C++入门2
- 缺省参数
- 结合优先级
- inline函数
- vs中的测试实例
- inline函数要点
- 内联函数与宏定义区别:
- 函数重载
- 定义
- 名字粉碎技术
- C++编译时函数名修饰约定规则
- 函数模板
缺省参数
函数定义时,缺省值赋值是从右向左依次赋值
调用函数时,从左向右依次给实参值,不能跳
void func(int a=0,int b=0,int c=0){
printf("a=%d,\n b=%d\n c=%d\n",a,b,c);
}
int main(){
func(1,2,3);
return 0;
}
结合优先级
如果是普通变量,优先结合普通指针,么有普通指针,退而求其次,和指向常量的指针结合,这样的话,只能读取,不能修改
如果是常变量,优先结合常性指针,没有此函数,编译器无法通过,不能和普通指针结合,应为是常量,不能用普通指针取修改
#include<iostream>
using namespace std;
void func(int* p){}
void func(const int* p){}
int main(){
int a=10;
func(&a);//如果没有void func(int* p){},就会调用void func(const int* p){}
const int b=20;
func(&b);//如果没有void func(const int* p){},无法调用报错
}
#include<iostream>
using namespace std;
void func(int& p){}
void func(const int& p){}
int main(){
int x=10;
func(x);//调用void func(int& p){},如果没有,退而求其次和void func(const int& p){}结合
const int y=10;
func(y);//调用void func(const int& p){},如果没有,无法通过,因为y是常性,不能修改,而void func(int& p){}可以修改
func(10);//和他结合void func(const int& p){}
return 0;
}
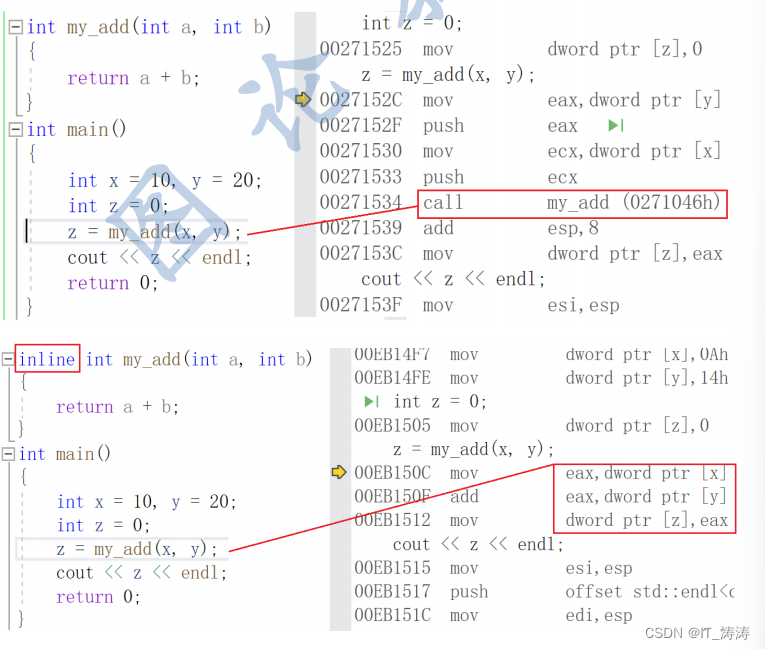
inline函数
当程序执行函数调用时,系统要建立栈空间,保护现场,传递参数以及控制程序执行的转移等等,这些工作需要系统时间和空间的开销。
加inline关键字将其改成内联函数,在编译期间编译器能够在调用点内联展开该函数。
