Kubernetes(简称K8s)上数据服务的自动化越来越受欢迎。在K8s上运行有状态的工作负载意味着使用Operator。然而,它发展演化到今天已经变得非常复杂,像Operator这样的应用模式和扩展方式对于开发者与运维者而言愈发受到欢迎。

但工程师们经常对编写K8s Operator的复杂性感到吃力,这会影响到最终用户。据《2021年K8s数据报告》指出,K8s Operator的质量阻碍了公司进一步扩大K8s占有率。
Anynines首席执行官Julian Fischer已经构建自动化工具近十年了,他非常了解在处理在云原生平台和K8s等分布式基础设施上做状态管理的复杂性。
Julian首先分享了在构建 Operator时应该遵循的方法,他称之为运营模式,分为四个部分:
第1级:SysOp或DB要做什么
第2级:容器化,YAML + kubectl
第3级:编写 Operator
第4级: Operator 生命周期管理
通过他的分享,可以了解数据服务自动化中的常见陷阱以及如何避免,进而从技术和方法学角度编写更好的K8s Operator。
数据服务自动化
它在数据服务自动化的一般主题和K8s之间有点跳跃。一般来说,如果你谈论数据服务自动化,你必须做的第一件事就是明确范围,即你所说的数据服务自动化真正指什么。对于我们来说,任何时候都有一个使命,那就是将各种数据服务的整个生命周期完全自动化,以便在跨基础设施的云原生平台上大规模运行。

这里不是一些营销噱头,它是如何对数据服务自动化进行范围分析的一个例子。例如,为了使多个数据服务自动化,你希望看到某些共享效果,比如你可以将Operatar SDK以外的数据服务纳入自动化框架。因此,任务的背景会产生很大影响。例如,一个简单的K8s集群,有一个小单位用来运行他们的应用程序。假设使用Postgres数据库,Postgres一直是我最喜欢的例子。大家都知道,一个K8s集群对应一个Operator一个服务实例,应用程序将连接到那个数据库。这与我们今天想在这里谈论的故事不同。假设他们按需配置服务实例,Postgres数据库被表示为有状态集。Operator允许你创建多个实例。事情就会变得复杂,因为你有更多的数据服务实例,你必须处理好它。如果你随后引入更多数据服务,例如,将RabbitMQ、MongoDB或任何其他数据库添加到Operator的集合中,挑战将变得更加大。
