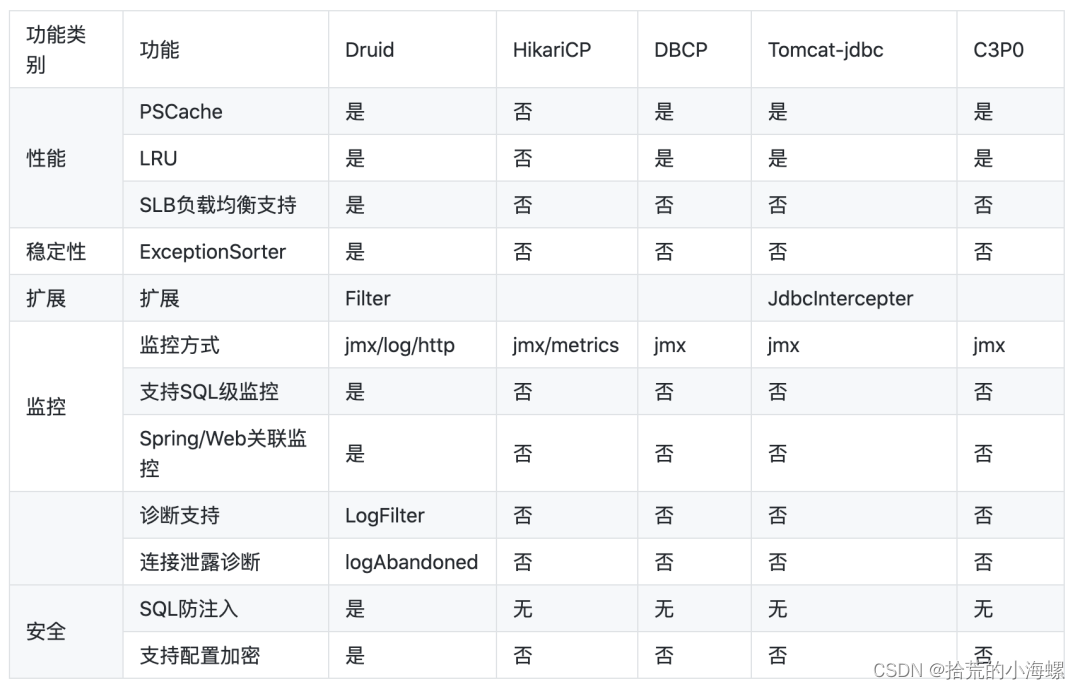
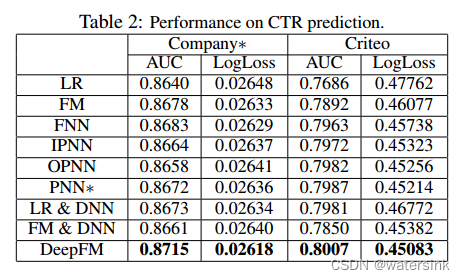
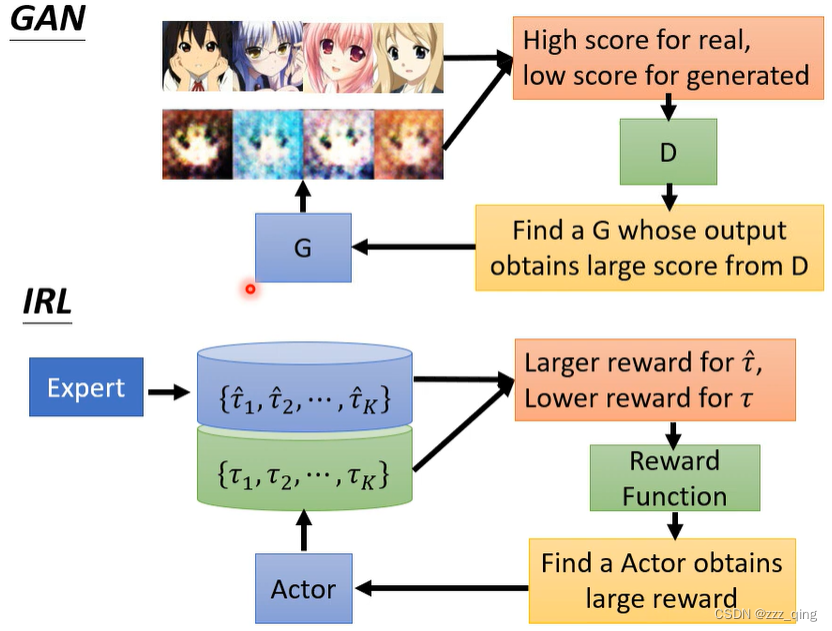
目录
Story 1: Cross-lingual
Story 2: Cross-discipline
Story 3: Pre-training with artificial data
(story1和story2的内容在前面课程中有讲过,这里笔记部分不再详述)
Story 1: Cross-lingual
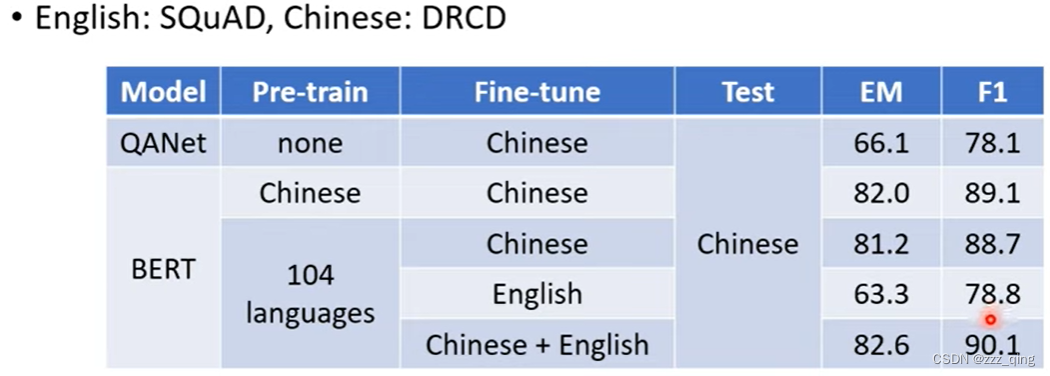
多语言BERT具有跨语言的能力,例如fine-tune在英文上,testing在中文上:

