前文回顾:HBase基本工作原理
目录
📚数据仓库和OLAP
🐇数据仓库
🥕面向主题
🥕集成的
🥕时变的
🥕非易失的
🐇OLTP(联机事务处理)vs OLAP(联机分析处理)
📚Hive基本工作原理
🐇Hive和HBase的区别
🐇Hive的作用与结构组成
🐇Hive的数据模型
🥕表(Table)
🥕外部表(External Table)
🥕分区(Partition)
🥕桶(Bucket)
📚Hive查询语言——HiveQL
🐇创建数据表的命令
🐇装入数据
🐇插入数据
🐇SELECTS and FILTERS
📚Hive总结
📚数据仓库和OLAP
🐇数据仓库
- 数据仓库:用于决策支持的数据库,与组织的操作型数据库独立的运行维护。
数据仓库是一个面向主题的、集成的、时变的、非易失性的数据集合,用于支持管理决策过程。

🥕面向主题
- 数据表围绕着主题组织,如客户、产品、销售等主题。
- 面向决策者,聚焦于数据建模与分析, 而不是日常的业务操作或事务处理。
- 围绕特定的主题,提供一个简洁的数据视图,不包括对决策支持无用的数据。
🥕集成的
- 集成多个异质数据源来构建,关系数据库,文件,在线交易记录。
- 应用数据清洗和数据集成技术,对不同的数据源,确保集成后在命名规范、编码结构、属性量纲等方面的一致性,如酒店价格、货币、税、 是否含早餐等等。
- 数据需在转换后,移入到数据仓库。
🥕时变的
- 数据仓库的时间跨度比操作型数据库长得多。操作型数据库:关注当前数据;数据仓库数据:从历史的角度提供信息(例如,过去5-10年)
- 数据仓库中的每一个关键结构,显式或隐式的包含时间元素,但是操作数据的键可能包含或不包含“时间元素”。
🥕非易失的
- 从操作环境转换来的物理独立的数据存储。
- 数据的操作更新不会出现在数据仓库环境中,不需要事务处理、恢复和并发控制机制,在数据访问中只需要两个操作——数据的初始加载和数据的存取。
🐇OLTP(联机事务处理)vs OLAP(联机分析处理)

- OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
- OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
- OLTP实时性要求高,OLAP具有共享多维信息的快速分析的特征。
📚Hive基本工作原理

🐇Hive和HBase的区别
| HBase | Hive |
|---|---|
| 一种NoSQL数据库,最常见的应用场景是采集网页数据的存储。 | 一个构建与Hadoop顶层的数据仓库工具,对存储在Hadoop文件中的数据集进行数据整理、查询和分析处理。 |
| 由于是key-value型数据库,可以再扩展到各种key-value应用场景,如日志信息的存储。 | Hive提供一个统一的查询分析层,支撑连接、分组、聚集等类SQL语句,可以看作是用户编程接口。 |
| 主要针对OLTP应用。 | 主要针对OLAP应用。 |
🐇Hive的作用与结构组成

- Hive构建于分布式文件系统HDFS之上,提供了一种类似于SQL的数据查询分析查询接口。
- 它能够将类似于SQL的查询语句(HiveQL)转换为一个或多个MapReduce程序,从而大大简化数据查询分析过程中的应用程序开发难度。
⭐Hive的系统结构

