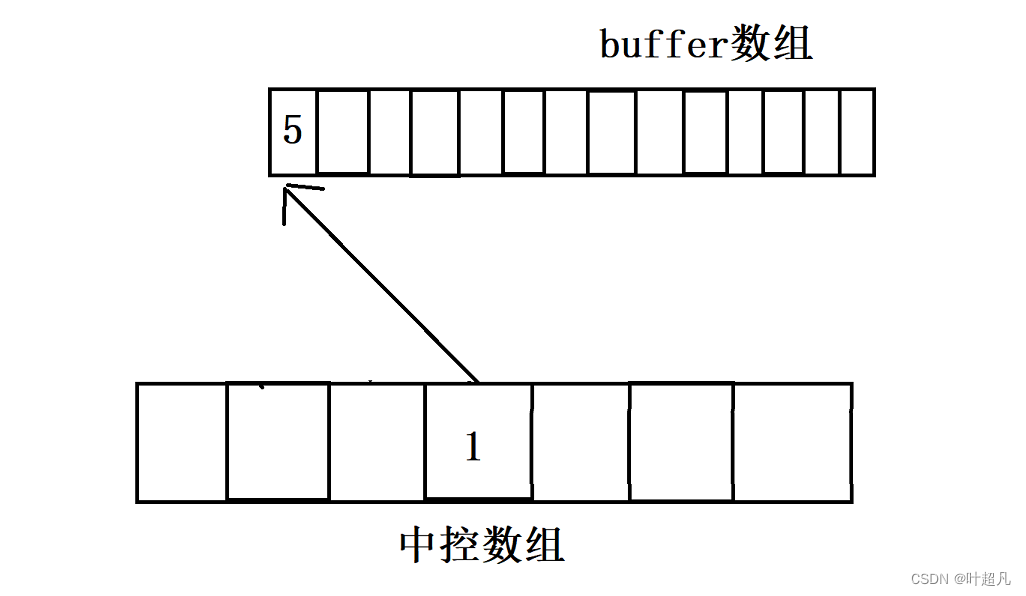
当往deque容器中不停的尾插数据使得当前buffer数组装满之后就会再申请一个buffer数组,并将buffer数组的地址填入中控数组里面,那么这里就是填入1的右边,比如说下面的图片
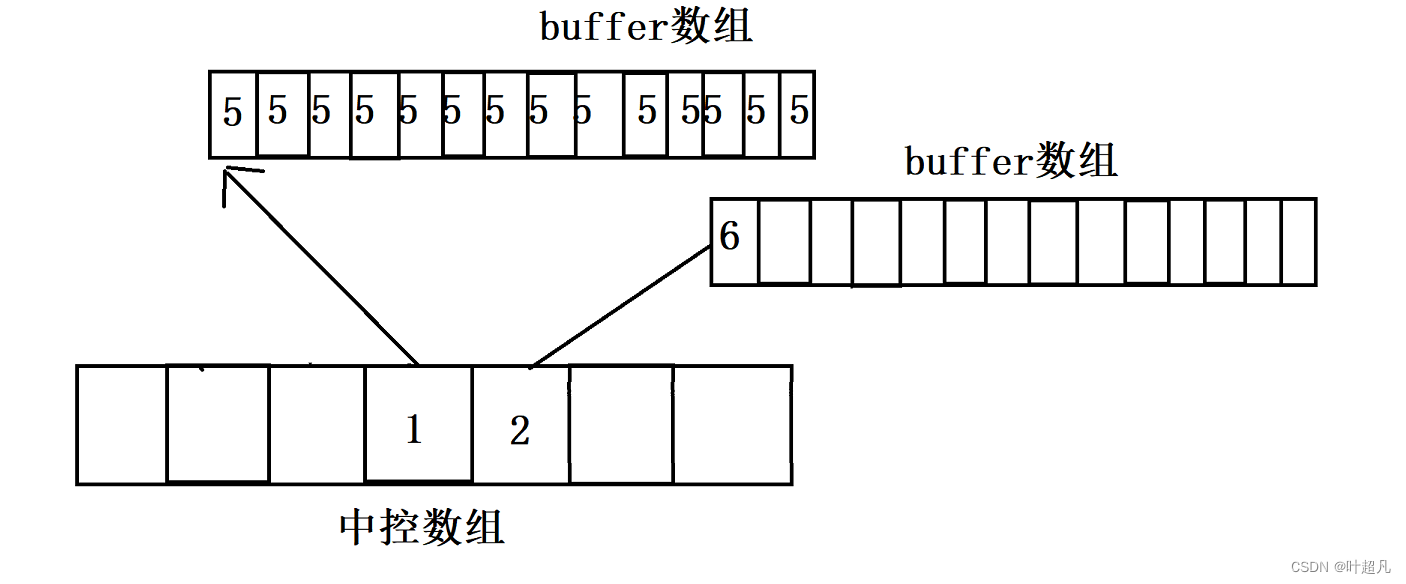
当我们从deque的头部插入的话就会再创建一个buffer出来,将要插入的数据放到这个buffer的最右边的未被占用的位置,并将buffer数组的地址放到中控数组1的左边比如说下面的图片:
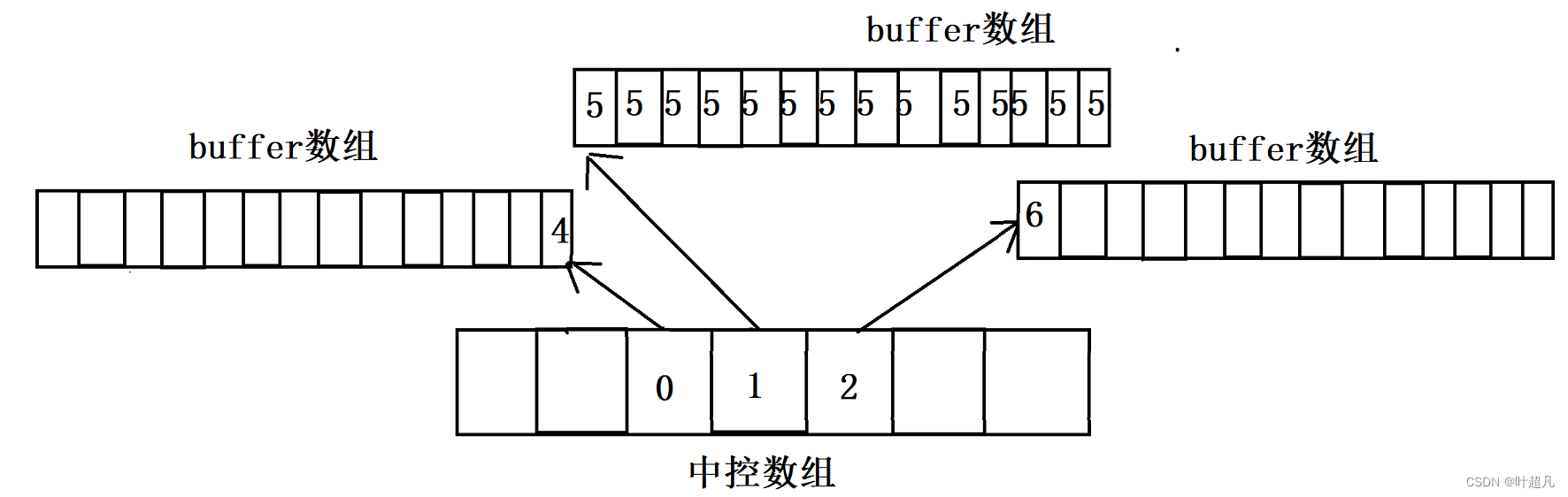
当中控数组中1的左边或者右边填满之后就会对中控数组进行扩容,从而实现对整个数组进行扩容,vector的随机访问是直接通过指针的加减整数来实现的访问,比如说访问vector中的第i个元素就是将首元素的地址加上i并解引用来实现的访问,但是deque则是先将i的值1减去第一个buffer中的数据个数,再将得到的值除以buffer的容量,从而判断访问的数据是在第几个buffer,最后再模上buffer的容量从而得到该数据是该buffer的第几个元素,那么这就是deque随机访问的原理,他没有vector容器那