一、理解介绍
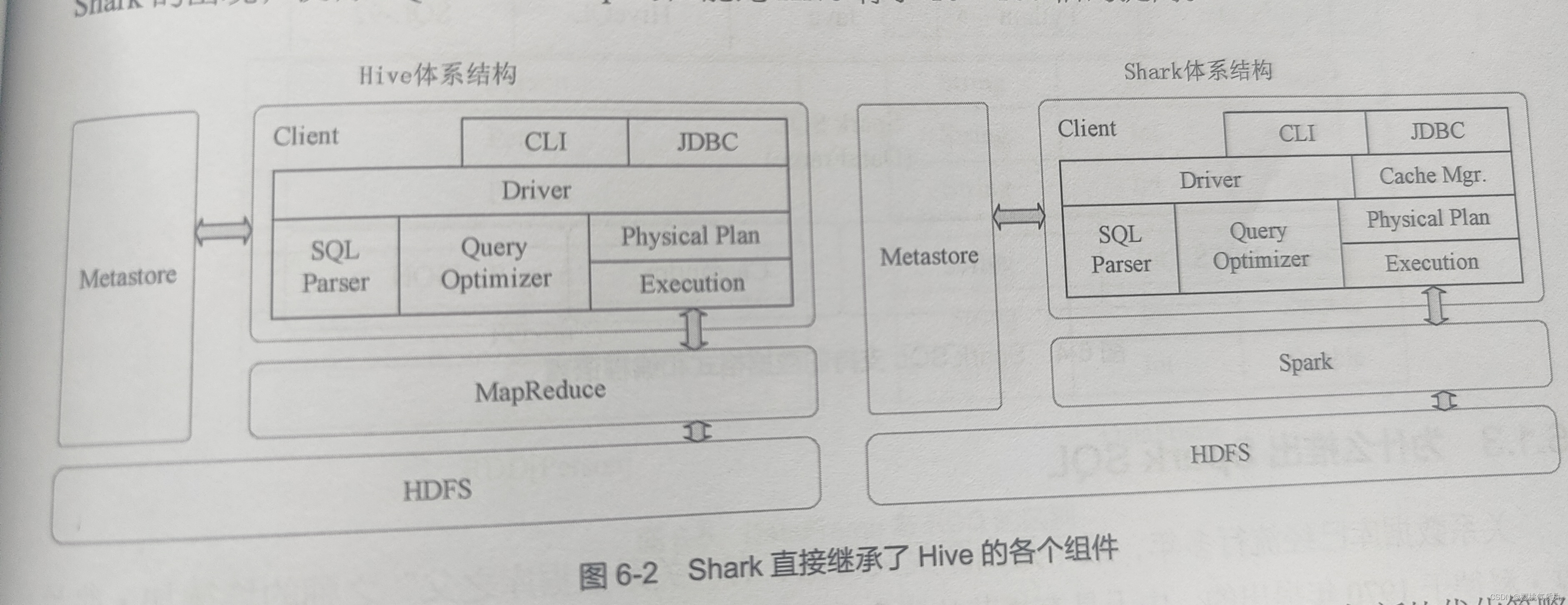
Spark SQL是spark中用于结构化数据处理的组件,可访问多种数据源,如连接Hive、MySQL,实现读写等操作。为什么要用spark去操作这些数据库呢?hive是一个基于Hadoop的数据仓库工具,hive的查询操作语句都要依赖于MapReduce任务进行处理,spark的计算效率比MapReduce高,spark SQL 在hive兼容层面做了进一步优化,所以如果用spark引擎与hive交互性能会显著提高。
二、RDD和DataFrame
RDD:弹性分布式数据集,把要执行的数据集可以通过RDD转换成更方便操作的形式,比如一段话通过RDD处理成一个一个词,再对词做下一步操作(计数、对比等等)
RDD是分布式的java对象集合,但是对象内部结构对于RDD而言是不可知的
DataFrame:是以RDD为基础的分布式数据集,提供详细的结构信息,相当于关系库中的一张表。
RDD可以转换成DataFrame:
1.利用反射机制推断RDD模式 2.编程方式定义RDD模式
利用反射机制推断RDD模式时需要先定义一个case class,因为只有ase class才能被spark隐式的转换成DataFrame。系统把文件employee.txt加载到内存生成一个RDD,每个RDD元素都是string类型,比如Array(“Ella”,"24")这一行记录是一个RDD,然后调用map(_.split(" "))方法得到一个新的RDD,还可根据需求继续对RDD进行转换,最后转换成想要的形式,比如转换成这种类型[namestring , age: int ]然后执行toDF()操作,实现把RDD转换成DataFrame,可以看出,DataFrame就像一张有数据结构的表,不再是一个个没有联系的RDD块。