当函数功能简单,使用频率很高,为了提高效率,直接将函数的代码嵌入到程序中。但这个办法有缺点,一是相同代码重复书写,二是程序可读性往往没有使用函数的好。
为了协调好效率和可读性之间的矛盾,C++提供了另一种方法,即定义内联函数,方法是在定义函数时用修饰词inline。
需要设置
vs中的测试实例
#include<iostream>
using namespace std;
inline int add(int a, int b) {
return a + b;
}
int main(){
int a = 10, b = 20;
int sum=add(a, b);
return 0;
}
inline函数要点
inline是一种以空间换时间的做法,省去调用函数额开销。但当函数体的代码过长或者是递归函数即便加上inline关键字,也不会在调用点以内联展开该函数。
inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。
如果函数的执行开销小于开栈清栈开销(函数体较小),使用inline处理效率高。如果函数的执行开销大于开栈清栈开销,使用普通函数方式处理。
内联函数与宏定义区别:
内联函数在编译时展开,带参的宏在预编译时展开。
内联函数直接嵌入到目标代码中,带参的宏是简单的做文本替换。
内联函数有类型检测、语法判断等功能,宏只是替换。
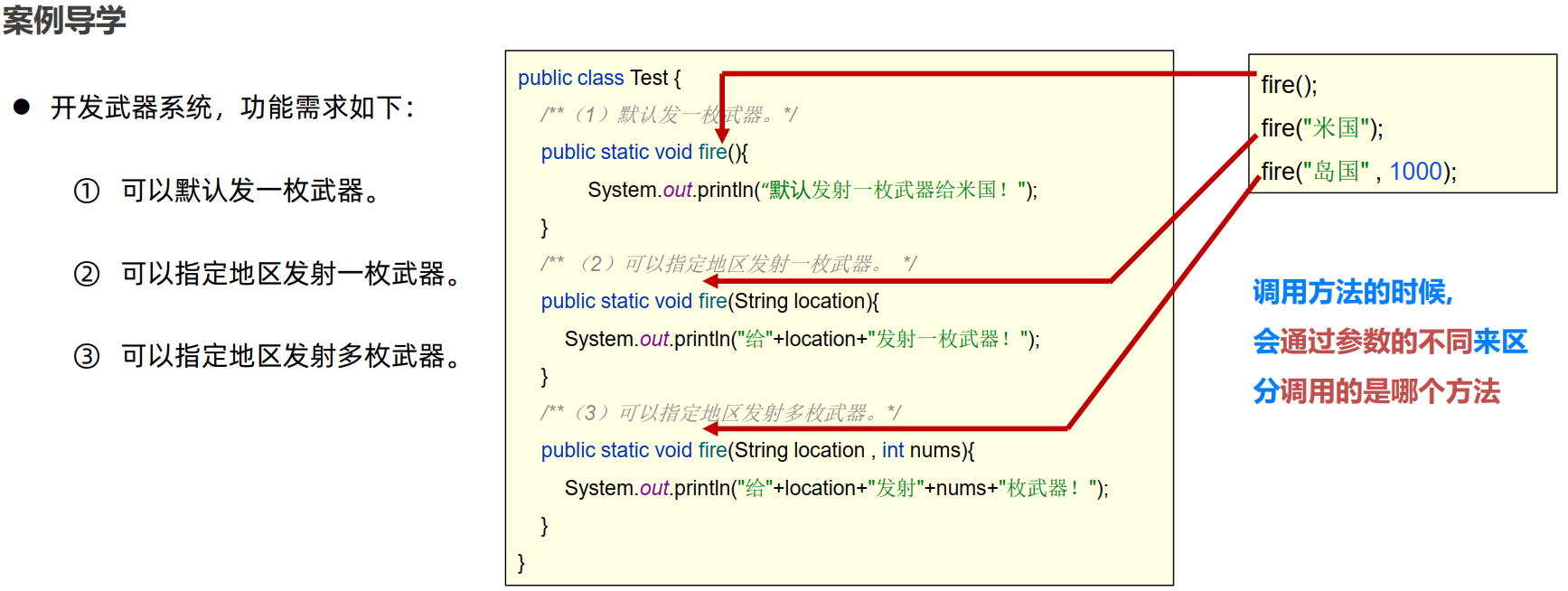
函数重载
定义
在C++中可以为两个或两个以上的函数提供相同的函数名称,只要参数类型不同,或参数类型相同而参数的个数不同,称为函数重载。
函数重载的依据是参数列表,即参数个数不同,参数类型不同
函数在编译的时候就确定了调用关系,即早期绑定
int my_max(int a,int b){return a>b?a:b;}
double my_max(double a,double b){return a>b?a:b;}
char my_max(char a,char b){return a>b?a:b;}
int main(){
int x=my_max(12,34);//在编译的时候,就识别出整型,小数,字符
double dx=my_max(12.23,9.12);
char ch=my_max('a','b');//识别出字符是因为通过定界符 ' '识别
}
名字粉碎技术
编译器在编译的过程中,进行了名字的重命名,参数类型成为名字的一部分,所以可以区分,可以重载