- 用户接口层(Client):负责接收用户输入的指令,并将这些指令发送到Hive引擎进行数据处理。用户接口层包括命令行接口CLI、数据库访问编程接口JDBC/ODBC以及Web界面(Web UI)。
- 元数据存储层(Metastore):用于存储Hive中的Schema表结构信息,存储操作的数据对象的格式信息、在HDFS中的存储位置的信息以及其他的用于数据转换的信息SerDe等。
- Hive驱动(Driver):用于将各个组成部分形成一个有机的执行系统,包括会话的处理、查询获取以及执行驱动。
- 编译器(Compiler):Hive需要一个编译器,将HiveQL语言编译成中间语言表示。编译器包括对于HiveQL语言的分析、执行计划的生成以及优化等工作。
- 执行引擎(Execution Engine):在Driver的驱动下,具体完成执行操作,包括MapReduce的执行、HDFS操作或者元数据操作。
- Hadoop数据存储及处理平台:从Hive引擎接收指令,并最终通过HDFS、HBase,配合MapReduce实现数据处理。
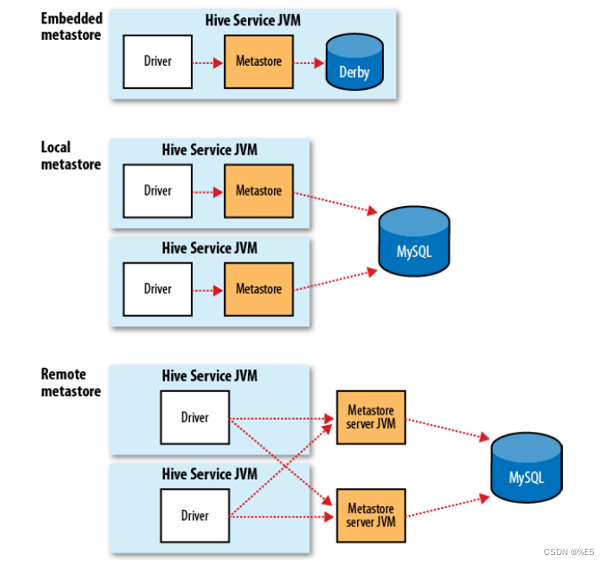
关于元数据存储:Metastore
- 在Hive中由一系列的数据表格组成一个命名空间,关于这个命名空间的描述信息会保存在Metastore的空间中。
- 元数据使用SQL的形式存储在传统的关系数据库中,因此可以使用任意一种关系数据库,例如Derby(apache的关系数据库实现),MySQL以及其他的多种关系数据库存储方法。
- 在数据库中,保存最重要的信息是有关数据库中的数据表格描述,包括每一个表的格式定义,列的类型,物理的分布情况,数据划分情况等。

