文章目录
- 前言
- 实现
- 创建内存池
- 分配内存
- 释放内存
- 总结
前言
Kafka的内存池是一个用于管理内存分配的缓存区域。它通过在内存上保留一块固定大小的内存池,用于分配消息缓存、批处理缓存等对象,以减少频繁调用内存分配函数的开销。
Kafka内存池的实现利用了Java NIO中的 ByteBuffer。当需要创建一个新的缓存对象时,内存池会取出一块固定大小的内存块,并在存储内存池对象的池中保存该内存块的引用。当该内存块不再被使用时,内存池将把它收回,以供下一次使用。
使用内存池可以提高Kafka生产者的性能,因为对象kafka这样的消息中间件,需要频繁地创建对象,我们知道频繁地创建对象很消耗内存,使用内存池可以减少内存的消耗,此外,内存池还可以减少内存碎片的产生,提高内存使用效率。
实现
下面我们从几个方面来对象内存池的实现进行详细介绍。
创建内存池
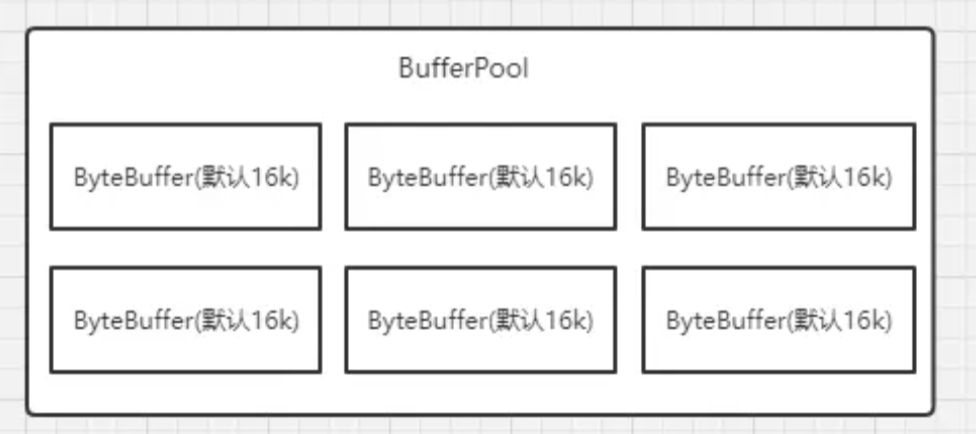
在kafka初始化的时候,会对内存池进行初始化,在Kafka Producer端,有一个BufferPool,与它相关的配置参数是buffer.memory和batch.size,buffer.memory它代表缓冲区内存的大小,默认为32M,batch.size代表消息批次的大小,默认为16kb,在BufferPool中,batch.size其实就是代表一个ByteBuffer的大小,因为BufferPool只管理batch.size大小的ByteBuffer,在kafka初始化的时候,就会创建缓冲区(new BufferPool),如下,在创建消息收集器RecordAccumulator的时候,就创建了BufferPool。
this.accumulator = new RecordAccumulator(logContext,
batchSize,
this.compressionType,
lingerMs(config),
retryBackoffMs,
deliveryTimeoutMs,
partitionerConfig,
metrics,
PRODUCER_METRIC_GROUP_NAME,
