Linux诊断原因,生产环境服务器变慢,诊断思路和性能评估
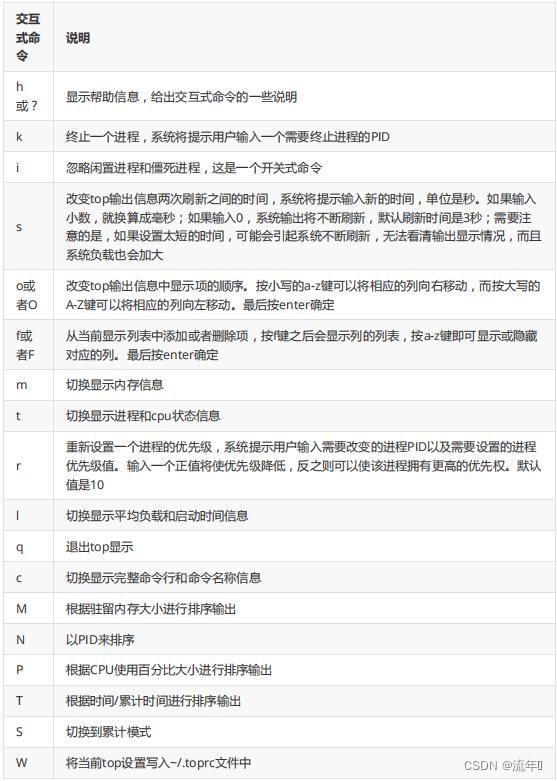
1 整机:top,查看整机系统性能

使用top命令的话,重点关注的是 %CPU、%MEM 、load average 三个指标
-
load average三个指标:分别代表1、5、15时分钟系统的负载情况,在这个命令下,按1的话,可以看到每个CPU的占用情况
uptime:系统性能命令的精简版
2 CPU:vmstat
查看CPU(包含但是不限于): vmstat

命令格式:
vmstat -n 2 3
一般vmstat工具的使用是通过两个数字参数来完成的,第一个参数(如上面的参数2)是采样的时间间隔数(单位秒),第二个参数(如上面的参数3)是采样的次数。我们可以将每次采样求平均值进行判断。
参数解析:
procs
r:运行和等待的CPU时间片的进程数,原则上1核的CPU的运行队列不要超过2,整个系统的运行队列不超过总核数的2倍,否则代表系统压力过大。
b:等待资源的进程数,比如正在等待磁盘I/O、网络I/O等
cpu
us:用户进程消耗CPU时间百分比,us值高,用户进程消耗CPU时间多,如果长期大于50%,需优化程序
sy:内核进程消耗的CPU时间百分比

us + sy 参考值为80%,如果us + sy 大于80%,说明可能存在CPU不足,从上面的图片可以看出,us + sy还没有超过百分80,因此说明CPU消耗不是很高
id:处于空闲的CPU百分比
wa:系统等待IO的CPU时间百分比
st:来自于一个虚拟机偷取的CPU时间比
查看所有CPU核信息
命令:
mpstat -P ALL 2

查看某个进程使用CPU的用量分解信息
命令:
pidstat -p 进程编号 -u 采样间隔秒数
pidstat 命令详解: https://www.jianshu.com/p/3991c0dba094
需求:查看某个java进程的cpu的使用情况
步骤:
1、使用ps -ef | grep java 找出相关进程号
2、使用 pidstat -p 进程编号 -u 采样间隔秒数 查看信息

3 内存:free
-
应用程序可用内存数:free -m
-
应用程序可用内存/系统物理内存 > 70% 内存充足
-
应用程序可用内存/系统物理内存 < 20% 内存不足,需要增加内存
-
20% < 应用程序可用内存/系统物理内存 < 70%,表示内存基本够用
free -h:以人类能看懂的方式查看物理内存

free -m:以MB为单位,查看物理内存

free -g:以GB为单位,查看物理内存,会没那么精确

4 查看某个进程使用内存的用量分解信息
pidstat -p 进程号 -r 采样间隔秒数
查看某个java进程的内存使用情况
步骤:
1、查看进程号: ps -ef | grep java
2、根据进程号查看这个进程的内存使用情况:pidstat -p 进程号 -r 采样间隔秒数

5 硬盘:df
格式:df -h (-h:human,表示以人类能看到的方式换算)

硬盘IO:iostat
系统慢有两种原因引起的,一个是CPU高,一个是大量IO操作
格式:iostat -xdk 2 3
说明 2 表示两秒钟取样一次,共计取样3次
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JLNlUqe1-1683440811490)(null)]
磁盘块设备分布:
rkB /s:每秒读取数据量kB;
wkB/s:每秒写入数据量kB;
svctm I/O:请求的平均服务时间,单位毫秒
await I/O:请求的平均等待时间,单位毫秒,值越小,性能越好
util:一秒钟有百分几的时间用于I/O操作。接近100%时,表示磁盘带宽跑满,需要优化程序或者增加磁盘;
rkB/s,wkB/s根据系统应用不同会有不同的值,但有规律遵循:长期、超大数据读写,肯定不正常,需要优化程序读取。
svctm的值与await的值很接近,表示几乎没有I/O等待,磁盘性能好,如果await的值远高于svctm的值,则表示I/O队列等待太长,需要优化程序或更换更快磁盘
查看某个进程使用内存的用量分解信息
pidstat -p 进程号 -d 采样间隔秒数

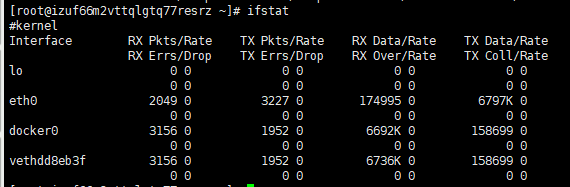
6 网络IO:ifstat
- 默认本地没有,下载ifstat

![[svg-icon]引入vue项目后,use标签为0,已解决](https://img-blog.csdnimg.cn/0f3c2f769e604847beaa5f15829cd06e.png)