2.编程方式定义RDD模式。使用编程接口构造一个模式(schema),并将其应用在已知的RDD上
第一步:制作“表头”
第二步:“制作表中记录”
第三部:把“表头”和“表中记录”拼接
通过val schema = StructType(fields)语句把fields作为输入生成一个StructTyped对象即schema里面包含表的模式信息,
生成表头,把RDD的一行元素转换成想要的和表头类型匹配的样子,比如中age是int型,RDD要toInt
对应转换,元素转换完成就是“表中记录”,把“表头”和“表中记录”拼接在一起得到一个有结构的DataFrame
三、通过Spark SQL读写数据库
1、读写MySQL
在idea中添加依赖,读写操作的代码都是写在idea上的scala代码,通过打包push到远程仓库gitee上,再拉到linux上再spark-local模式下执行
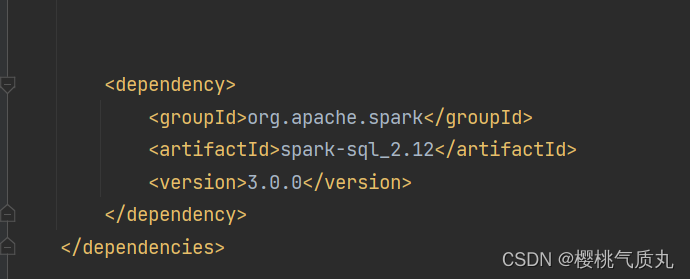
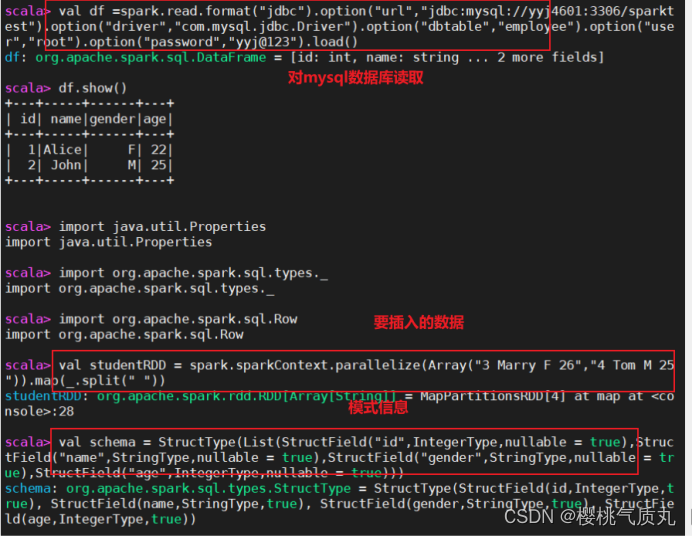
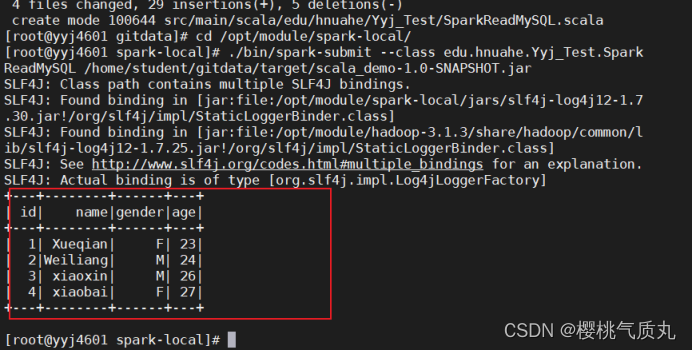
读MySQL数据库中的表:
package edu.hnuahe.Yyj_Test
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SparkReadMySQL { //edu.hnuahe.Yyj_Test.SparkReadMySQL
def main(args: Array[String]): Unit = {
val spark=SparkSession.builder().appName("SparkReadMySQL").getOrCreate()
val df =spark.read.format("jdbc").option("url","jdbc:mysql://yyj4601:3306/spark")
.option("driver","com.mysql.jdbc.Driver").option("dbtable","student") //表名
.option("user","root") //y用户名
.option("password","***") //密码
.load()
df.show()
spark.stop()
}
}
//hive和spark尽量不在同一台主机
写入MySQL数据库中的表中:
package edu.hnuahe.Yyj_Test
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import java.util.Properties
object SparkWriteMySQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkWriteMySQL").getOrCreate()
val studentRDD = spark.sparkContext
.parallelize(Array("5 Ironman M 23",
"6 Bumblebee M 21"))
.map(_.split(" "))
//val schema = StructType(fields)语句把fields作为输入生成一个StructTyped对象即schema里面包含表的模式信息,也就是表头
val schema = StructType(List(StructField("id",IntegerType,nullable = true),
StructField("name",StringType,nullable = true),
StructField("gender",StringType,nullable = true),
StructField("age",IntegerType,nullable = true)))
//创建一个row对象,每个row对象是rowRDD中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).trim,p(3).toInt))
//建立row对象和模式之间的关系也就是把数据和模式对应
val studentDF =spark.createDataFrame(rowRDD,schema)
//创建一个prop变量保存jdbc连接参数
val prop = new Properties()
prop.put("user","root")
prop.put("password", "yyj@123")
prop.put("driver", "com.mysql.jdbc.Driver")
studentDF.write.mode("append")
.jdbc("jdbc:mysql://yyj4601:3306/spark",
"spark.student",prop)
spark.stop()
}
}