time,
apiVersions,
transactionManager,
new BufferPool(this.totalMemorySize, batchSize, metrics, time, PRODUCER_METRIC_GROUP_NAME));
分配内存
我们知道kafka的消息不是直接发送到broker,而是先发送到消息收集器RecordAccumulator,而消息发送到RecordAccumulator,是需要先申请内存的,如果消息的大小大于内存池BufferPool的大小,那么这是不允许的,会抛出异常,比如我的消息的大小时40M,但是内存池的大小是32M,那么显然BufferPool装不下消息,就会报错。
我们说了消息是被存储在队列中,以ProducerBatch的形式,当发送消息时,获取分区对应的队列,入队队列不存在,就创一个队列,这个队列就是装ProducerBatch的队列,为Deque,然后从队列中取出一个ProducerBatch,如果存在ProducerBatch,那么
就判断这个ProducerBatch是否足够装得下消息,如果能够装得下,那么就将消息装入,如果装不下,那么就重新创建一个ProducerBatch,然后将消息加入新创建的这个ProducerBatch,最后将这个ProducerBatch加入队列中,然后释放掉ProducerBatch,其实就是释放掉ByteBuffer中的ProducerBatch,因为ProducerBatch本身就是由ByteBuffer来进行承载。
如果消息的长度大于16kb(注意,这个16kb是batch.size参数的默认值,如果我们对batch.size进行设置,那么就按照我们设置的值来算),那么就按消息的实际大小来进行创建,如果小于或等于16kb,那么就按照16kb来进行创建,如下代码所示,会将batchSize和我们消息的大小进行比较,选出最大的,然后去分配Buffer。
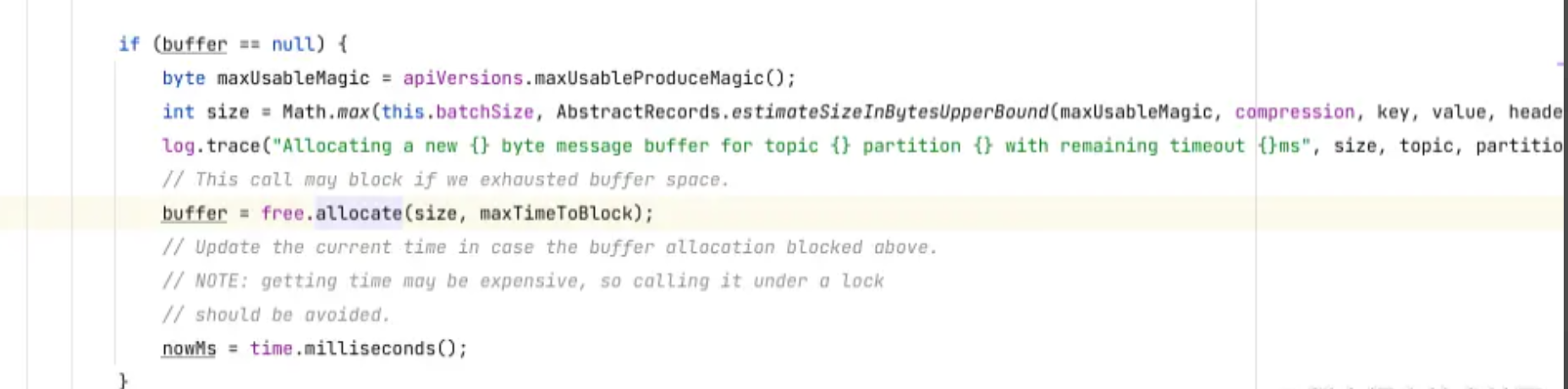
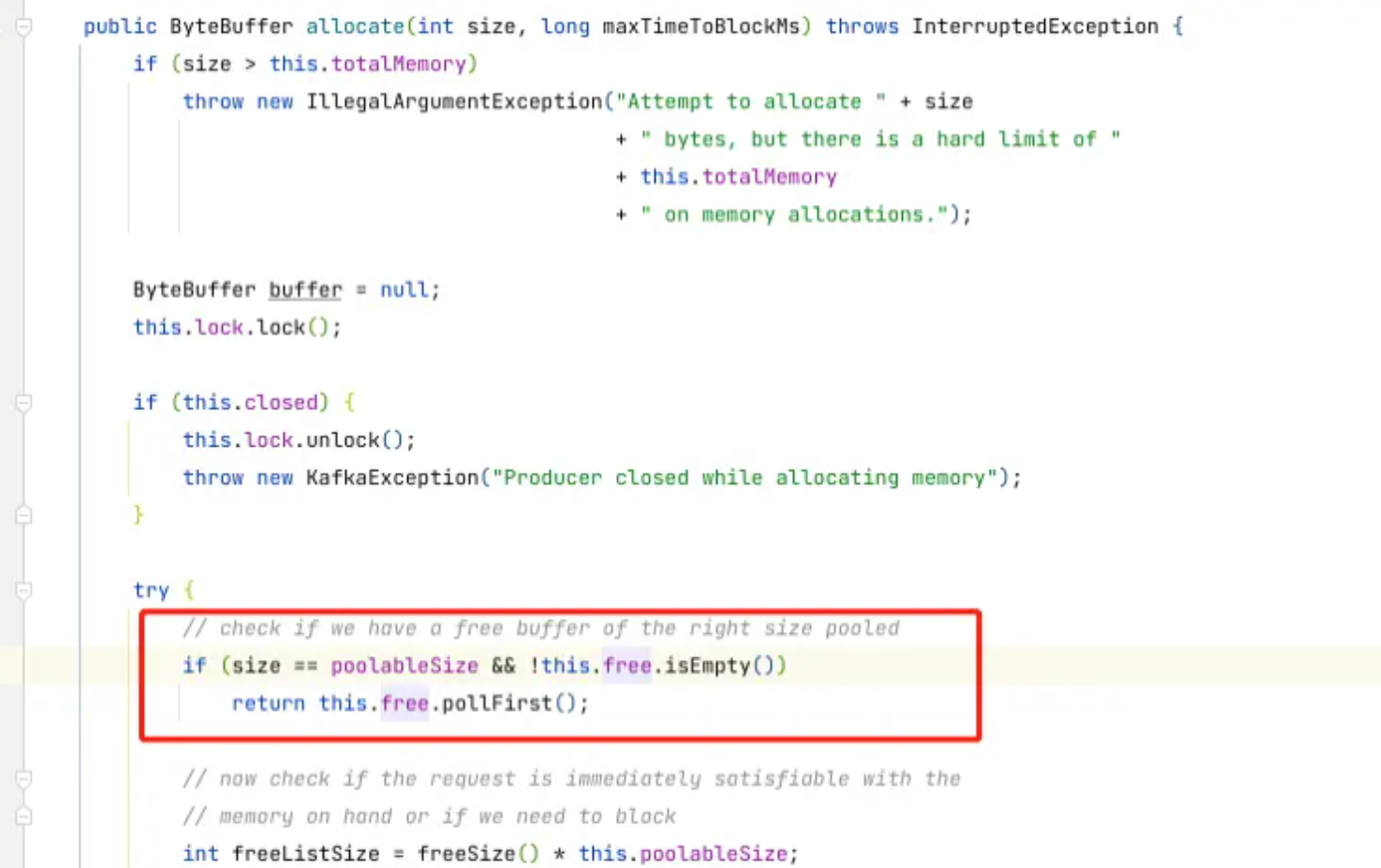
