go读request.Body内容踩坑记
踩坑代码如下,当时是想获取body传过来的json
func demo(c *httpserver.Context) {
type ReqData struct {
Id int `json:"id" validate:"required" schema:"id"`
Title string `json:"title" validate:"required" schema:"title"`
Content [][]string `json:"content" validate:"required" schema:"content"`
}
bodyByte, _ := io.ReadAll(c.Request.Body)
fmt.Println(string(bodyByte))
var req ReqData
err := c.Bind(c.Request, &req)
//发现req里的属性还是空
if err != nil {
c.JSONAbort(nil, code.SetErrMsg(err.Error()))
return
}
contentByte, _ := json.Marshal(req.Content)
data := svc.table2DataUpdate(c.Ctx, req.Id, req.Title, req.Content)
c.JSON(data, err)
}
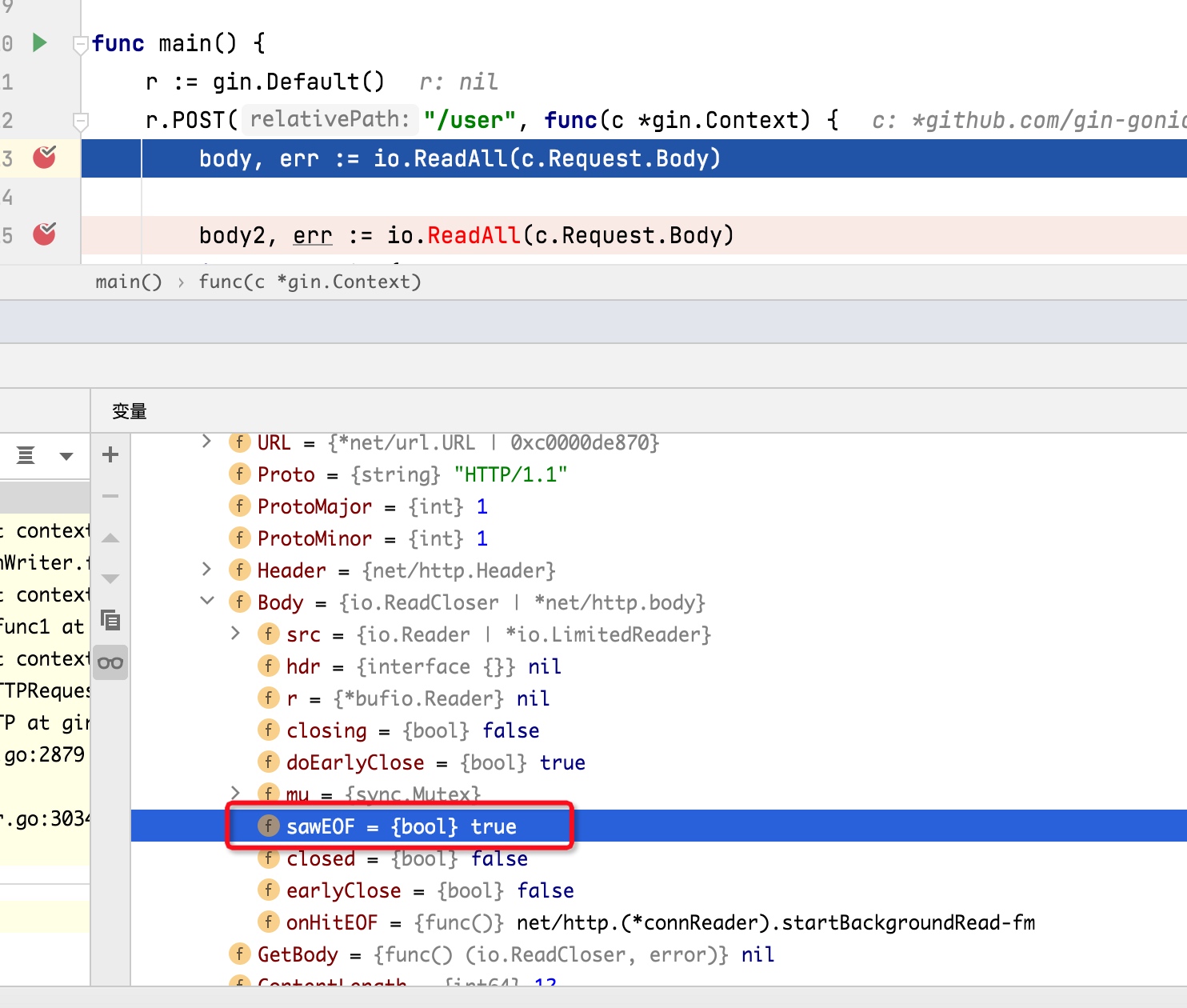
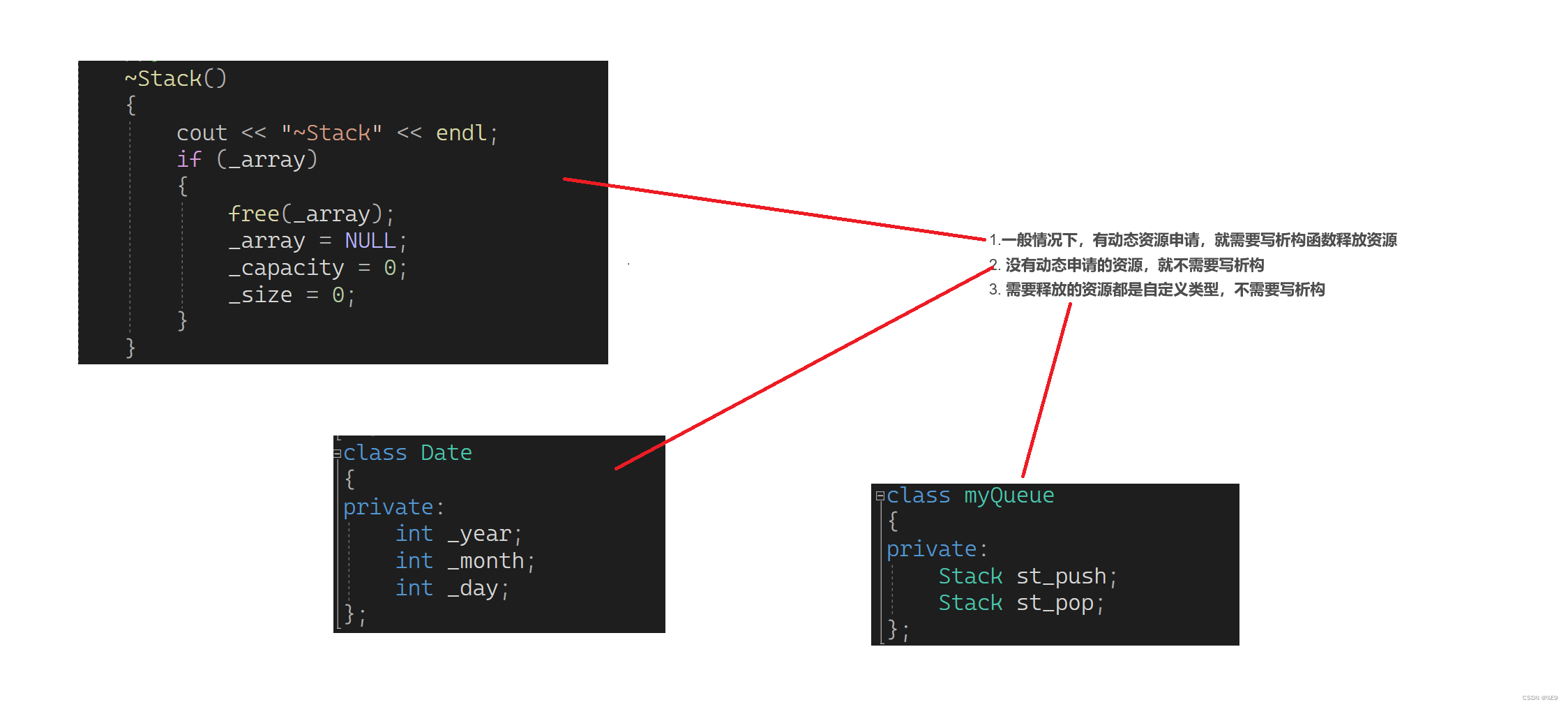
如上代码Bind发现里面并没有内容,进行追查发现c.Request.Body在第一次经过io.ReadAll()调用后,再次调用时内容已为空。
为什么会这样??难道io.ReadAll是读完后就给清空了吗??