2、读写Hive
读之前Hive里要提前存在要读的表
package edu.hnuahe.Yyj_Test
import org.apache.spark.sql.SparkSession
object sparkReadHive {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("sparkReadHive")
.enableHiveSupport().getOrCreate()
import spark.sql
sql("SELECT * FROM sparktest.student").show(false)
spark.stop()
}
}
执行前要在spark-local/conf/spark-env中添加环境
如果报错:“UnresolvedRelation”未解决的关系
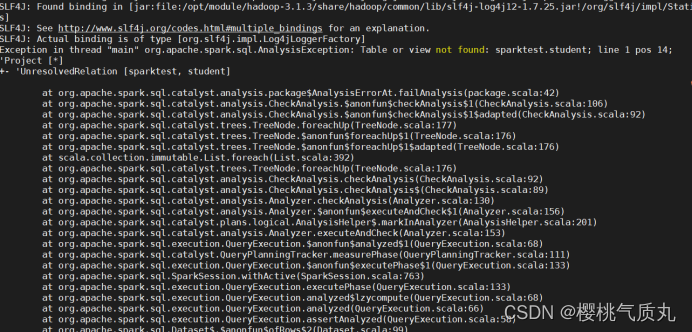
1.可能是NameNode和Hive不在同一结点上,2.也可能环境变量中为指明是spark-local模式
对于1.的解决:把hive目录下的conf/hive-site.xml复制一份到spark-local/conf中
对于2.的解决:vim/etc/profile 把spark-local环境变量添加上,退出后执行source/etc/profile刷新环境变量
以上基本就能解决非代码敲错的报错:
读取Hive中的表成功