么快那么直接但是他不用像list一样得先遍历一部分数组才能访问到指定位置的元素,deque在中间位置插入删除元素的时候没有像list一样能够做到一个数据都不挪动,他也得挪动数但是他没有像vector一样一大块一大块的挪动数据,他是一小部分的挪动数据,并且有时候一下子插入的数据个数多了,他可能会单独开再开一个buffer来存储插入的数据,deque虽然没有采用一整段的空间来存储数据,但是他还是采用了部分连续的空间来存储数据,这就是使得deque的空间利用率比list要高但是比vector要低,deque的cpu高速缓冲命中率比list要高但是比vector还是要低一点,那么看到这里想必大家知道deque这个容器是一个什么样子的存在了,他就相当于一个中间的存在,既没有很明显的优点也没有很明显的缺点,那么这就是deque的介绍。
deque的迭代器
deque的迭代器可以细分为四个元素,如下图所示:
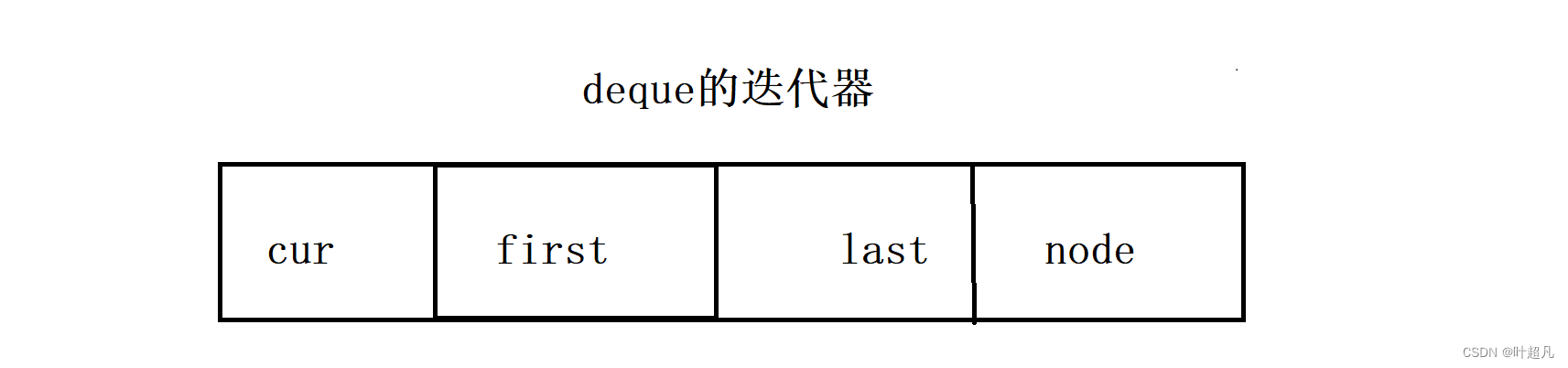
这四个元素都是指针,cur表明当前迭代器所指向的元素,first表明当前buffer的第一个元素,last表明当前buffer的最后一个元素,node则是表明当前迭代器所指向的第几个buffer,这里大家可以根据下面的图片来了解
