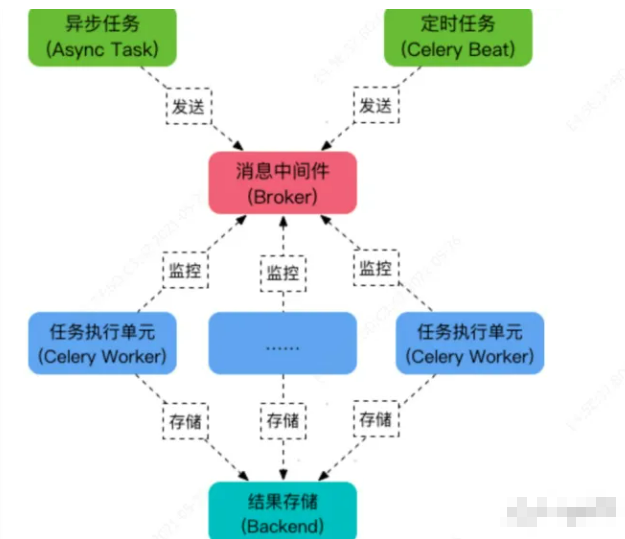
文章目录
- 前言
- 思路
- 资产收集
- 资产收集
- http服务自动攻击利用
前言
好久没有写blog了,最近在上班干活,最近抽空研究了一下自动化渗透测试,下面分享一下
思路
资产收集
传统的资产收集都是跟域名挂钩,域名收集的好坏也至关重要,这里我使用了下面一个老哥的ICP备案查询工具
ICP-Checker
大致使用方法如下
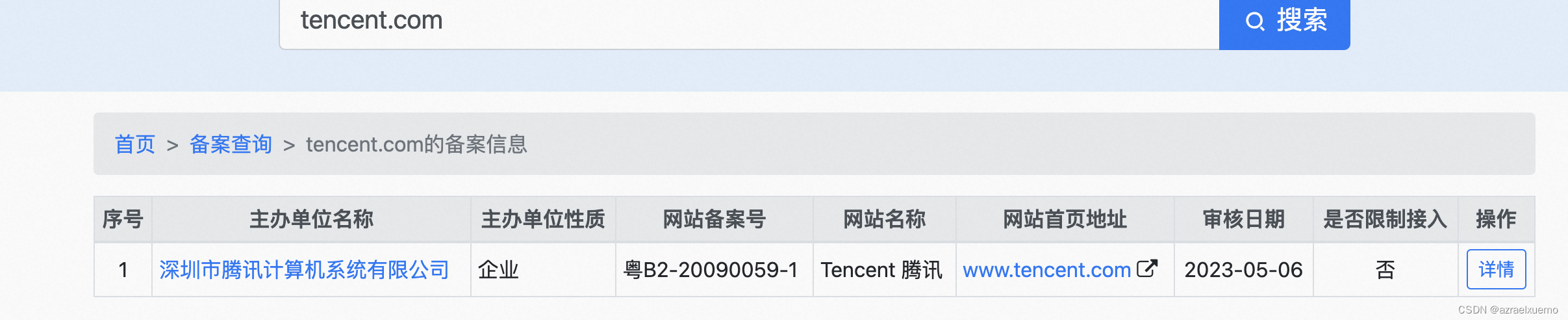
比如说我们的靶标是腾讯,我们可以通过备案查询先获取主办单位名称
tencent.com备案
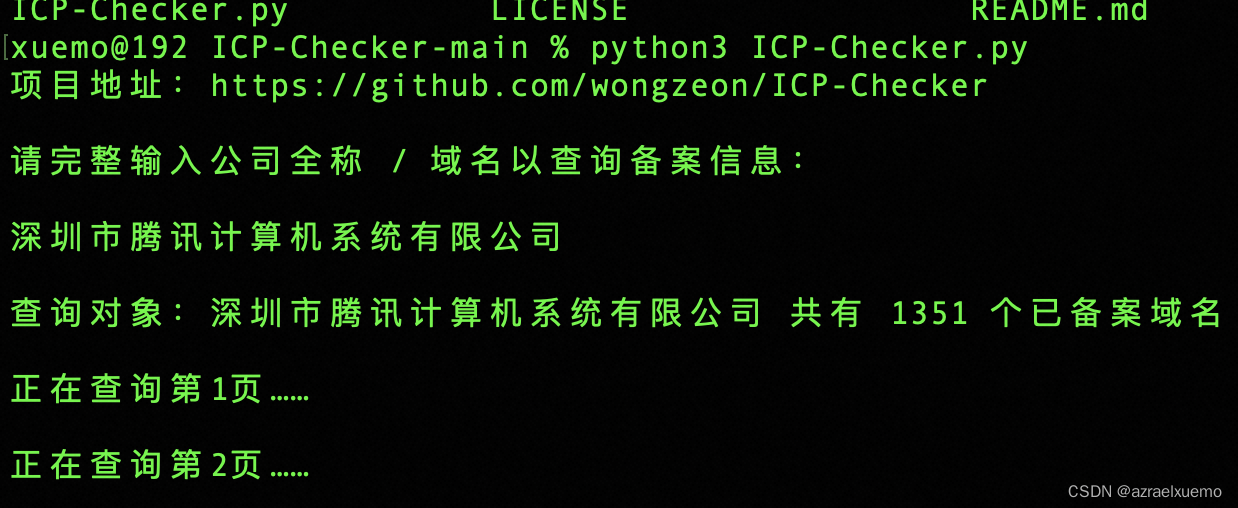
然后我们使用工具,输入完整公司名字,他会把公司注册的所有根域名dump下来,保存在备案信息.xlsx
等他下载完之后,我们打开xlsx,这里我随便找了个公司,腾讯域名太多了,然后我们把域名复制过来,保存为xxx.domain

由于域名可能会重复,我们可以用下面脚本去重,修改好file_name运行就好
import os
file_name = "xxx.domain"
os.system(f"cat {file_name}|sort|uniq -u >test.txt")
os.system(f"mv test.txt {file_name}")
然后总的根域名都收集好了
资产收集
这里我有很多种方法,今天介绍一个比较快,适合有钱人的方法,就是直接利用fofa的api
# -*- coding: utf-8 -*-
import requests
import base64
import time
import os
email =
apikey =
for file in os.listdir('.'):
if '.domain' in file:
domain_file = file
break
def get_fofa_result(query_str, fields="", page=1, size=100):
payload = base64.b64encode(query_str.encode()).decode()
url = f'https://fofa.info/api/v1/search/all?email={email}&apikey={apikey}&qbase64={payload}&fields={fields}&page={page}&size={size}'
for i in range(1, 1000, 1):
res = requests.get(url)
if res.json().get('error') == True:
if 'F点余额不' in res.json().get('errmsg'):