写入Hive:
package edu.hnuahe.Yyj_Test
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object sparkWriterHive {
def main(args: Array[String]): Unit = {
val warehouseLocation = "spark-warehouse"
val spark = SparkSession.builder().appName("sparkWriteHive")
.config("spark.sql.warehouse.dir",warehouseLocation)
.enableHiveSupport().getOrCreate()
//2、设置两条数据表示两个学生信息
val studentRDD = spark.sparkContext
.parallelize(Array("5 Ironman M 23",
"6 Bumblebee M 21" ))
.map(_.split(" "))
val schema = StructType(List(StructField("id",IntegerType,nullable = true),
StructField("name",StringType,nullable = true),
StructField("gender",StringType,nullable = true),
StructField("age",IntegerType,nullable = true)))
//4、创建row对象每个row对象都是rowrdd中的一行
val rowRDD = studentRDD.map(p => Row(p(0).toInt,p(1).trim,p(2).trim,p(3).toInt))
//5、建立row对象和模式之间的关系也就是把数据和模式对应
val studentDF = spark.createDataFrame(rowRDD,schema)
//查看视图
studentDF.show()
//6、创建视图
studentDF.createTempView("tempTable")
//7、执行插入语句
import spark.sql
sql("INSERT INTO sparktest.student SELECT * FROM tempTable")
spark.stop()
}
}

四、Spark SQL基本操作
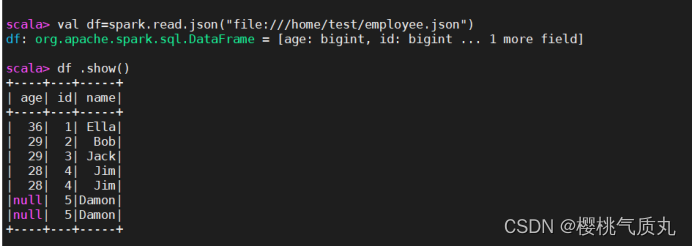
1、Linux中employee.json:/home/test/

读取json文件创建dataframe:
2、用scala语句完成下列操作:
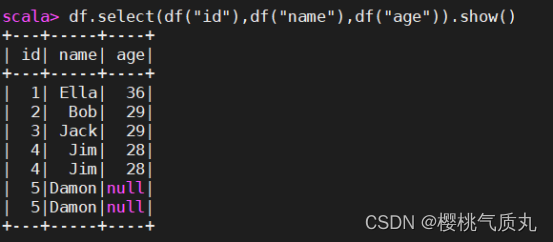
- 查询所有数据
df.select(df("id"),df("name"),df("age")).show()
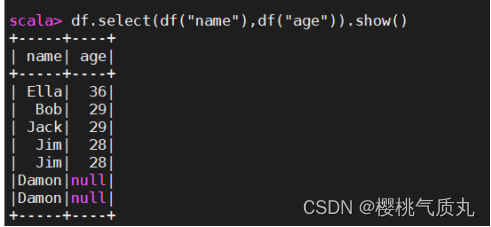
2.查询所有数据,并去出重复数据
df.select(df("id"),df("name"),df("age")).distinct().show()或者df.distinct().show()

3.查询所有数据,打印时去除id字段
df.select(df("name"),df("age")).show()或df.drop(“id”).show()
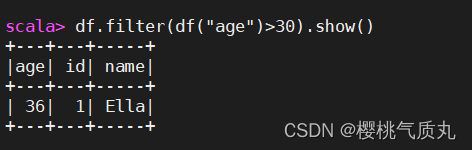
4.筛选出age>30的记录
df.filter(df("age")>30).show()
5将数据按照age分组
df.groupBy("age").count().show()

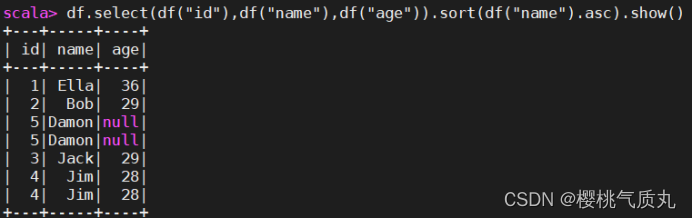
6.数据按照name升序排列
df.select(df("id"),df("name"),df("age")).sort(df("name").asc).show() 或df.sort(df("name").asc).show()
7.取出前三行数据
df.head(3)或df.take(3)

2.查询所有记录的name列,并为其取别名为username
df.select(df("name").as("username")).show()

9.查询age的平均值
df.agg("age"->"avg").show()