带着这个问题对底层代码进行了CR,最终得到答案:不是 !!
因为从Body.src.R.buf中拷贝,全拷贝完后设置b.sawEOF为true,再次读取时遇到这个为true时就不会再读取。
代码CR总结
- Body 字段是一个 io.ReadCloser 类型,io.ReadCloser 类型继承了 io.Reader 和 io.Closer 两个接口,其中 io.Reader 接口可以通过 Read 方法读取到消息体中的内容
- io.ReadAll()时会先创建一个切片,初始化容量512,然后开始填充这个切片,中间会有一个巧妙的方式扩容,值得学习借鉴。
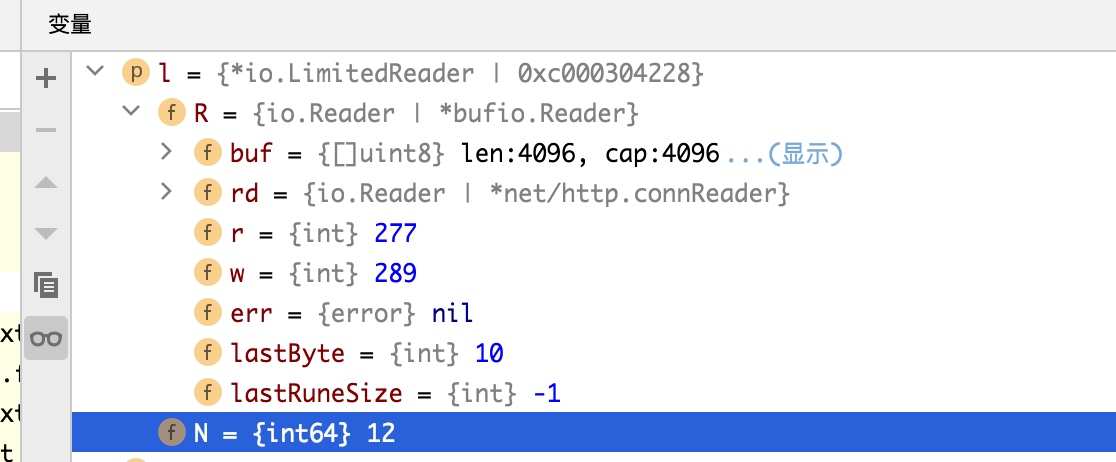
- 数据是从 b.buf(Body.src.R.buf) 中拷贝, n = copy(p, b.buf[b.r:b.w])
- 数据循环拷贝,一直到下面几种情况会直接返回
- b.sawEOF==true
- b.closed==true
- l.N<=0(l.N指剩余内容的数量,每读取一段时会减掉)
- 数据在copy过程中,会设置l.N=l.N-n 当剩余数量为0时,会设置 b.sawEOF=true
下面为CR的相关代码
//src/io/io.go:626
func ReadAll(r Reader) ([]byte, error) {
b := make([]byte, 0, 512)
for {
if len(b) == cap(b) {
// Add more capacity (let append pick how much).