c语言名字粉碎技术只是在函数名前面加了下划线,而c++的名字粉碎技术将函数的返回类型,和形参类型作为函数名的一部分
c语言不能进行函数重载,c++有名字粉碎技术
#include<iostream>
using namespace std;
void func(int a);
void func(int a, int b);
int main() {
int x = 10;
func(x);
return 0;
}
错误 LNK2019 无法解析的外部符号 “void __cdecl func(int)” (?func@@YAXH@Z),函数 _main 中引用了该符号
@@YA c调用规则
X 无类型的缩写
H 参数类型的缩写
@Z 名字的结束
__cdecl c调用规则
__stdcall 回调调用规则
__fastcall 快速调佣规则
thiscall
C语言的名字修饰规则非常简单,_cdecl是C/C++的缺省调用方式,调用约定函数名字前面添加了下划线前缀,格 式:_functionname
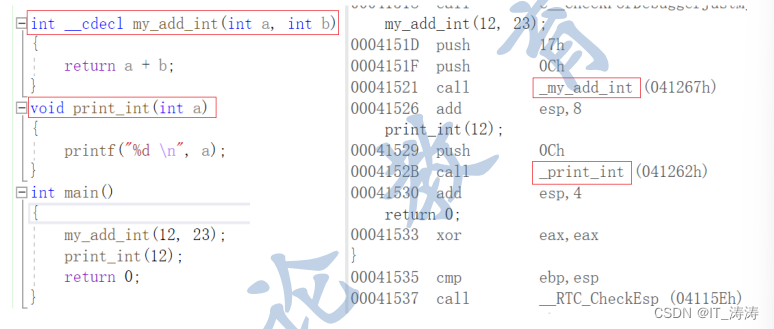
_stdcall调用约定在输出函数名前加上一个下划线前缀,后面加上一个"@“符号和其参数的字节数。格式: _functionname@number;
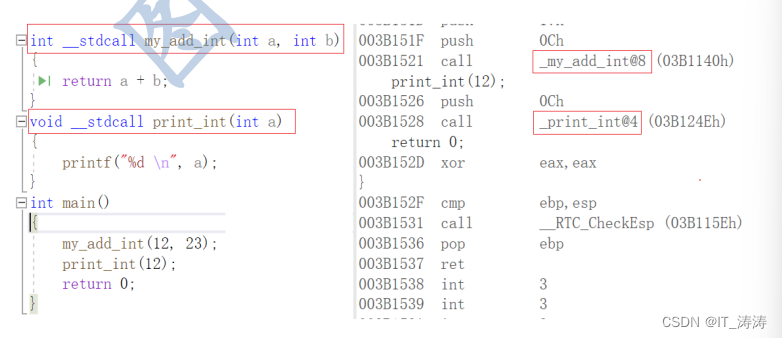
_fastcall 调用约定在输出函数名前加上一个”@“符号,函数名后面也是一个”@"符号和其参数的字节数,
格式为:@functionname@number
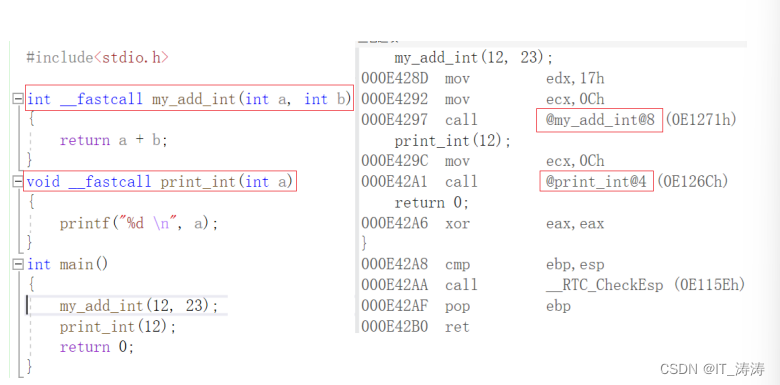
C++编译时函数名修饰约定规则
__cdecl调用约定:
1、以?“标识函数名的开始,后跟函数名;
2、函数名后面以”@@YA"标识参数表的开始,后跟参数表;
3、参数表的第一项为该函数的返回值类型,其后依次为参数的数据类型,指针标识在其所指数据类型前;
4、参数表后以"@卫"标识整个名字的结束,如果该函数无参数,则以"Z"标识结束。
//(?my_max@@YAHHHQZ)
int my_max(int a,int b);
//(?my_max@@YADDD@z)
char my_max(char a,char b) ;
//(?my_max@@YANNN@z)
double my_max (doub1e a,doub1e b);
int main(
{
my_max(12,23);
my_max('a', 'b ');
my_max(12.23,34.45);