return ""
else:
time.sleep(i)
else:
return res.json()
def get_total_count(query_str):
return get_fofa_result(query_str)['size']
def save_result(query_str, total_count):
step = max(1000, total_count//50)
step = min(10000, step) # 防止过大
for i in range(0, total_count, step):
res = get_fofa_result(query_str, "protocol,host", 1+i//step, step)
if res == "":
print(query_str+" is too large,and can not download")
return
for protocol, host in res['results']:
if protocol == "http" or protocol == "https":
if protocol == "http":
host = "http://"+host
with open(domain_file.replace("domain", "url"), "a") as f:
f.write(host+"\n")
else:
with open(domain_file.replace("domain", "service"), "a") as f:
f.write(protocol+" "+host+"\n")
with open(domain_file, "r") as f:
for domain in f.read().split():
query_str = f'domain="{domain}"'
count = get_total_count(query_str)
print(domain)
if count == 0:
continue
else:
save_result(query_str, count)
这里我写的比较简单,里面由于api数量的限制可能会出现error,然后可以在get_fofa_result里面自己在处理一下就好,比如说我就还会遇到今日api已达到上线,这种只能exit
直接运行就好

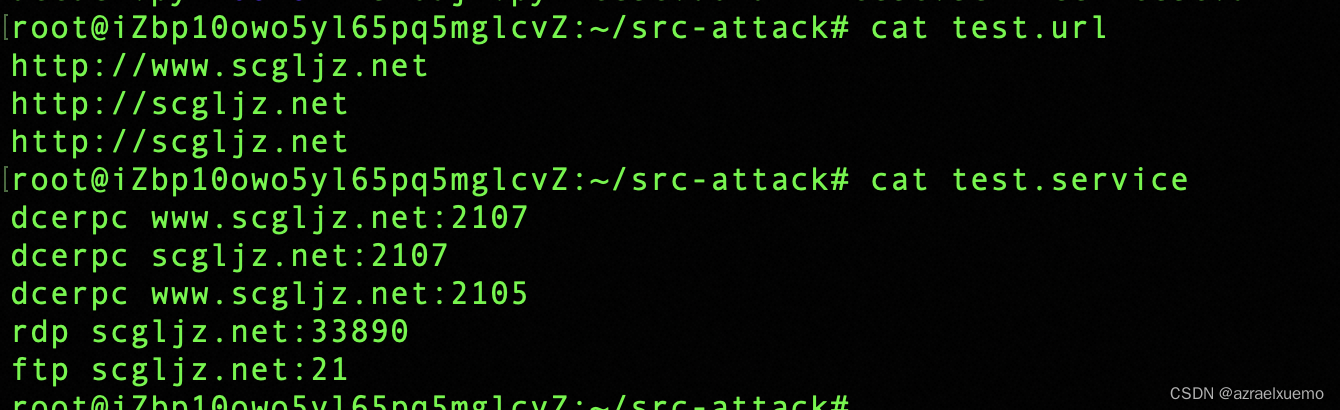
test.url里面就是可以访问的url,service就是除了http服务其他的一些服务,这里我主要进行http服务的自动化利用
http服务自动攻击利用
