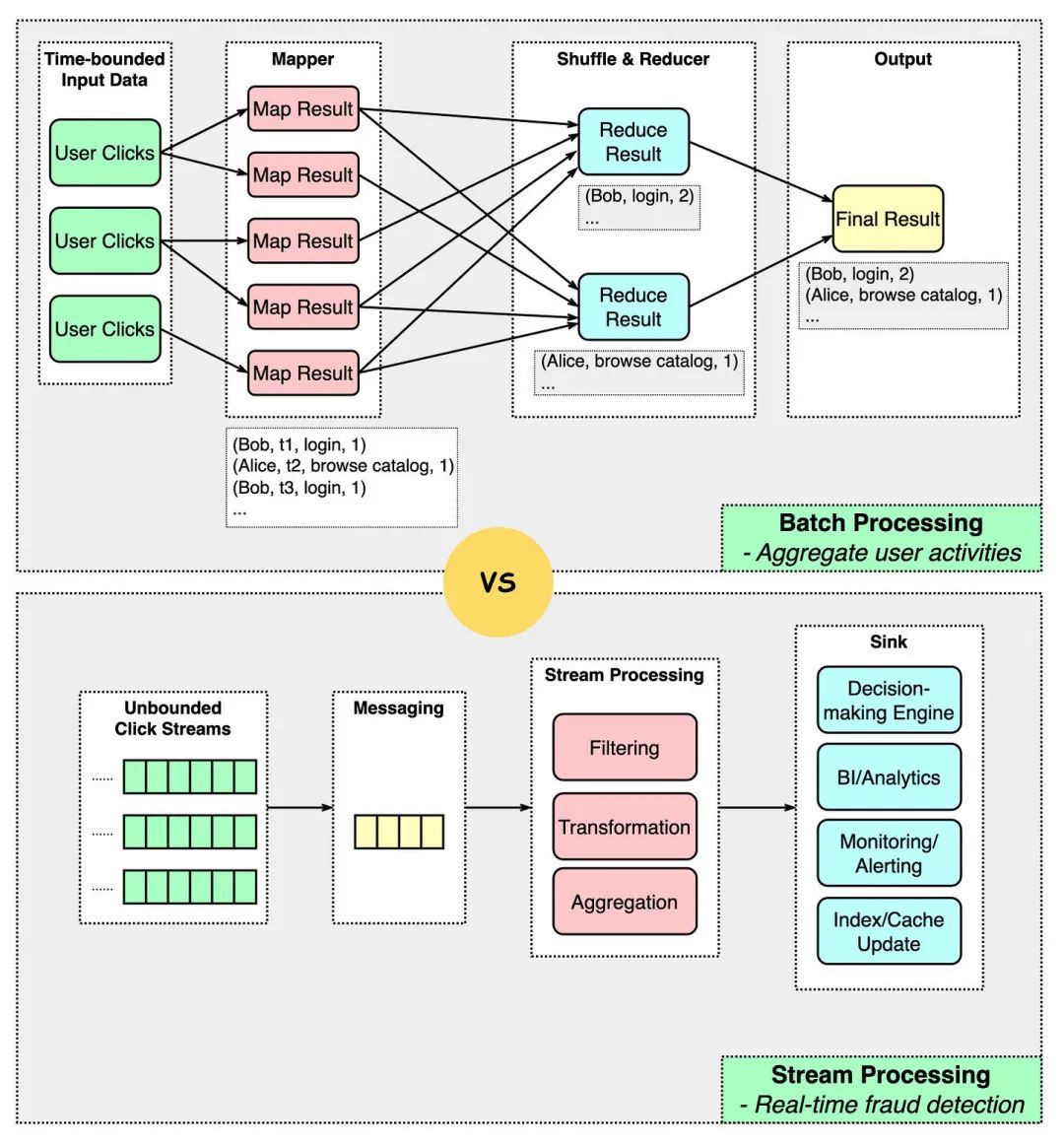
当处理大数据时,通常使用批处理和流处理两种模型。它们的主要区别如下:
1.输入
批处理处理的是时间边界确定的数据,也就是输入数据有一个结尾。
流处理处理的是数据流,没有明确定义的边界。
2.实时性
批处理通常用于数据不需要实时处理的场景。
流处理可以随着数据的产生即时生成处理结果。
3.输出
批处理通常生成一次性结果,例如报告。
流处理的输出可以输入到欺诈决策引擎、监控工具、分析工具或索引/缓存更新器中。
4.容错性
批处理更容易容忍故障,因为批次可以在一组固定的输入数据上重放。
流处理更具挑战性,因为输入数据不断流入。有一些方法可以解决这个问题:
a)微批处理将数据流分成较小的块(用于Spark);
b)检查点每隔几秒钟生成一个标记以进行回滚(用于Flink)。
以下是使用Apache Spark进行批处理和流处理的Python代码示例:
批处理
from pyspark.sql import SparkSession
# 创建SparkSession
spark = SparkSession.builder.appName("Batch Processing").getOrCreate()
# 读取数据
df = spark.read.format("csv").option("header", "true").load("/path/to/input")
# 数据处理
processed_df = df.filter(df["clicks"] > 100)
# 结果输出
processed_df.write.format("csv").option("header", "true").save("/path/to/output")
# 停止SparkSession
spark.stop()流处理
from pyspark.sql import SparkSession
from pyspark.sql.functions import window
# 创建SparkSession
spark = SparkSession.builder.appName("Stream Processing").getOrCreate()
# 读取数据流
df = spark.readStream.format("csv").option("header", "true").load("/path/to/input/stream")
# 数据处理
processed_df = df.filter(df["clicks"] > 100).groupBy(window(df["timestamp"], "1 hour")).sum()
# 结果输出到控制台
query = processed_df.writeStream.outputMode("complete").format("console").start()
# 等待处理完成
query.awaitTermination()
# 停止SparkSession
spark.stop()这里的示例代码仅供参考,具体实现取决于数据的特性和业务需求。
![[LeetCode周赛复盘] 第 344 场周赛20230507](https://img-blog.csdnimg.cn/86d2dd453c954ea48709136be958b4b4.png)