现在我们协作的组织中,有时有数百或数千名员工,有数千名甚至一万名开发人员,令人难以置信的是,他们拥有数量庞大的工程师,也同时拥有许多K8s集群。我们认为,数以十计、数以百计的K8s集群对我们的经验是个考验。例如,在基于虚拟机的数据服务自动化中,它们通常有上千台虚拟机运行上千个服务实例,这取决于它们如何组建集群。你可以假设有一个服务实例对应三个pod,恰好正在运行这样一个小集群实例。在现有这个规模上,自动化的需求经常变更,对规模的影响很大。
如果你解决了制作“香肠”和分发“香肠”等简单任务,你可以想象,如果你要服务更大规模的用户,堆栈技术解决方案要进行调整。数据服务自动化也几乎一样。因此,如果我们考虑那些大型应用场景,拥有很多这样的服务实例,每个数据服务实例对某些用户都很重要。因此,自动化需要符合一定的标准。如果该标准没有达到自动化水平,那么自动化将用不起来,组织和技术的采用就不会发生。
使用K8s的数据服务
那么如何使用K8s的数据服务?首先,你如何实现一个Operator,如我认为社区应该知道的那样?最简单的方法是使用K8s、CRD和自定义资源定义,传输给K8s新的数据结构。例如,在描述你的Postgres实例时,要创建一个复数的Postgres实例,因为我们是按需配置,有一个控制器负责管理实例。该控制器将按你指定的对象的规范,将其转换为可运行的程序。因此,基本上,Operator所做的是将具有Postgres 12.2版本的主对象(如Postgres实例)的规范转换为辅助资源。据我所知,Operator SDK是构建CRD、生成CRD并为控制器提供模板代码的主流工具。这是讨论K8s相关的数据服务自动化时,我们想到了这两件事。同时,还有KUDO。

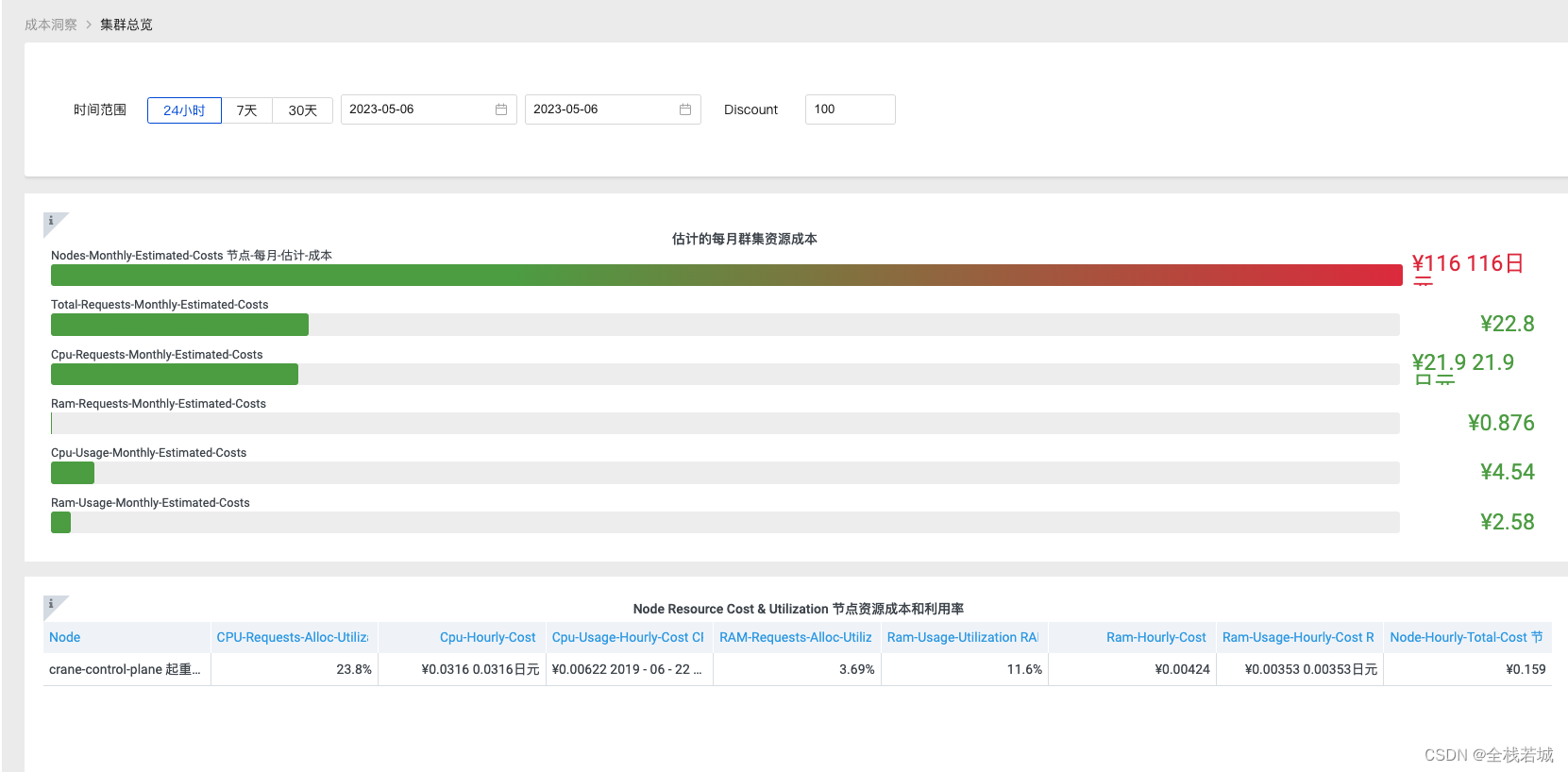
在开发阶段,如果你开发了一个Operator,挑战之一是你想如何系统地处理这项工作。有一个简单的模型,我们称之为操作模型,分为四个级别,这有助于你处理数据服务自动化,这是第一次提出。
给一点建设性的意见,要把你的注意力放在任务上。例如,我们建议在第一级实现Postgres的自动化。你需要掌握的第一件事是助理或者DBA要做什么。特别是,这对应用程序开发人员有什么影响?他们到底想要什么?
例如,应用程序开发人员对Postgres的平均期望是什么?他们需要自动故障转移的集群实例吗?在这种情况下,他们更喜欢同步复制还是异步复制?你想使用哪种故障转移和集群管理器,还是使用首选仓库管理器,或者更确切地说,使用Prometheus(普罗米修斯)?
