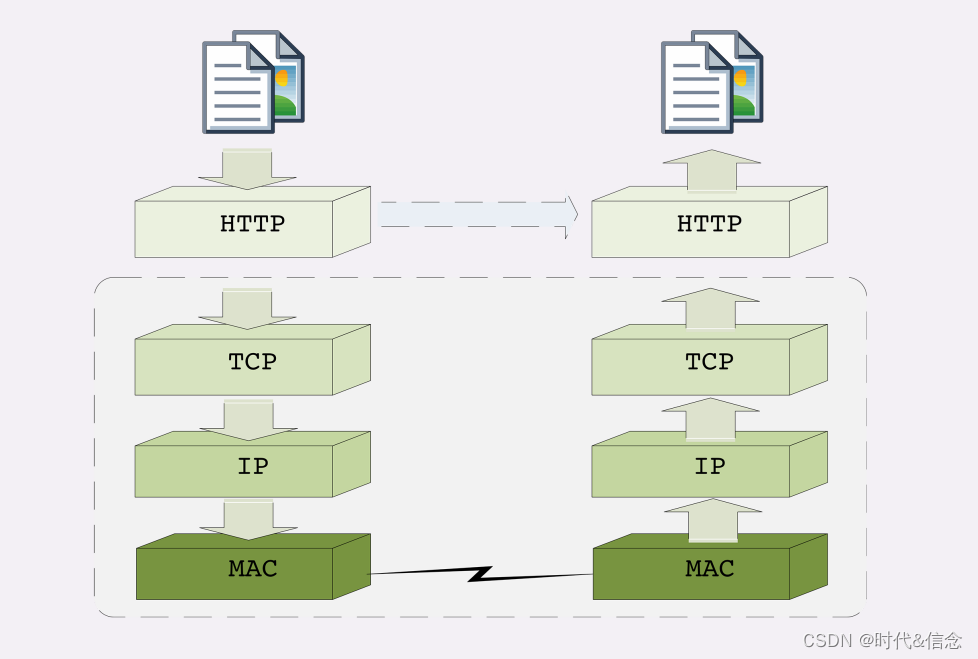
dockerFile常见命令
1、FROM
设置要制作的镜像基于哪个镜像,FROM指令必须是整个Dockerfile的第一个指令,如果指定的镜像不存在默认会自动从Docker Hub上下载
2、MAINTAINER
镜像作者的信息,比如名字或邮箱地址
语法:MAINTAINER name
3、RUN
构建镜像时运行的shell命令
语法:
调用/bin/sh -c command
RUN command
4、CMD
CMD指令中指定的命令会在镜像运行时执行,在Dockerfile中只能存在一个,如果使用了多个CMD指令,则只有最后一个CMD指令有效。当出现ENTRYPOINT指令时,CMD中定义的内容会作为ENTRYPOINT指令的默认参数,也就是说可以使用CMD指令给ENTRYPOINT传递参数。
RUN和CMD都是执行命令,他们的差异在于RUN中定义的命令会在执行docker build命令创建镜像时执行,而CMD中定义的命令会在执行docker run命令运行镜像时执行,另外使用第一种语法也就是调用exec执行时,命令必须为绝对路径。
5、EXPOSE
声明容器的服务端口
语法:EXPOSE port
6、ADD
拷贝文件或目录到镜像容器内,如果是URL或压缩包会自动下载或自动解压
语法:ADD <源文件> <目标目录>
7、COPY
拷贝文件或目录到镜像容器内,跟ADD类似,但不具备自动下载或解压功能
8、ENV
设置容器的环境变量
语法:COPY <源文件> <目标目录>
9、ENTRYPOINT
语法:ENTRYPOINT command param1 param2
ENTRYPOINT指令中指定的命令会在镜像运行时执行,在Dockerfile中只能存在一个,如果使用了多个ENTRYPOINT指令,则只有最后一个指令有效。
10、VOLUME
VOLUME指令用来设置一个挂载点,可以用来让其他容器挂载以实现数据共享或对容器数据的备份、恢复或迁移,具体用法请参考其他文章。
11、USER
USER指令用于设置用户或uid来运行生成的镜像和执行RUN,CMD和ENTYRYPOINT执行命令。
add与copy的区别
区别:COPY指令不支持从远程URL获取资源,只能从执行docker build所在的主机上读取资源并复制到镜像中;而ADD指令支持从远程URL获取资源,可以通过URL从远程服务器读取资源并复制到镜像中。
cmd和entrypoint的区别
CMD
CMD指令为启动的容器指定默认要运行的程序,程序运行结束,容器也就结束。CMD 指令指定的程序可被 docker run 命令行参数中指定要运行的程序所覆盖。
类似于 RUN 指令,用于运行程序,但二者运行的时间点不同:CMD 在docker run 时运行,RUN 是在 docker build时运行。
注意:如果 Dockerfile 中如果存在多个 CMD 指令,仅最后一个生效。
ENTRYPOINT
类似于 CMD 指令,但其不会被 docker run 的命令行参数指定的指令所覆盖,而且这些命令行参数会被当作参数送给 ENTRYPOINT 指令指定的程序。
但是, 如果运行 docker run 时使用了 --entrypoint 选项,将覆盖 ENTRYPOINT 指令指定的程序。
优点:在执行 docker run 的时候可以指定 ENTRYPOINT 运行所需的参数。