我们知道ProducerBatch是放在ByteBuffer中,所以在创建ProducerBatch的时候,会去申请一个ByteBuffer,如果我们的消息小于或者等于batch.size(默认为16kb),那么就会去缓冲池BufferPool中取一块ByteBuffer来给ProducerBatch使用,如上图所示,这些ByteBuffer都被缓冲池BufferPool管理起来,如果我们的消息大于batch.size,那么就无法使用缓冲池中的ByteBuffer了。如下,在allocate方法中,如果我们消息所需要的ByteBuffer的大小等于poolableSize并且BufferPool中存在ByteBuffer,那么久直接从BufferPool的队列中获取一个ByteBuffer,poolableSize其实就是batch.size。
释放内存
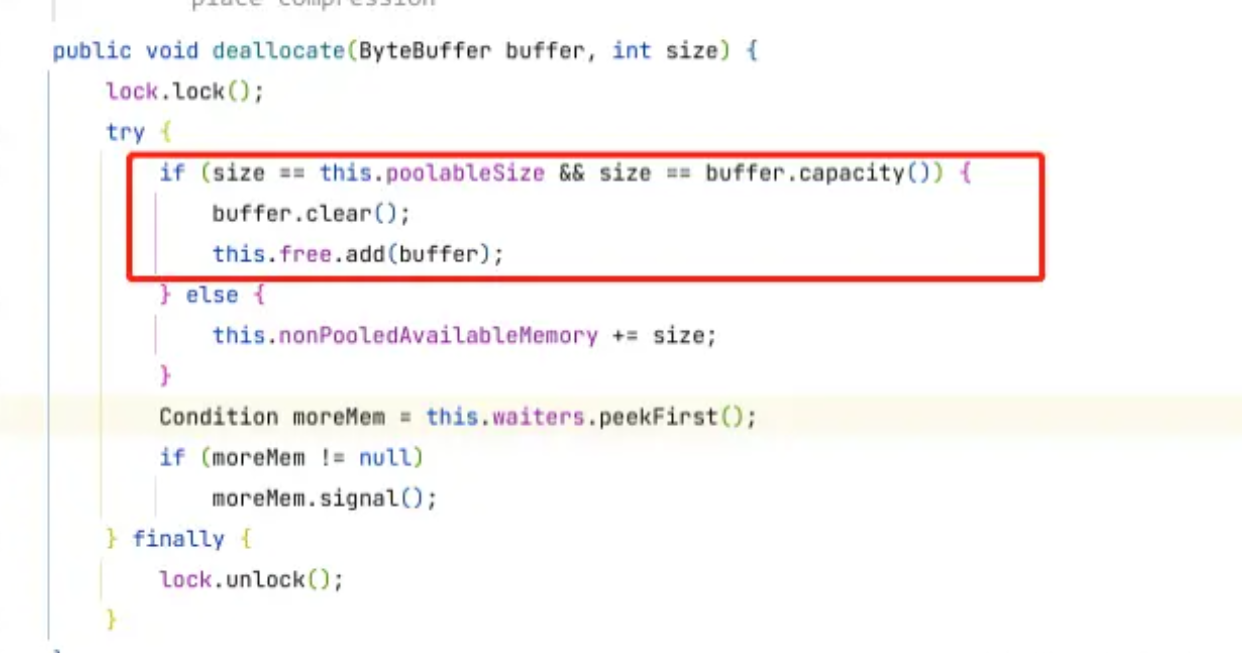
当我们消息发送完以后,就需要释放ByteBuffer,然后再将ByteBuffer加入到BufferPool中,以供后面使用,注意,只有batch.size大小的ByteBuffer才能加入BufferPool中,后面才能复用,大于batch.size的ByteBuffer不能加入BufferPool中,大于batch.size的则和非缓冲池的内存有关,和nonPooledAvailableMemory这个值有关,就不去详细说它,如下,通过buffer.clear()清空ByteBuffer,然后将清空后的buffer加入队列中。
总结
上面我们对kafka的为什么使用内存池,使用内存池的好处进行了分析,然后对它怎么实现进行了分析,分别从创建,使用和释放去进行详细说明,不过我们应该记住的是,kafka使用内存池的条件是我们的消息的大小必须小于等于batch.size的值,这样内存池才能发挥它的作用,如果我们的消息很大,然而也没对batch.size进行设置,使用的是默认值,那么将不能使用内存池,不能发挥它的性能。








![String [中]](https://img-blog.csdnimg.cn/9ad929f00e3643bf89ff72ab5c52b1e8.png)