这里主要是利用nuclie加上fscan进行漏洞探测,还可以加上xray,但是xray误报很多,而且运行的时候还会生成一些奇怪的config,就没有加上,同时我配置了notify以及dingding机器人,方便直接同步结果
import os
import requests
from threading import Thread
for file in os.listdir('.'):
if '.url' in file:
url_file = file
break
def nuclei():
os.system(
f"nuclei -stats -et ssl/weak-cipher-suites.yaml -l {url_file} -rl 1000 -bs 35 -c 50 -mhe 10 -ni -o res-tmp.txt -severity critical,medium,high | notify -silent")
def fscan():
os.system(f"fscan -uf {url_file}")
if os.path.exists("result.txt") == False:
os.system("echo 'fscan do not scan any inforamtion'")
return
os.system(
'cat result.txt|grep "\[+\]"|grep -v "\[KONA\]"|grep -v "\[Varnish\]"|grep -v "\[Cloudfront\]"|grep -v "\[CloudFlare\]" >sucess.txt')
if int(os.popen("cat sucess.txt|wc -l").read()) > 0:
with open("sucess.txt", "r") as f:
for line in f.read().split("\n"):
if line == "":
continue
content = {"msgtype": "text", "text": {"content": line}}
requests.post(
'https://oapi.dingtalk.com/robot/send?access_token=aaaa', json=content)
t1 = Thread(target=nuclei)
t2 = Thread(target=fscan)
t1.start()
t2.start()
t1.join()
t2.join()
然后我们这样运行就好
直接python3 attack.py运行就好,这里我url太少,就没有结果
我之前也做了一整套自动化利用,当时是挖h1,那个自动化程度比较高,基本都没用自己动,当然域名收集包括资产还是这种比较完善,所以我就先分享这个~
当然自动化挖src挖不出高危漏洞,高危的还是要去实际测业务,这个就图一乐