注意:如果 Dockerfile 中如果存在多个 ENTRYPOINT 指令,仅最后一个生效。
docker实现原理
Docker提供了在称为容器的松散隔离环境中打包和运行应用程序的能力。隔离特性和安全性允许你在给定主机上同时运行多个容器。容器是轻量级的,并且包含了运行应用程序所需的一切,因此你不需要依赖主机上当前安装的内容。你可以在工作时轻松地共享容器,并确保与你共享的每个人都获得以相同方式工作的同一个容器。
Docker提供了管理容器生命周期的工具和平台:
使用容器开发应用程序及其支持组件。
容器成为分发和测试应用程序的单元。
准备就绪后,将应用程序作为容器或编排服务部署到生产环境中。无论你的生产环境是本地数据中心、云服务提供商还是两者的混合,这都是一样的。
(1)从Dockerfile开始,Dockerfile是镜像的源代码;
(2)创建完Dockerfile以后,可以构建它以创建容器的镜像。
(3)获得容器的镜像后,应该使用注册表重新分发容器。注册表就像一个git存储库,可以推送和拉取镜像。接下来,使用该镜像来运行容器。
类加载过程
加载:
(1)通过类的全限定类名获取该类的二进制流
(2)将该类中的静态存储结构转化为方法区的运行时结构
(3)在内存中生成该类的Class对象,作为该类的访问入口。
验证:
验证的目的是为了确保Class文件的字节流中的信息不会危害到虚拟机。
准备:
准备阶段是为类的静态变量分配内存,并初始化为默认值,这些内存都在方法区内进行分配。准备阶段不分配类中的实例变量的内存,实例变量的内存会随着对象的初始化一起分配在堆中。
public static int value = 123;在准备阶段value的初试值为0.在初始化阶段才会变为123。
解析:
该阶段主要完成从符号引用到直接引用的转换动作。
初始化:初始化是类加载的最后一步,前面的类加载过程,除了在加载阶段用于应用程序可以通过自定义类加载器参与之外,其余动作都由虚拟机主导和控制。到了初始化阶段,才真正开始执行类中的java程序代码。
双亲委派机制
如果一个类加载器收到了类加载的请求,它首先不会自己去加载这个类,而是把这个请求委派给父类加载器去执行,这样所有的加载请求都会被传送到顶层的启动类加载器去执行,只有父加载器无法完成加载请求(它的搜索范围中没有找到所需要的类)时,子加载器才会去尝试加载类。
好处:沙箱安全机制:自己写的String.class不会被加载,这样便可以防止核心API库被随意篡改,避免类的重复加载,当父加载器已经加载了该类时,就没有必要子加载器再加载一遍。
java对象都会分配在堆上吗
Java中的对象不一定是在堆上分配的,因为JVM通过逃逸分析,能够分析出一个新对象的使用范围,并以此确定是否要将这个对象分配到堆上。
逃逸分析就是:一种确定指针动态范围的静态分析,它可以分析在程序的哪些地方可以访问到指针。
HashMap中的负载因子为什么是0.75
负载因子是表示Hsah表中元素的填满的程度。 负载因子越大,填满的元素越多,空间利用率越高,但冲突的机会加大了。 反之,加载因子越小,填满的元素越少,冲突的机会减小,但空间浪费多了。
冲突的机会越大,则查找的成本越高。反之,查找的成本越小。
因此,必须在 "冲突的机会"与"空间利用率"之间寻找一种平衡与折衷。
HashMap有一个初始容量大小,默认是16。为了减少冲突的概率,当hashMap的数组长度到了一个临界值就会触发扩容,把所有元素rehash再放到扩容后的容器中,这是一个非常耗时的操作。