实验结果如下:
multilingual BERT不只是把不同语言同样意思的词汇对应在一起,它还存有语言的资讯
Story 2: Cross-discipline
self-supervised model不只有跨语言的能力,它还有跨学科的能力:
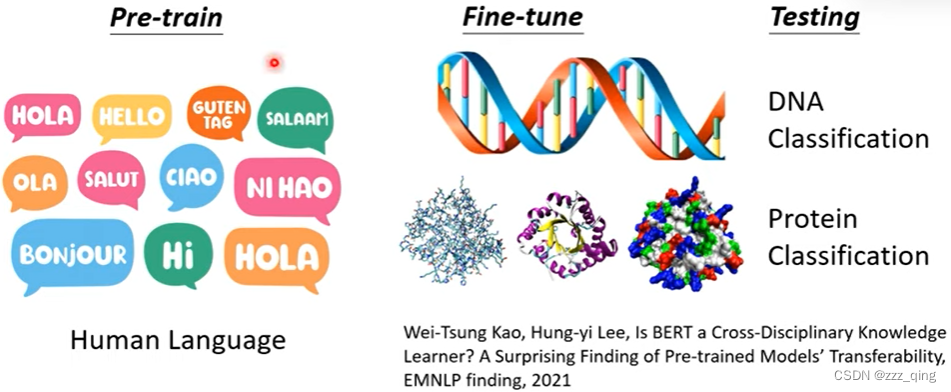
例如,用pre-train在英语上的BERT做DNA分类:
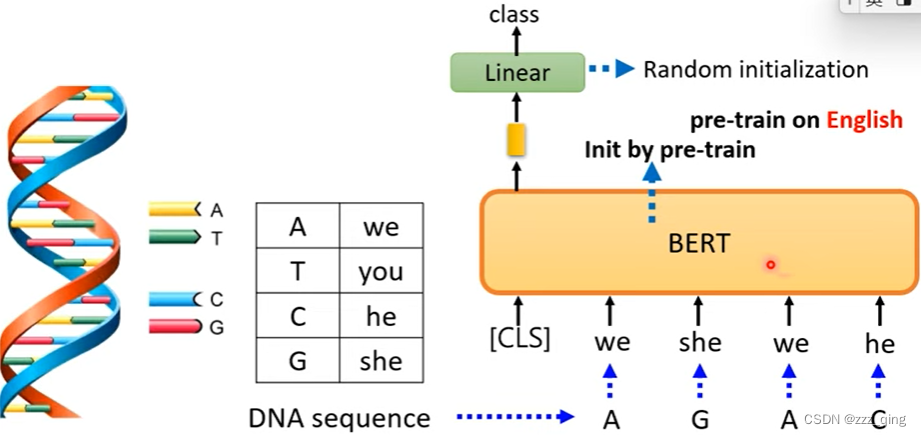
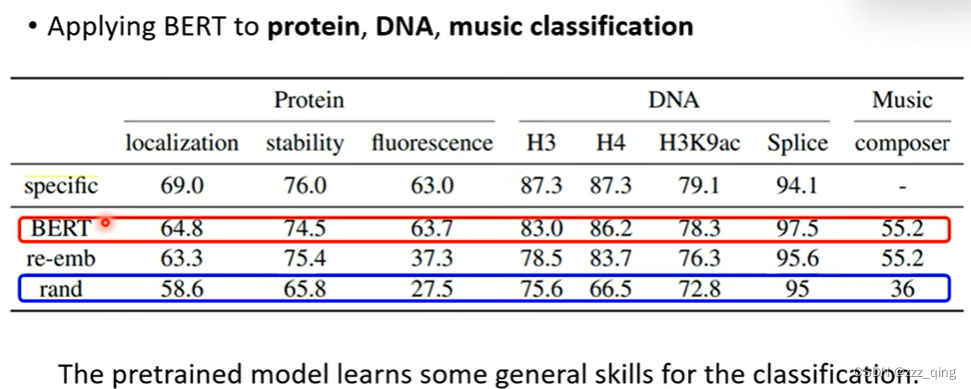
下图结果表明,在人类语言上pre-train,对于DNA的任务,在optimization和generalization上都有帮助:

跨学科的能力的应用举例——speech question answering:
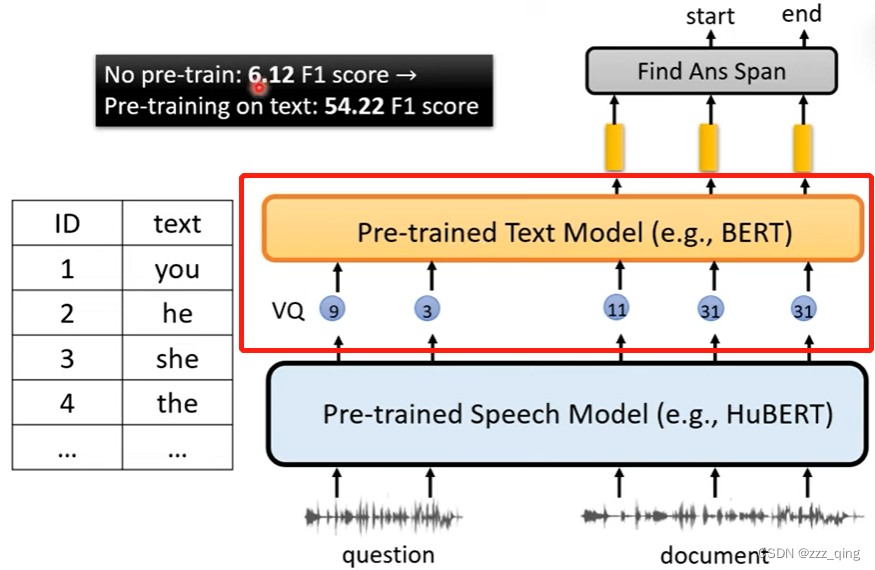
上图中的model把speech question answering做起来,可以得到54 percent的F1 score。下图表格中绿色的线,代表先做语言辨识(把声音讯号转成文字),再在文字上面做question answering,它的正确率显然受到语音辨识正确率的影响。当语言辨识错误率为25%以上的时候,绿色线的F1 score就低于54 percent:

Story 3: Pre-training with artificial data
——在人造的资料上训练出BERT:
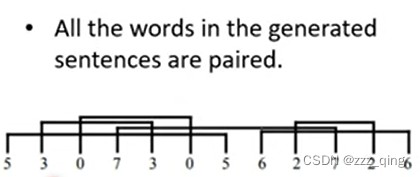
Pre-training on Artificial Data:
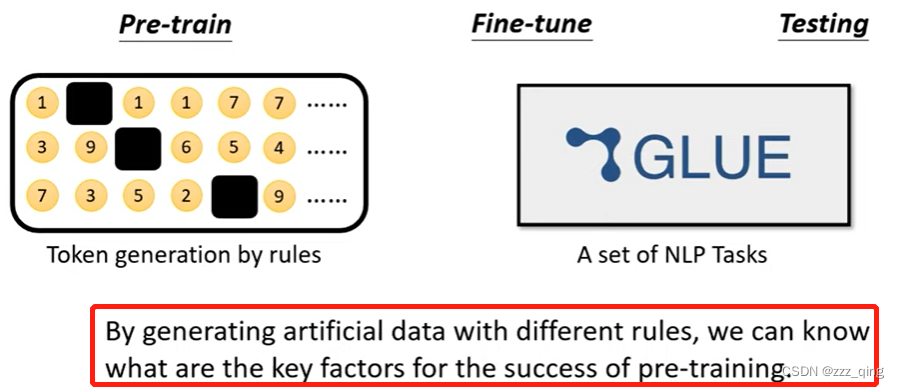

实验结果如下:

Pre-training on random tokens yields the same performance as training from scratch.——说明Data plays the role.