🐇Hive的数据模型
每一个类似于数据库的系统都首先需要定义一个数据模型,然后才是在这个数据模型之上的各种操作。
🥕表(Table)
- 在Hive中对于数据的管理与维护是利于表(Table)的形式实现的。Hive表在逻辑上有两部分组成,第一部分为真实数据,第二部分为描述表格中数据形式的元数据。
- Hive数据表中的列是有类型的(int, float, string, data, boolean),也可以是复合的类型,如list: map (类似于JSON形式的数据)。
- Hive表在HDFS中有固定的位置。
- Hive表创建完成以后便可以通过类SQL语句对表以及表内的数据进行相关操作。当加载数据到表内时,本质上,Hive会将数据移动到仓库目录下。因为这里是移动操作,所以当删除这张表时,该表的元数据以及数据将被删除。
🥕外部表(External Table)
- 在Hive中创建表时,默认情况下表内的数据管理由Hive负责。这样意味着Hive会将数据移动到它的“数据仓库目录”。
- 除此之外,Hive在创建表时还可以指定创建外部表。外部表是一个已经存储在HDFS文件中,并具有一定格式的数据。
- 使用外部表意味着Hive表内的数据不在Hive的数据仓库内,需要到目录以外位置访问数据
🥕分区(Partition)
- 数据表可以按照一定的规则进行划分Partition,来对表进行合理的管理以及提高查询效率。
- Hive中的每个分区对应数据库中相应分区列的一个索引,每个分区对应着表下的一个目录。
🥕桶(Bucket)
- 在一定范围内的数据按照Hash的方式进行划分(这对于数据的抽样以及对于join的优化很有意义),即取样更高效且能获取更高的查询处理效率。
数据的物理分布情况:
- Hive在HDFS中有固定的位置,通常被放置在HDFS的如下目录中:/home/hive/warehouse
- 每个数据表被存放在warehouse的子目录中。进一步来说,数据划分Partition、数据桶Buckets形成了数据表的子目录。
- 数据可能以任意一种形式存储,例如:
- 使用分隔符的文本文件,或者是SequenceFile
- 使用用户自定义的SerDe,则可以定义任意格式的文件
- SerDe说明Hive如何去处理一条记录,包括Serialize/Deserilize
- Serialize把Hive使用的Java object转换成能写入HDFS的字节序列;Deserilize把字符串或者二进制流转换成Hive能识别的Java object
📚Hive查询语言——HiveQL
DDL:CREATE, ALTER, SHOW, DESCRIBE, DROP
DML:LOAD DATA, INSERT
QUERY:SELECT
🐇创建数据表的命令
- 显示所有的数据表:hive> show tables;
- 创建一个表,这个表包括两列,分别是整数类型以及字符串类型,使用文本文件表达,数据域之间的分隔符为\t:
- hive> create table shakespeare (freq int, word string) row format delimited fields terminated by ‘\t’ stored as textfile;
- hive> create external table shakespeare (freq int, word string) location ‘user/input/hive/partitions/file1’;
创建两个表,分别为"shakespeare"和"shakespeare"(这是一个外部表)。这两个表都包含两列,分别为freq(频率)和word(单词)。这里使用了不同的数据存储格式和存储位置。
- 第一个表"shakespeare"使用了标准的文本存储格式,并使用制表符分隔不同的字段。这个表可以存储在Hive的默认文件系统中,也可以存储在其他支持Hive的文件系统中。
- 第二个表"shakespeare"是一个外部表,使用了外部数据源中指定的存储位置"‘user/input/hive/partitions/file1’"。这个表的数据并不存储在Hive的默认文件系统中,而是使用外部数据源中定义的数据存储方式。
- 显示所创建的数据表的描述,即创建时候对于数据表的定义:hive> describe shakespeare;
🐇装入数据
- 数据装入到Hive表中:hive> load data inpath “shakespeare_freq” into table shakespeare;
🐇插入数据
- Hive表插入数据:hive> INSERT OVERWRITE TABLE pokes_b SELECT a.* FROM pokes a;
- INSERT语句用于插入(添加)数据到表中,而INSERT OVERWRITE语句是一种覆盖写入方式,表示将表pokes_b中所有的数据都清空,然后将表pokes中的数据直接写入到表pokes_b中。
- 在本例中,SELECT语句用于选择表pokes中的所有数据,并使用通配符*表示选择所有的列。最后,使用FROM子句指定要选择的表的名称a。
- 因此,这条SQL语句的含义是将表pokes中的所有数据添加或覆盖到表pokes_b中。
- 查询结果写入文件目录:
- hive> INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='2008-08-15';
- hive> INSERT OVERWRITE LOCAL DIRECTORY '/tmp/local_out' SELECT a.* FROM pokes a;
- 第一条语句将invites表中ds字段为2008-08-15的记录插入到HDFS中的临时文件夹/tmp/hdfs_out中。其中,INSERT OVERWRITE DIRECTORY表示覆盖写入、写入目标为文件夹;SELECT a.* FROM invites a WHERE a.ds='2008-08-15'表示选取满足条件的所有字段数据。
- 第二条语句将pokes表中所有记录插入到本地文件系统中的临时文件夹/tmp/local_out中。其中,INSERT OVERWRITE LOCAL DIRECTORY表示覆盖写入、写入目标为本地文件夹;SELECT a.* FROM pokes a表示选取所有字段数据。
🐇SELECTS and FILTERS
- 简单查询(不会调用到MapReduce):hive> select * from shakespeare
- 条件查询(自动调用MapReduce):
- hive> select * from shakespeare where freq > 100 sort by freq asc limit 10;
- hive> SELECT a.foo FROM invites a WHERE a.ds='2008-08-15';
其他的先不列了,感觉就是SQL ——> HiveQL语法手册
📚Hive总结
- Hive提供了一种类似于SQL的查询语言,使得其能够用于用户的交互查询。
- 与传统的数据库类似,Hive提供了多个数据表之间的联合查询,能够完成高效的多个数据表之间的查询。
- 通过底层执行引擎的工作,Hive将SQL语言扩展到很大的查询规模。