负载因子是0.75的时候,空间利用率比较高,而且避免了相当多的Hash冲突,使得底层的链表或者是红黑树的高度比较低,提升了空间效率。
CAS和ABA问题的解决
CAS 的思想很简单:三个参数,一个当前内存值 V、旧的预期值 A、即将更新的值 B,当且仅当预期值 A 和内存值 V 相同时,将内存值修改为 B 并返回 true,否则什么都不做,并返回 false
A,两个线程A和B分别copy主内存数据到自己的工作区,A执行比较慢,需要10秒, B执行比较快,需要2秒, 此时B线程将主内存中的数据更改为B,过了一会又更改为A,然后A线程执行比较,发现结果是A,以为别人没有动过,然后执行更改操作。其实中间已经被更改过了,这就是ABA问题。
要解决ABA问题,可以增加一个版本号,当内存位置V的值每次被修改后,版本号都加1AtomicStampedReference内部维护了对象值和版本号,在创建AtomicStampedReference对象时,需要传入初始值和初始版本号, 当AtomicStampedReference设置对象值时,对象值以及状态戳都必须满足期望值,写入才会成功。
Redis持久化的策略
Redis提供了两种持久化机制:RDB快照(snapshot)和AOF(append-only file)日志。
而在RDB的持久化方式下,Redis还需要进行保存内存快照,即某一时间内存数据的副本,而保存内存快照需要进行文件IO操作,但文件IO又不能使用多路复用API。
所以,Redis通过操作系统的多进程COW(Copy on Write)机制来实现持久化,也就是Redis在进行持久化时会调用操作系统的fork函数产生一个子进程。
而子进程在刚创建的时候,它和父进程(处理客户端请求的进程)共享内存里面的代码和数据段。
然后子进程负责去做持久化,子进程不会修改内存的数据,它只负责对内存数据进行遍历读取,然后序列化写到磁盘。
Redis的配置默认使用的是RDB持久化方式,可以通过修改配置文件的参数开启AOF功能。RDB这种持久化方式当Redis因为某些原因造成系统宕机后,服务器将会丢失最近写入内存但未保存到快照中的一部分数据,为了尽量少了丢失,可以将持久化的频率增加,但RDB是一种全量持久化的方式,如果数据量比较大时,频繁进行持久化也是不可取的。
将修改的每一条指令增量记录到appendonly.aof文件中,先写入操作系统的缓存(os cache),每隔一段时间fsync到磁盘。
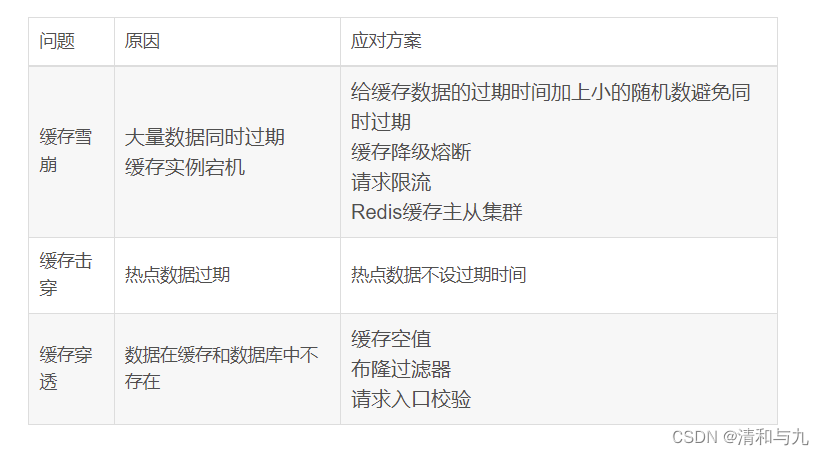
Redis缓存穿透
缓存穿透:要访问的数据既不是Redis缓存中也不再数据库中,导致请求在访问缓存时,发生缓存缺失,再去访问数据库时,发现数据库中也没有要访问的数据。
1.缓存空值或者缺省值,一旦发生缓存穿透,针对查询数据在Redis缓存一个空值或者业务层协商确定的缺省值。应用发生后续请求在进行查询时,可以直接从Redis读取空值或者缺省值返回给业务应用,避免大量请求发送给数据库处理,保持数据库的正常运行。
2.使用布隆过滤器快速判断数据是否存在,避免从数据库中查询数据是否存在,减轻数据库压力。
3.前端对非法请求校验,避免请求进入缓存或者数据库。
Mysql的索引类型
MySQL索引按字段特性分类可分为:主键索引(PRIMARY KEY)、唯一索引(UNIQUE)、普通索引(INDEX)、全文索引(FULLTEXT)。
主键索引(PRIMARY KEY)
建立在主键上的索引被称为主键索引,一张数据表只能有一个主键索引,索引列值不允许有空值,通常在创建表时一起创建。