而且,基本上你要搞清楚如何配置文件,对Postgres完成基本设置,这是操作模型一级。只需假设你有一台虚拟机,你可以做任何你想做的事情,安装软件包,配置数据库等等。因此,一旦你这样做了,你知道配置文件应该是什么样子,所有的这些都是Operator可以做到的。你可以考虑容器化,它可以选择现有的容器映像,并将其组装到有状态集服务的K8s规范中,并创建自有的模板,这是操作模型二级中的YAML部分。因此,在操作模型二级的最终操作中,无论你是选择了现有的容器映像还是自己创建了它们,你都有K8s规范,可以与kubectl一起使用,以手动创建自己的服务实例。一旦你这样做了,你基本上可以创建你的Postgres实例,比如说,用三个副本和同步流复制,假定你已经知道如何手动做到这一点,然后你可以通过思考问题,如何编写gde,创建特定的有状态设置的无头服务来处理特定的保密数据,你可以更容易地实现这样的一个Operator。
现在,假设我们提醒自己,我们正在谈论的环境可能包含1000多个数据服务实例,跨越许多K8s集群的多个数据服务。在这种情况下,我们还需要接受Operator生命周期管理本身是我们工具链的重要组成部分。因此,我们还需要自动化来管理Operator本身的生命周期。
无论是Operator生命周期管理器,还是其他技术在这一点上都无关紧要,最重要的是你需要知道,这是你整体数据服务自动化挑战的一部分。现在,如果你想到K8s Operator,并且提到自定义资源定义,像这样的YAML结构描述了一种可以传递给K8s API的新数据类型,然后K8s API将向你提供节点,并持久地将规范存储在etcd中。这里格式不是很好。但你可以在这里看到特定资源定义的自定义资源会是什么样子,我们教K8s如何创建这样的对象。
然而,仅凭你的CRD不会有任何效果,因为你需要控制器,控制器通过代码实现事件观测,例如创建了一个对象。然后,控制器可以确认这个特定的服务实例是否已经存在,确认辅助资源,需要一个服务密钥访问,以及需要创建的有状态集。因此,正如我之前所说,K8s控制器基本上将主要资源转换为次要资源的组合。在我们的示例中,到目前为止,这些资源一直是K8s的内部资源,但实际情况不一定如此。我们稍后再讨论。
如果你还想在那里开始编写Operator,Operator SDK会就Operator的成熟度级别提出建议,Operator分为五个不同的等级。我真的不确定你们是否都了解这些等级的区别。但如果从现在开始,这绝对是一个好的开端。学会正确提问,这些问题也在文档中。如果你真的构建Operator,你需要用到一些核心功能,例如在没有备份的情况下更新补丁,以及备份和恢复功能。通常这些是必备的,但用户可能会拒绝解决方案,或者他们没有解决方案。但你知道,你早晚要这么做,因此这会对你有所帮助。所以请记住,常见的陷阱,由分布式系统的编程问题引起的Bug,会有很多个,就看我们排除多少。

例如企业使用Git引发的问题。根据我的经验,总的来说,数据服务自动化最有可能的最大问题是,人们低估了实现数据服务自动化的复杂性和所需努力,表现形式包括基本生命周期操作的覆盖范围不足,以及鲁棒性和可观察性等质量特性较低。基于这点来说,了解使用的门槛是有必要的,你需要知道,自动化要做什么才能被目标受众接受。虽然这在很大程度上取决于目标受众本身,但现在我可以分享一些我学到的对我们大客户很重要的事情,但说不完,因为现在时间不够多了,这有点耗时。
接受配置更新很重要,因为应用程序开发人员能够通过自动化配置来使用数据库和应用程序。如果应用程序有特殊要求,你需要稍微调整一下数据库配置。这是真实的需求,要尽可能地利用资源。因此,你需要采访目标受众,并了解这些配置选项是否已经在自动化文档中。你需要善于根据特定需求调整自动化。如果你知道组织内有更多的开发人员,所有的云原生需求都在那里,比如,友好的可观测性,透明使用基础设施。有了K8s,在某种程度上你已经获得了。但在备份的上下文中,当你需要将备份存储在某个地方时,你通常必须将备份写入对象存储。这就是人们对S3 API的存在做出假设的地方,例如,你应该选择一些隐藏底层对象存储的抽象库。
服务实例的水平可扩展性
例如,你需要一个服务实例,你可以考虑单个Postgres用一个pod,也可以考虑集群Postgres使用异步流复制。一旦你想进行水平扩展,将副本从一个扩展到三个,就会在自动化中引入许多复杂性。因为Postgres不是那么简单做自动化服务,这让人喜欢用它举例。因此,你需要添加一个集群管理器来进行故障检测,你需要有一个主节点选举和主节点晋升逻辑来帮助你实现。
此外,如果你恰好有多个可用区域的数据中心,可以分发你的pod来使用它们,这样不会出现单个K8s节点。只要是可用区域,并建立了K8s集群,那么几乎会100%这样使用。一般来说,在整个生命周期中会重建状态集很多次,比如计划、切换、升级,或者垂直扩展使pod变大,数据被合并。我们将再次讨论备份和恢复的问题,这显然非常重要,因为应用程序开发人员无需等待平台运营商的手动干预即可恢复应用程序,这通常是最后的措施。
因此,这一切都与按需自助服务有关,到目前为止,应用程序开发人员可以自助服务,创建服务实例,然后修改它们,重新配置它们,如果服务实例碰巧出现异常,或者数据被意外删除,他们需要按应用程序的要求恢复数据,防止潜在数据丢失。
有一个需求不太明显,有时要提供最新的数据服务版本。假设Postgres的最新版本是不错的,活跃用户自然会喜欢。但对于某个组织来说,有些应用程序可能处于长期维护状态,它们不会立即使用新版本,因此,应用程序开发人员需要能够选择数据服务版本,可以使用版本号管理Operator,以支持所有自动化版本的启用和退出。这是你必须为自动化制定的政策。如果你提供太多的版本,这也会给团队提供很多的支持。但是,文档也可能会减少对你的支持。
安全性也很重要,通常要求具备加密存储、传输加密。例如,你希望被加密的磁盘上的数据没有被读取使用,从客户端发送到数据服务实例的数据也是如此,有状态集中的端口都应该加密。