b = append(b, 0)[:len(b)]
}
//这里是重点,返回copy的数量,err信息
n, err := r.Read(b[len(b):cap(b)])
//都读完后会设置 body.closed=true,当再调用r.Read时遇到b.closed=true不会再copy数据,会直接返回n=0,err="http: invalid Read on closed Body"
b = b[:len(b)+n]
if err != nil {
if err == EOF {
err = nil
}
return b, err
}
}
}
//r.Read(b[len(b):cap(b)])
//src/net/http/transfer.go:829
func (b *body) Read(p []byte) (n int, err error) {
b.mu.Lock()
defer b.mu.Unlock()
if b.closed {
return 0, ErrBodyReadAfterClose
}
return b.readLocked(p)
}
//b.readLocked(p)
//src/net/http/transfer.go:839
// Must hold b.mu.
func (b *body) readLocked(p []byte) (n int, err error) {
if b.sawEOF {
return 0, io.EOF
}
//重点关注
n, err = b.src.Read(p)
if err == io.EOF {
b.sawEOF = true
// Chunked case. Read the trailer.
if b.hdr != nil {
if e := b.readTrailer(); e != nil {
err = e
// Something went wrong in the trailer, we must not allow any
// further reads of any kind to succeed from body, nor any
// subsequent requests on the server connection. See
// golang.org/issue/12027
b.sawEOF = false
b.closed = true
}
b.hdr = nil
} else {
// If the server declared the Content-Length, our body is a LimitedReader
// and we need to check whether this EOF arrived early.
if lr, ok := b.src.(*io.LimitedReader); ok && lr.N > 0 {
err = io.ErrUnexpectedEOF
}
}
}
// If we can return an EOF here along with the read data, do
// so. This is optional per the io.Reader contract, but doing
// so helps the HTTP transport code recycle its connection
// earlier (since it will see this EOF itself), even if the
// client doesn't do future reads or Close.
if err == nil && n > 0 {
if lr, ok := b.src.(*io.LimitedReader); ok && lr.N == 0 {
err = io.EOF
b.sawEOF = true
}
}
if b.sawEOF && b.onHitEOF != nil {
b.onHitEOF()
}
return n, err
}
//b.src.Read
//src/io/io.go:466
func (l *LimitedReader) Read(p []byte) (n int, err error) {
if l.N <= 0 {
return 0, EOF
}
if int64(len(p)) > l.N {
p = p[0:l.N]
}
n, err = l.R.Read(p)
l.N -= int64(n)
return
}
//l.R.Read(p)
//src/bufio/buffio.go:198
// Read reads data into p.
// It returns the number of bytes read into p.
// The bytes are taken from at most one Read on the underlying Reader,
// hence n may be less than len(p).
// To read exactly len(p) bytes, use io.ReadFull(b, p).
// At EOF, the count will be zero and err will be io.EOF.
func (b *Reader) Read(p []byte) (n int, err error) {
n = len(p)
if n == 0 {
if b.Buffered() > 0 {
return 0, nil
}
return 0, b.readErr()
}
if b.r == b.w {
if b.err != nil {
return 0, b.readErr()
}
if len(p) >= len(b.buf) {
// Large read, empty buffer.
// Read directly into p to avoid copy.
n, b.err = b.rd.Read(p)
if n < 0 {
panic(errNegativeRead)
}
if n > 0 {
b.lastByte = int(p[n-1])
b.lastRuneSize = -1
}
return n, b.readErr()
}
// One read.
// Do not use b.fill, which will loop.
b.r = 0
b.w = 0
n, b.err = b.rd.Read(b.buf)
if n < 0 {
panic(errNegativeRead)
}
if n == 0 {
return 0, b.readErr()
}
b.w += n
}
// copy as much as we can
n = copy(p, b.buf[b.r:b.w])
b.r += n
b.lastByte = int(b.buf[b.r-1])
b.lastRuneSize = -1
return n, nil
}