return 0;
}
关键字:
extern “C” :函数名以C的方式修饰约定则;
extern "C++” :函数名以C++的方式修饰约定规则;
该编译无法通过
extern "C"
{
//_Add
int Add (int a,int b) { return a + b; }
//_Add
double Add(double a,double b)
{
return a + b;
}
}
这样就可以编译通过
extern "C++"
{
//
int Add (int a,int b) { return a + b; }
//
double Add(double a,double b)
{
return a + b;
}
}
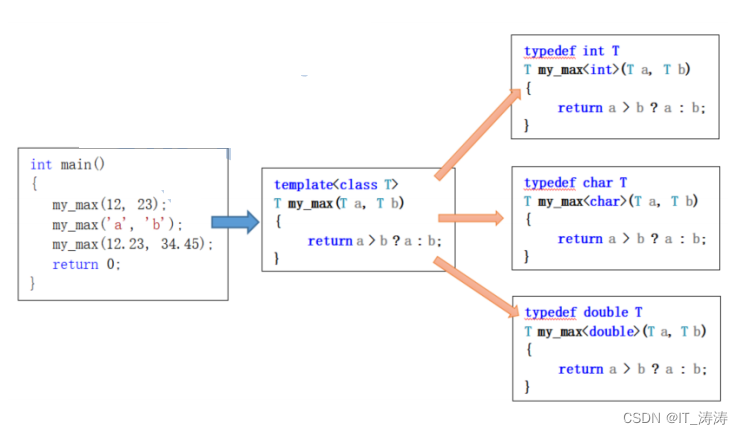
函数模板
把类型作为一个设计参数,根据函数实参,会推到一个新的函数,是在编译的时候产生的class和typename都可以
template<class T>
T my_max(T a,T b){
return a > b? a : b;
}
int main({
my_max(12,23);
my_max( 'a', 'b ');
my_max(12.23,34.45);
return 0;
}
注意:不是把T替换,而是类型的重命名
<>中的int就是让函数的返回值为int,必须要加返回值,后面也可以接参数,这样编译器就不用推导了
比如整型推导的函数为:
typedef int T
T my_max<int>(T a,T b){
return a > b? a : b;
}
函数模板根据一组实际类型或(和)值构造出独立的函数的过程通常是隐式发生的,称为模板实参推演(template argument deduction)。
template<class T,typename R,typename U>
T my_max(R a,U b){
return a > b? a : b;
}
int main(){
double c=my_max<double>(12,34.45);//
double c=my_max<double,int,double>(12,34.45);//这样我们就帮助编译器做了推导工作
return 0;
}






![[MySQL / Mariadb] 数据库学习-Linux中安装MySQL,YUM方式](https://img-blog.csdnimg.cn/9ff8e655589e4209986b04ed6a24cf10.png)