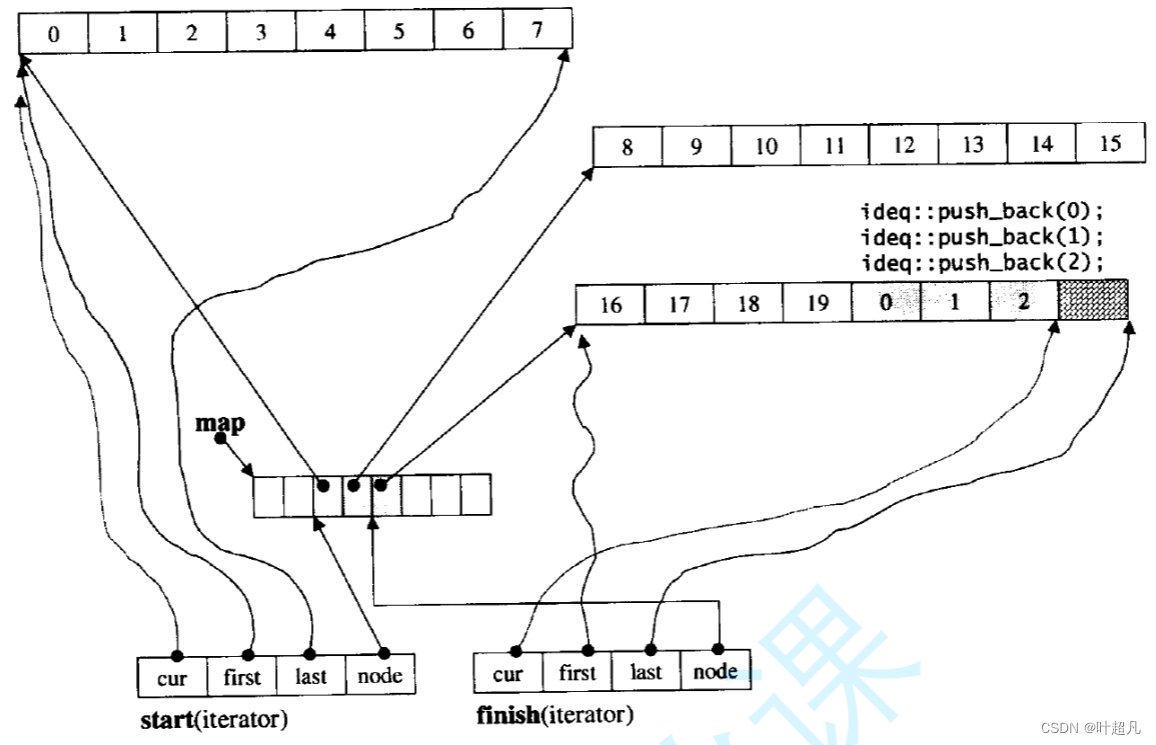
当我们对迭代器进行++时,实际上就是挪动cur指针,使其指向下一个元素,当对迭代器进行解引用时就是拿到cur所指向的元素,当cur的值等于last的值时候,如果还要对迭代器进行++的话那么就会改变迭代器的中的node使其指向下一个buf,然后修改迭代器中的last和first指针使其指向新buf的最后一个元素和第一个元素,最后再修改cur的值让其跟first的值相等,那么这就是deque的迭代器的原理希望大家能够理解。
为什么使用deque
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可
以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有
push_back和pop_front操作的线性结构,都可以作为queue的底层容器,比如list。但是STL中对stack和
queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的元素增长
时,deque不仅效率高,而且内存使用率高。结合了deque的优点,而完美的避开了其缺陷。那么以上就是本篇文章的全部内容希望大家能够理解。