唯一索引(UNIQUE)
建立在UNIQUE字段上的索引被称为唯一索引,一张表可以有多个唯一索引,索引列值允许为空,列值中出现多个空值不会发生重复冲突。
普通索引(INDEX)
建立在普通字段上的索引被称为普通索引。
全文索引(FULLTEXT)
MyISAM 存储引擎支持Full-text索引,用于查找文本中的关键词,而不是直接比较是否相等。Full-text索引一般使用倒排索引实现,它记录着关键词到其所在文档的映射。
Mysql中有几种锁
(1)表级锁:开销小,加锁块,不会出现死锁,发生锁冲突概率最高,并发性能最低。
(2)页面锁:开销和加锁时间中等,会出现死锁,并发性能一般。
(3)行级别锁:开销大、加锁满,会出现死锁,发生冲突概率最低,并发度最高。
大对象为什么会直接进入老年代
(1)假设大对象最后会晋升老年代,而新生代是基于复制算法来回收垃圾的,由两个Survivor区域配合完成复制算法,如果新生代中出现大对象且能屡次躲过GC,那这个对象就会在两个Survivor区域中来回复制,直至最后升入老年代,而大对象在内存里来回复制移动,就会消耗更多的时间。
(2)假设大对象最后不会晋升老年代,新生代空间是有限的,在新生代里的对象大部分都是朝生夕死的,如果让一个大对象占据了新生代空间,那么相比起正常的对象被分配在新生代,大对象无疑会让新生代GC提早发生,因为内存空间会更快不够用,如果这个大对象因为业务原因,并不会马上被GC回收,那么这个对象就会进入到Survivor区域,默认情况下,Survivor区域本来就不会被分配的很大,那此时被大对象占据了大部分空间,很可能会导致之后的新生代GC后,存活下来的对象,Survivor区域空间不够放不下,导致大部分对象进入老年代,这就加快了老年代GC发生的时间,而老年代GC对系统性能的负面影响则远远大于新生代GC了。
常见的设计模式
1、单例模式:一个类只有一个实例,且该类能自行创建这个实例的一种模式
①单例类只有一个实例对象。
②该单例对象必须由单例类自行创建
③单例类对外提供一个访问该单例的全局访问点
2、工厂方法模式:实例化对象不是用new,用工厂方法替代。将选择实现类,创建对象统一管理和控制。从而将调用者跟我们的实现类解耦。
3、抽象工厂模式:抽象工厂模式提供了一个创建一系列相关或者相互依赖对象的接口,无需指定它们具体的类(围绕一个超级工厂创建其他工厂,该超级工厂称为工厂的工厂)
4、代理模式:由于某些原因需要给某对象提供一个代理以控制对该对象的访问。这时,访问对象不适合或者不能直接引用目标对象,代理对象作为访问对象和目标对象之间的中介。
ArrayList与LinkedList的区别
1.ArrayList的实现是基于数组,LinkedList的实现是基于双向链表。
2.对于随机访问,ArrayList优于LinkedList,ArrayList可以根据下标以O(1)时间复杂度对元素进行随机访问。而LinkedList的每一个元素都依靠地址指针和它后一个元素连接在一起,在这种情况下,查找某个元素的时间复杂度是O(n)
3.对于插入和删除操作,LinkedList优于ArrayList,因为当元素被添加到LinkedList任意位置的时候,不需要像ArrayList那样重新计算大小或者是更新索引。
4. LinkedList比ArrayList更占内存,因为LinkedList的节点除了存储数据,还存储了两个引用,一个指向前一个元素,一个指向后一个元素。